
In the Team & Project series, each department and project in LINE's development organization is introduced in detail, including their roles, structures, technology stacks, future issues, and roadmaps. This time, we will introduce the team that is working on Site Reliability Engineering (SRE) for Verda, which is LINE's private cloud.
We spoke with Park Youngwoon, Hideki Yamada, and Kang Moon Joong of the Verda Reliability Engineering team.

-- First of all, please introduce yourself.
Park: I am the manager of the Verda Reliability Engineering Team (VRE), whose mission is to perform SRE activities for Verda, the private cloud of LINE. The VRE team is based in Japan and Korea, and I manage both of them.
Yamada: I am working as a senior engineer in the VRE team. Many technology are used in the development and operation of cloud infrastructures, and among them, I mainly perform SRE for relatively low-layer parts, such as servers and OS. Specifically, our main missions include troubleshooting at the OS level, managing the capacity of cloud resources, and improving operations related to the procurement of physical resources.
Kang: I joined the Korean side of the team as a new graduate in 2019. Prior to joining the company, I worked in a university lab, and I am using that experience to develop and operate system monitoring for Verda as a whole.
-- Please tell us why you all joined LINE.
Park: In my previous job, I was working as a manager of development and operations in the IaaS domain at a company that provides public cloud services. However, I felt distant from the users, plus I wanted to gain development experience outside of the IaaS domain, so I decided to join the Verda team, which provides a wide range of layered services to internal developers as a private cloud.
Yamada: In my previous job, I was a member of a corporate research institute, where I was mainly engaged in research and development of cloud services for group companies. In a research environment, I wasn't able to work on the entire cycle from development to actual operation, so I decided to join the Verda team because it allowed me to work on the development and operation of services close to the users, and the required technical skills matched my area of expertise.
Kang: My major at university was cloud computing, and I had been eyeing LINE as a company in Korea that would allow me to work in that field. In particular, the work of the VRE team aligned with my specialty, so I decided to join the company after my internship. What impressed me most about my internship experience was that I was able to take the initiative in discovering and solving problems. I received a lot of feedback from the team members on my efforts, and I felt engaged at work, which was key to my decision to join the company.
-- What is the most rewarding aspect of working at LINE?
Park: I find it rewarding to be in an environment where I can actively challenge large-scale infrastructures with the important goal of reliability. In addition to IaaS, Verda also provides managed services, such as container-based PaaS and DB. While specialized and in-depth knowledge and experience are required for SRE activities for each service, breadth of knowledge and experience is important for improving the operation system across services and developing standard systems. On the other hand, I am in a position where I can move relatively freely and take on many different kinds of challenges, so I find that part of the job very rewarding.
Yamada: There are many jobs where the system I developed, or even a single line of code I wrote, has an impact on the entire large-scale infrastructure environment, and I find it rewarding to see the huge impact of the work I was involved in. Also, since the users are internal developers, it is easy to get detailed feedback, which naturally leads to faster development and improvement. There are not many products in the field of infrastructure that have a development cycle as short as Verda's (laughs).
-- Please tell us about the composition and roles of the team.
Park: The team is divided into two locations, Japan and Korea, with five members in Japan and three in Korea, for a total of eight members. As for the responsibilities of the team, I will explain it in a diagram since it is complicated. The work that is being carried out by VRE today can be broadly categorized into the following three types.

Customer Reliability Engineering is rotated among the team members, but the roles of reliability engineering, monitoring, and development of the deployment system for the IaaS domain are roughly assigned to each team member. With respect to IaaS, there are more than 60,000 VMs, and close to 20,000 physical servers used for Baremetal, Hypervisor, and Storage in service, and the cost of their operation is enormous. Reducing this cost through automation and stabilization is an important mission for VRE. Also, since the services to be monitored or deployed and the resources that they use are quite large, we are trying to reduce the costs of management and of implementing functions for developers by unifying the system as much as possible. VRE has been consistently providing primary support to internal users and Solution Architect-like activities. Technical solutions are actively incorporated, such as reducing the cost of support by developing a function to send a direct message to the developer on a specific topic, or creating a system to automatically check the connection for inquiries like, "I can't connect to the VM." There is still a lot of room for advancement in this field.
Yamada: The division of roles for the above categories is not clear-cut for the individuals, and most of the members work across multiple domains. For example, I am committed to multiple areas, such as improving Baremetal setup procedures and developing and operating resource monitoring methods. It is more accurate to think about where each member's area of expertise is mapped to rather than thinking of the roles being clearly divided and assigned.
Kang: I am also committed to both SRE for the Storage service and the development and operation of the cross-service monitoring infrastructure. Additionally, I am actively involved in CRE activities through projects to improve server maintenance and service failure notification.
-- Please tell us about the technology and development environment you use.
Park: The relationship between Verda users, Verda developers, and us can be summarized as follows.
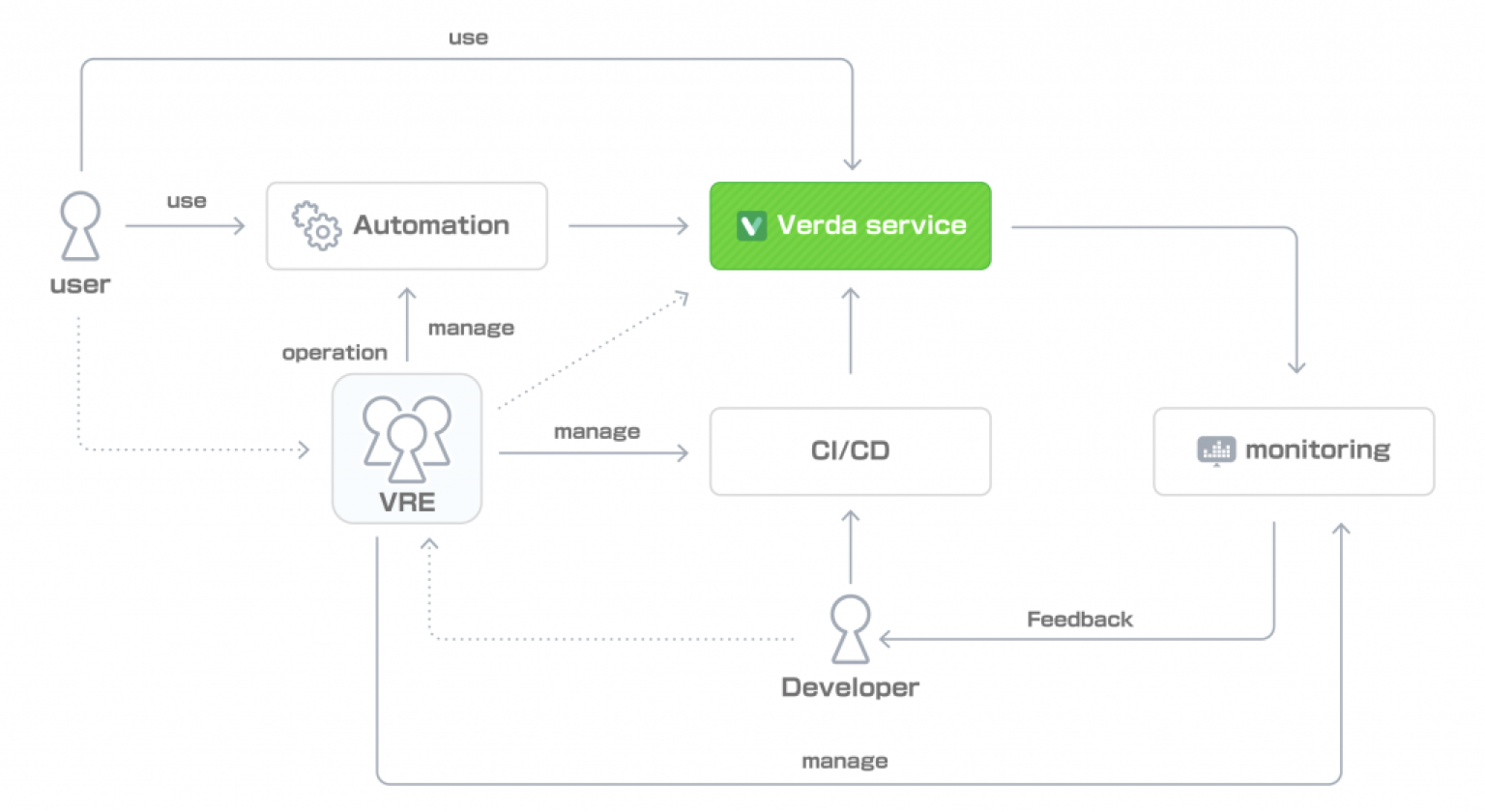
In this diagram, there are three areas that we are responsible for developing and operating: Operation Automation System, CI/CD, and Monitoring. Actually, it is more complicated than that, but since this is an interview article, I have kept it simple.
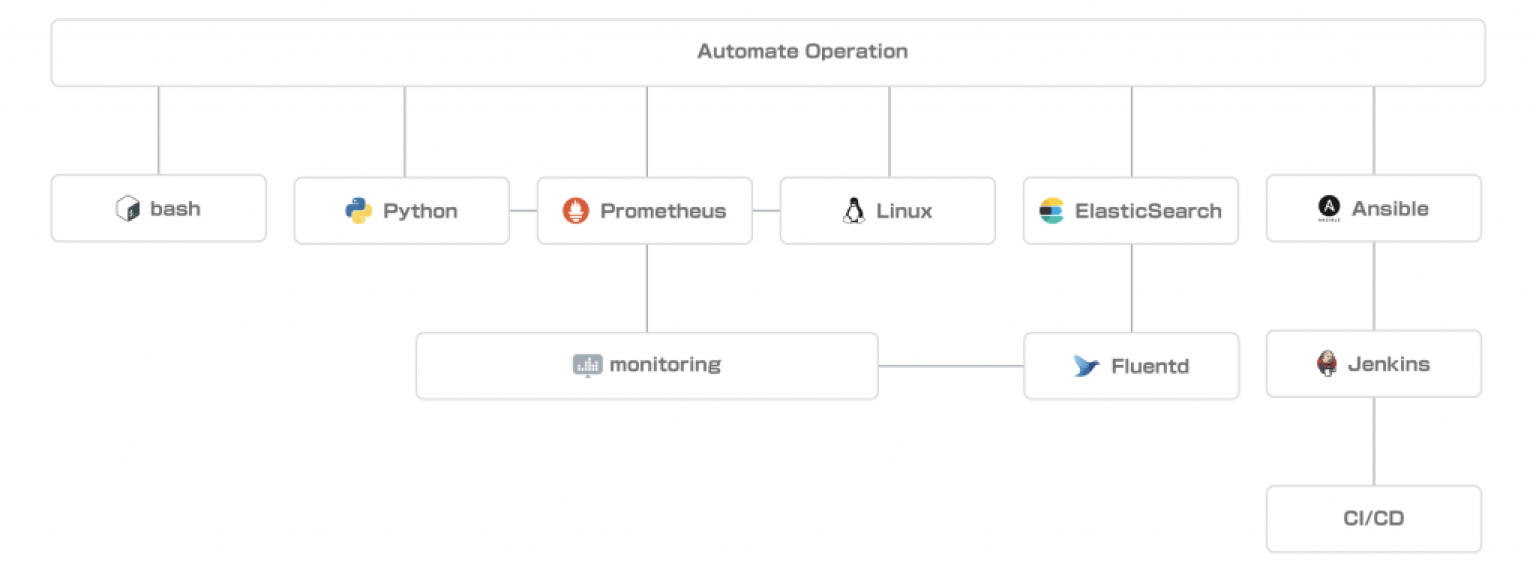
I will start off by explaining CI/CD simply. We use Ansible extensively for server configuration management and service deployment. We have developed modules to improve readability and stability and implemented event-driven Ansible execution by introducing execution platforms, such as AWX, so we feel we are using Ansible quite extensively.
For deployments and history management, we are currently using Jenkins, but since we are doing many manual operations, we are trying to sort out new requirements and consider alternative methods.
For operations automation, we often use Python. We write simple scripts and develop intermediate services with interfaces to simplify complex operations and provide them to users and developers.
Requests from users are basically received via Slack, and we are working on improvements to provide a more user-friendly interface by using bots.
As for monitoring, we are using standard technologies such as Prometheus for metrics management and Elasticsearch + Kibana for log management. Especially for Prometheus, we are actively developing our own exporters to monitor more detailed status of service processes and middleware. We use Go and Python for development. For services with Web APIs, we use API specs based on OpenAPI (swagger) to get Prometheus-style metrics, which have been implemented in various services.
Incident information is aggregated via Alertmanager to an external incident management and notification service called PagerDuty. We are also developing an event-driven recovery flow, such as by executing an automatic recovery playbook and issuing webhooks to AWX from the same Alertmanager.
Yamada: We often use Bash and Python to implement tools to facilitate operations. Python in particular is easy to use and works well with OpenStack and Ansible, so I use it frequently. I also use Bash to implement scripts using the CLI of each service, so coding skills are required in one way or the other.
-- Please tell us about your current team issues and what you are doing to solve them.
Park: In the IaaS domain, one of the major challenges is the high usage of Baremetal.
In our company, there are many use cases that emphasize the upper limit of performance and stability of computing power, and the migration to VMs has not progressed very well. VM and Baremetal differ in their management methods in many ways, and the operational costs associated with Baremetal are particularly high, so the high usage of Baremetal leads to high overall operational costs.
We are currently trying to encourage users to migrate from Baremetal to VMs through projects, such as developing VM types with strict resource isolation to handle use cases with strict performance requirements and reducing the usage cost per VM by scheduling VMs efficiently.
The monitoring and deployment areas are still in the early stages of development, so there are very few areas that are not being addressed. The final scope of work, such as improving the monitoring system across services and streamlining the deployment mechanism, is very large, so we are moving forward step by step, starting with those areas that are most likely to be effective.
As for SRE activities for individual services, there are many areas that cannot be covered by VRE because they require deep expertise in virtualization and networking. I am not sure how to proceed with these projects since they need to be balanced with my other duties.
I feel that we lack the manpower to proceed in a balanced manner, so we are focusing on recruitment.

Yamada: We are working to improve some inefficiencies in operations that require cooperation with other departments. For example, when adding servers, it is necessary to collaborate with the data center and the department that manages the configuration management DB, but in the series of workflows, such as rack management, server installation, asset registration, registration to operation tools, BIOS setting, RAID setting, registration to automatic OS installer, registration to private cloud, and user management, each task is divided into different departments and there are gaps in the workflows. Although the individual tasks are mostly automated, the tasks are not well coordinated, and there is a limit to the efficiency improvement in this situation.
Currently, we are working on a VRE-led project to organize a series of workflows and linkages between tasks and automate all of them, with the aim of solving this problem.
In the context of automation, in addition to organizing workflows among teams, we also routinely carry out activities to standardize and automate operations that occur on a daily basis. However, if we reduce the time we spend on operations because of our improvement activities, it will slow down our operations, so one of our challenges is how to strike a balance between the two.

Kang: As long as we are developing and operating cloud services, it is our job to deal with problems that occur on physical machines and networks. It is important for us to properly contact users with a good understanding of which type of cloud resources will be impacted and which users and LINE services will be affected by a particular incident. Therefore, one of the missions of VRE is to create a notification method that is easy for users to understand. Right now, we feel that the UX of the contact method is still underdeveloped, so we are working on a project mainly organized by the Korean members to improve it.

-- What is your roadmap for the future?
Park: We are aiming to Verda-ize all of LINE's infrastructure in the future. Therefore, we are placing a high priority on improving and developing Verda so that LINE developers can use it with confidence. Our short-term roadmap is as follows;
- Establishing processes to guarantee the visualization and reliability of systems in the SLO/SLA definition of the SaaS hosting services currently under development
- Infrastructure design to operational design for providing a standard infrastructure base for services with special requirements, such as Healthcare/Fintech
- Implementation of OCP (Open Computing Project) to reduce and optimize the management cost of physical servers
- Standard monitoring system development and process establishment
- Platformization of admin management tools
- Common development process (CI/CD)
- Ceating a system to strengthen CRE/SA Activity.
Over the long term, I'd like to work on improving scalability. Our goal is to make it possible to manage LINE services and infrastructure with Verda, even if the scale increases by 10 or 100 times the current scale.
-- Finally, do you have any messages for those who are interested in joining the Verda Reliability Engineering team?
Park: The mission of the Verda Reliability Engineering team is to ensure that LINE developers can use Verda reliably. LINE has a variety of services, and improving the reliability of the infrastructure used for those services will ultimately benefit countless users, so this is a very challenging mission. If you are attracted by the background and scale of the mission, and if you are fascinated by working in the role of SRE across various services and specialized areas, we would love to have you join us. Our team members are not just cloud professionals, but people with various backgrounds. If you are interested, please feel free to come and talk to us!
Yamada: If you are thinking, "I want to see infrastructure and write code!" this is the place for you. These days, the term infrastructure engineer often refers to someone who uses the cloud, but if you want to be someone who creates the cloud, please come to Verda.

The Verda Reliability Engineering team is looking for new members.
- Cloud Platform Site Reliability Engineering (Link in Korean)
- ソフトウェアエンジニア / SRE / Private Cloud Platform (Link in Japanese)