
Hi there! I'm Yuki Taguchi, and I joined LINE as anew graduate in April 2019. I currently work as a member of the Network DevelopmentTeam at our Verda Dept. Verda is a large-scale private cloud platform for LINEservices. Of the many tasks involving Verda, I'm in charge of developing itsnetwork components.
At LINE, in addition to network management based onspecialized hardware equipment, we're also focusing on software-based approachessuch as XDP and DPDK. The Verda Network Development Team works to improve thecompany's infrastructure mainly through this software-based approach.
The aim of this article is to give you a glimpse ofwhat working as a new graduate infrastructure engineer at LINE looks like. Init, you'll read about our efforts to support our infrastructure platform,through performance measuring, and quality maintenance of our network software.
Maintaining the performance of our software-basednetwork platform
First of all, to give you some background on my job,I'd like to touch on the situation and issues surrounding Verda.
Since its release in 2017 as a private cloudplatform, Verda has enjoyed rapid growth. In the past year, for example, itsnumber of VMs has more than doubled, and a wide variety of services, includingour own messaging service, have been deployed on it. This led to calls for afast and flexible platform that could keep pace with the speed at which theseservices are developed.

To address these needs, Verda's network proactivelyadopts a software-based approach.
For instance, Verda provides LBaaS (Load Balancer asa Service) feature. For this feature, the Network Development Team customizes theLayer 4 load balancer's entire data plane. In implementing the data plane, weuse XDP, a Linux kernel feature, for acceleration.
LINE provides a diverse set of services, which makesmultitenancy a must. To provide this multitenant environment, we use a novelrouting technology called SRv6. SRv6 is so new that there were fewimplementation cases at other companies, and we could barely find any hardwareproducts to support it. The paucity of resources led us to use the SRv6 softwareon the Linux kernel, which runs on general purpose servers. This is just oneexample of how we work to improve management flexibility by softwarizing theimportant components of Verda.
Verda is a platform that mediates the massivetraffic generated by LINE services, so its software's forwarding performance iscrucial, and must be maintained at all times. To address this requirement, regularbenchmarks that allow for a consistent understanding of actual softwareperformance, therefore, are essential.
This is actually easier said than done. Manuallybuilding a test environment for every benchmark comes with its own challenges,such as misconfigurations and discrepancies between environments, depending onwhich resources are available at that particular time. There is no way forresults of benchmarks running under such inconsistent conditions to beaccurately compared, which means that performance deterioration could sneak itsway into the software in the course of development and go unnoticed.
When I joined the team, there wasn't yet aconsolidated benchmark system, and these issues were far from being properlyaddressed. We eventually arrived at the conclusion that we needed to rundeclarative benchmarks in a common environment using CI (Continuous Integration)and set out to create an automation system for this purpose.
Automated testing and benchmarking of load balancers
The first task I was assigned was to automate unittests (function tests) and benchmarks (performance tests) for load balancers,and to present the results so that they could be easily understood by loadbalancer developers in my team. Verda's load balancers are implemented usingsoftware, so their unit tests, like those for typical server applications,could be easily automated using a CI tool called Drone. With performancebenchmarks, however, things were not so simple.
Verda's load balancers are based on XDP and theirpacket processing are executed in a physical NIC (network interface card)driver context. Because of this feature, the load balancers are running on abare metal server, not a virtual environment. This means that they can't be benchmarkedas virtual machine or container forms. So, we needed to prepare a specializedphysical environment.
There were other things to consider as well, forinstance:
- How to generate high-rate traffic
- How to automatically configure test environments
- What kinds of benchmark scenarios to test.
To resolve these issues, I, respectively:
- Used a software-based, high-speed traffic generator
- Automated configuration using provisioning tools such as Ansible
- Created benchmark scenarios considering the load balancer’s characteristics as well as baseline measurements
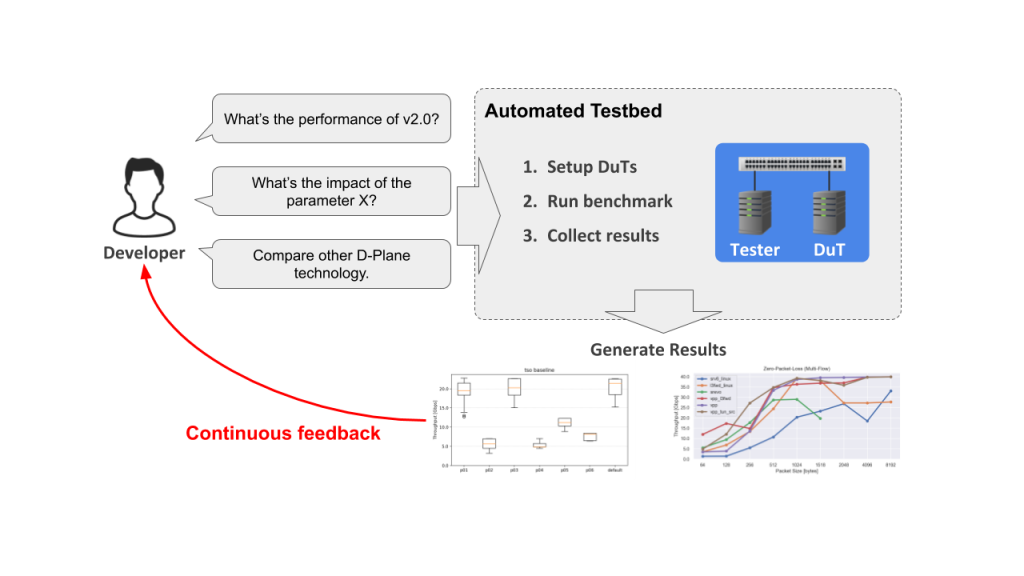
These approaches were baked into the design of our automationsystem. In this system, a CI tool (Drone CI) triggers the provisioning of thededicated testbed using Ansible, and a high-speed traffic generator called TRexis used to measure the performance.
Here's an overall look at the completed system:

When I added a benchmark scenario, I did it in closeconsultation with the load balancer developers. There was, at the time, concernthat a new feature of the load balancer might cause performance to declineunder certain traffic patterns. We added a new traffic generation program thatmimicked these conditions and passed the test results on to the load balancerdevelopers. The task of actually adding the benchmark scenario was quite easy.Because the benchmark environment had already been completed, all we really hadto do was create a new traffic generation program and add it to the tester. Allthe other redundant tasks (e.g., provisioning of switches and servers) hadalready been automated!
In designing the benchmark, we came acrossmeasurement difficulties unique to load balancers. The load balancers used inVerda, by specification, use IPIP tunneling, in which ingress and egresspackets have different structures. This means that the actual structure of thepackets collected by the receiving side of the traffic generator differs fromthe structure it expects, which can be problematic. To address this issue, wetweaked the traffic generator program so that only intended packets werecounted by the NIC hardware, with the rest counted by software.
Now, when new pull requests are created on the loadbalancer's GitHub repository, the benchmark is run automatically in itsspecialized testbed, and its results will be submitted to the pull requestpage.
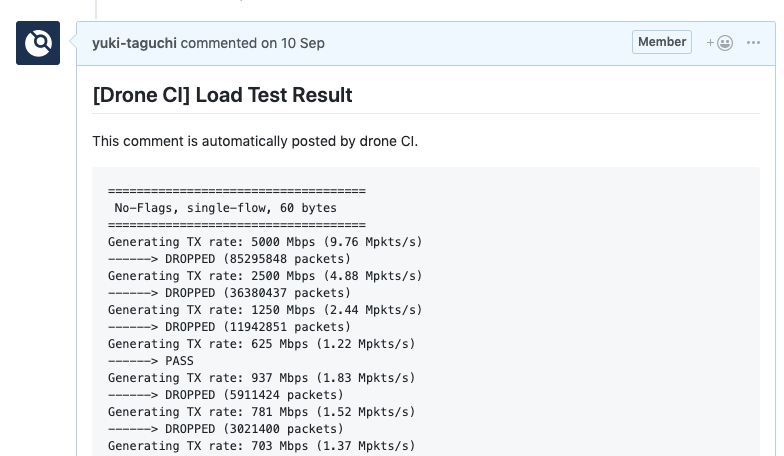
This system provides load balancer developers withan objective understanding of the performance even during the development phase.There's still room for improvement, however. With regard to visibility, we'reconsidering presenting data as charts, and making it easier to compare past andpresent performance. We're also thinking of adding features supplemental toperformance analysis (e.g., one that can show you which process took up howmuch CPU cost). Through further enhancements, I hope to enable a faster andmore accurate development flow for our Network Development Team.
A path toward agile network development
Through my experience, I learned that automatingbenchmarks comes with a host of advantages. One of them is that declarativebenchmarks that are automated using Ansible are highly reproducible, and allowingone to get the same results regardless of who runs the tests. Another advantageis that automated benchmarks make it easy to try out parameter changes ondemand.
In addition, as introduced in the LBaaS example, thegood use of CI tools allows network software to naturally incorporate benchmarkinto the development flow, just like any other typical applications. Thisallows for the prevention of unintended performance deterioration.
In a more recent project, I automated a benchmarkfor a new SRv6 implementation using XDP.
This new SRv6 implementation was developed by our then intern, Ryoga Saito, as part of the team's ongoing efforts to accelerate our multitenant environment. (You can read more about these efforts in a separate blog post, available in Japanese only)
This automated benchmark system can benchmark newand existing SRv6 implementations in the same environment, and even generate aperformance comparison chart. It enables us to objectively compare the SRv6data plane performance, making it easier to determine whether heavier workloadscan be applied to Verda. The tests can now be run on demand, providingcontinuous feedback to developers of network functions so that they canpromptly make improvements.
In the course of developing this system, we againencountered challenges unique to network software. For example, measurementresults would be different for every test we ran. There are many possible causesfor these discrepancies—such as inconsistent cache status and CPU coreallocation problems—so we had to investigate each one every time, andreconsider our test settings. We continuously updated the benchmark itself inthis way to improve the reliability of our measurement data.
Working at the Verda Dept.
So far, this article has been about projects that I havebeen personally involved in. I'd now like to move on to tell you about mysurroundings. The Verda Dept. is made up of many teams in addition to mine,including one that manages cloud platforms such as OpenStack and Kubernetes,the storage team, and UI team. We have multiple locations, in Tokyo, Fukuoka,Kyoto, and also in South Korea. Some teams have members across differentlocations, often with varying native languages, and so mostly communicate inEnglish.
I myself try my best to create tech docs andcommunicate on GitHub in English. As for live English conversations, this issomething I need, and definitely plan to work on, because the ability tocommunicate directly in English often lets you interact smoothly with thoseoutside the team.
Verda office members also actively attend andparticipate in technical conferences and open source communities. Networktechnologies used in LINE, like SRv6, are state-of-the-art, which means thatfeatures to support them have only just been implemented by equipment vendors,or are still in their testing phase. This makes knowledge gleaned from our day-to-daywork all the more valuable, so our presentations gain a lot of attention.
The Verda office makes information regarding thetechnologies and architectures we adopt as open to the public as possible. Infact, the data plane/control plane and LBaaS technologies used in the Verdanetwork have already been introduced at major conferences, including JANOG. Ifeel very lucky to be able to work in an environment where I can stay inspired,not only by my fellow teammates but by those outside the team as well.
Wrapping up
Because the automated test/benchmark systemsdescribed in this article are flexibly designed to accommodate new testsubjects, I'm confident that they will continue to be used to test theperformance of new technologies and greatly mitigate the workload of networkdevelopers.
It's been approximately six months since I joinedthe Network Development Team. Tasked with the important job of continuouslymaintaining the quality of our cloud platform, I find my work extremelyrewarding.
As a final note, I hope the efforts at our Verdaoffice and the projects mentioned in this article pique your interest in Verda networkdevelopment. For more information on our other projects, please check out themany tech conference documents LINE has made available to the public (I've provideda list of some of our more recent presentations below).
Thank you for taking the time to read this post!
- Software engineering that supports LINE-original LBaaS
- Next Data Center Networking with SRv6 (available in Japanese only)
- Faster SRv6 D-plane with XDP (available in Japanese only)