
What is Reactive Streams?
In this post, I'd like to introduce the basic concept of Reactive Streams, and how to use Reactive Streams with Armeria, the open-source asynchronous HTTP/2, RPC, REST client/server library. Let's begin by examining what Reactive Streams is.
The official homepage of Reactive Streams defines it as follows.
Reactive Streams is a standard for asynchronous data processing in a streaming fashion with non-blocking back pressure.
Let's take a closer look at what they mean by "processing in a streaming fashion," "asynchronous," "back pressure," and "standard."
Stream processing
The figure below compares traditional data processing against stream processing.

The traditional method of data processing depicted on the left requires the payload to be stored on an application's memory once there is a data processing request. Any additional data that may be required must also be looked up and stored on memory. The problem with this method is that all data that is received or looked up must all be stored on the application's memory in order to generate a response message. If the size of the required data is larger than the available memory, an "out of memory" error will occur. Even if a single request doesn't cause an "out of memory" error, there are many instances while operating a service where there will be many requests coming in at once. When there are multiple requests occurring simultaneously, it will trigger a large amount of GC (garbage collection) in a short amount of time, leading to the server failing to respond normally.
On the other hand, you can use the stream processing method to process large amounts of data even with a small amount of system memory. With stream processing, you can create a pipeline that subscribes to any incoming data, processes the data, and then publishes it. Server processing data with this method will be able to process large amounts of data elastically.
Asynchronous method
Let's compare the asynchronous method with the synchronous method. The figure below depicts the processes of both methods.

In the synchronous method, a request sent by the client is blocked until the server sends a response. Being "blocked" means that the current thread cannot perform another task and must wait. If two requests are sent to servers A and B, the request must receive a response from server A before it can move on to server B. However, with the asynchronous method, the current thread is not blocked and can perform other tasks while waiting for a response. The thread can be used for other tasks after sending a request to server A, or send a separate request to server B. The advantages of the asynchronous method compared to the synchronous method are as follows.
- Fast speed - You can get quicker response speeds by sending two requests simultaneously.
- Less resources used - You can process more requests with less threads as threads can perform tasks in parallel without being blocked.
Back pressure
Before we go into more detail about "back pressure," let's take a look into the observer patten, push method, and pull method made famous by RxJava.
Push method

In an observer pattern, a publisher transfers data by pushing it to a subscriber. A subscriber is not concerned with what state the subscriber is in, and is only concerned with transferring data. If the publisher sends 100 messages in the span of 1 second, and the subscriber can only process 10 messages in 1 second, what will happen? The subscriber will have to store the pending events in a queue.

The amount of memory allotted to the server is limited. If 100 messages per second is sent to the server, the buffer will fill up instantly. What would happen if the buffer runs out and causes an overflow? Let's see what would happen to a static buffer and a variable-length buffer.
- Static buffer: Newly received messages are rejected. Rejected messages will send requests again, which will cause additional processing load on the network and CPU.

- Variable-length buffer: The server will crash with an "out of memory" error while trying to store the events. While you might think "who would make it like this?", the data structure of Java
lists are variable-length. For example, when querying for a large amount of data with SQL, DBMS is the publisher and your servers become subscribers. When your servers attempt to store all the data in alistdata structure, it will trigger a large amount of GC, preventing your server from responding normally.
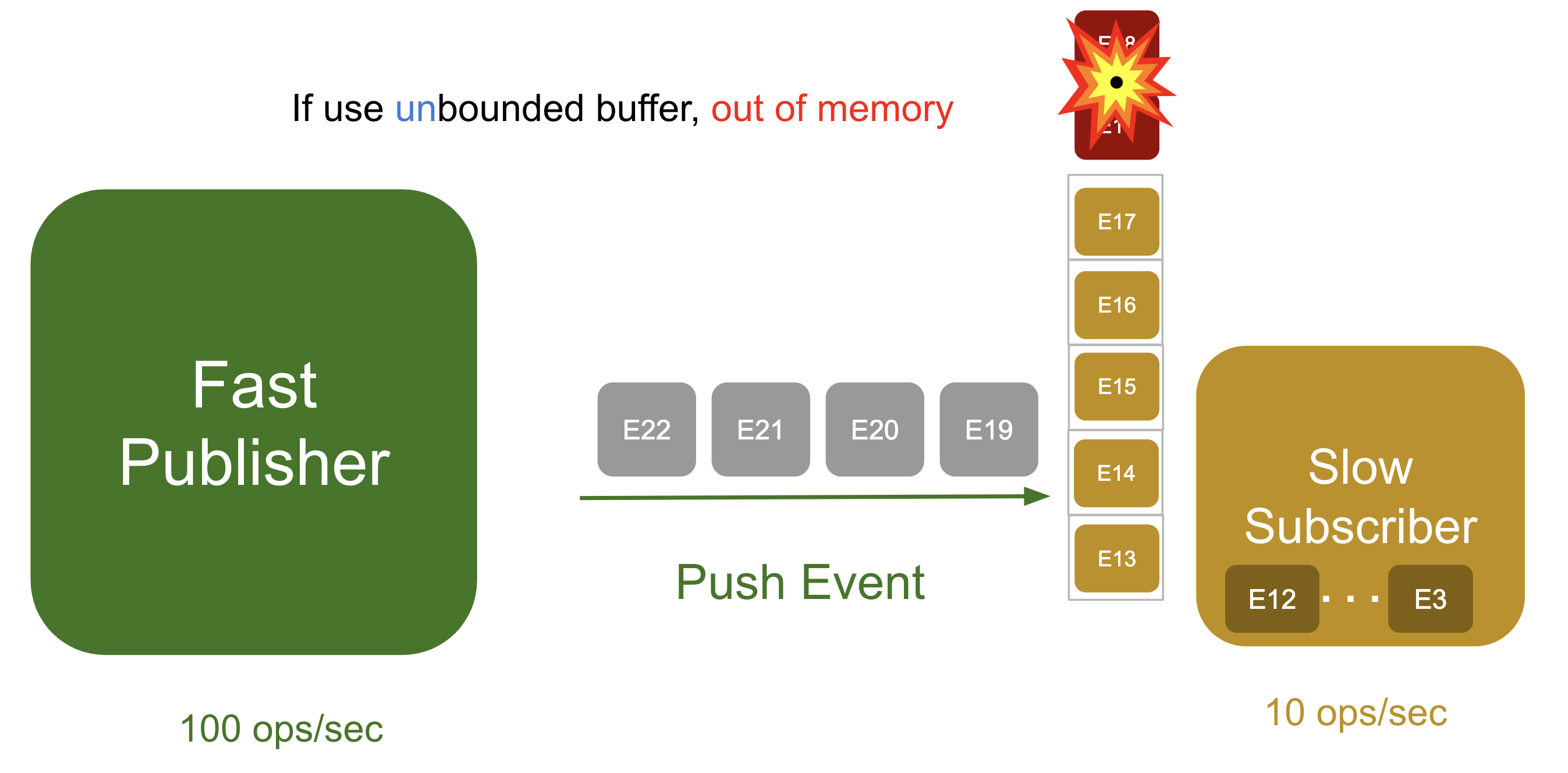
How can we solve this problem? Could we solve it by having the publisher only send an amount of messages that the subscriber can handle? This is the fundamental workings behind back pressure.
Pull method
With the pull method, a subscriber that can process 10 operations at a time will only request 10 operations to the publisher. The publisher can then send the requested amount, and the subscriber is safe from any "out of memory" errors.

Furthermore, if the same subscriber is currently processing 8 operations, it can request 2 more operations so that the number of messages do not exceed the limits of what it can process. With the pull method, subscribers have the freedom to choose the size of the data they receive. The method that allows subscribers to dynamically pull data requests within their capacity is what back pressure is.
Standardization
Reactive Streams is a standardized API. Here we'll talk about why standardization was necessary and how it became standardized.
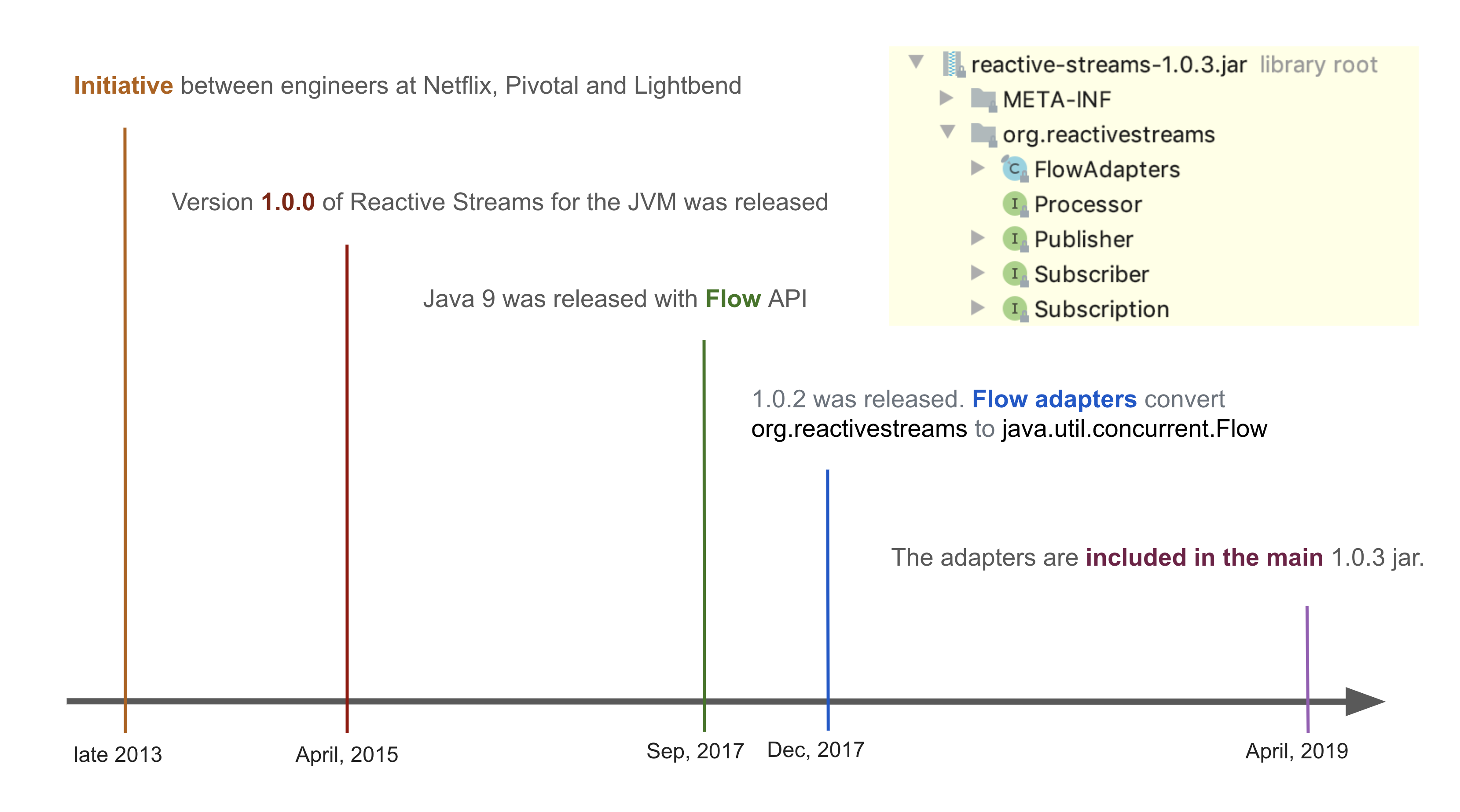
Development for Reactive Streams first started in 2013 by engineers from Netflix, Pivotal, and Lightbend. Netflix is responsible for the development of RxJava, Pivotal for WebFlux, and Lightbend for Akka, an implemntation of distributed processing actor models. What these companies had in common was that they all required streaming APIs. However streams are only meaningful if they combine and flow organically. For data to flow uninterrupted, these different companies needed to use shared specifications, or in other words, they needed standardization.
During April, 2015, Reactive Streams has released its 1.0.0 specifications that can be used on JVM. In September, 2017, Java 9 added Flow API, which includes the API, specs, and pull method of Reactive Streams and packaged it under java.util.concurrent. Reactive Streams, which was a shared effort between community members and a few companies, has been officially recognized and added as an official part of Java. Three months later, Reactive Streams released an adapter that is compatible with Flow, allowing existing libraries to be used.
Reactive Streams API
Reactive Streams may look complex and daunting on the surface, but its internals are made up of a combination of simple APIs.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}Publishersonly have asubscribeAPI that allowssubscribersto subscribe.SubscribershaveonNextfor processing received data,onErrorfor processing errors,onCompletefor completing tasks, andonSubscribeAPI for subscribing with parameters.- For
subscription, there is arequestAPI for requesting data and acancelAPI for cancelling subscriptions.
Now let's take a look at how the API above is used in Reactive Streams.
1. A subscriber uses the subscribe function to request a subscription to the publisher.
2. The publisher uses the onSubscribe function to send the subscription to the subscriber.

3. The subscription now acts as a medium between a subscriber and publisher. Subscribers do not directly request data from publishers. Requests are sent to publishers using the request function of the subscription.
4. The publisher, using subscription, sends data with onNext, onComplete for completed tasks, and onError for errors.
5. The subscriber, publisher, and subscription all form an organic connection, communicating with each other; starting from subscribe all the way to onComplete. This completes the back pressure structure.

So back pressure seems useful, but how do you actually use it? The interface you see above is all of Reactive Streams API available on its official GitHub repo. There isn't a separate implementation that you can use.
Then can you implement it by yourself? You can in fact implement a publisher interface and generate a subscription using the rules above. However, this is not all. Reactive Streams comes with its own specifications, and unlike a simple interface, these specifications present rules that must be followed during implementation.
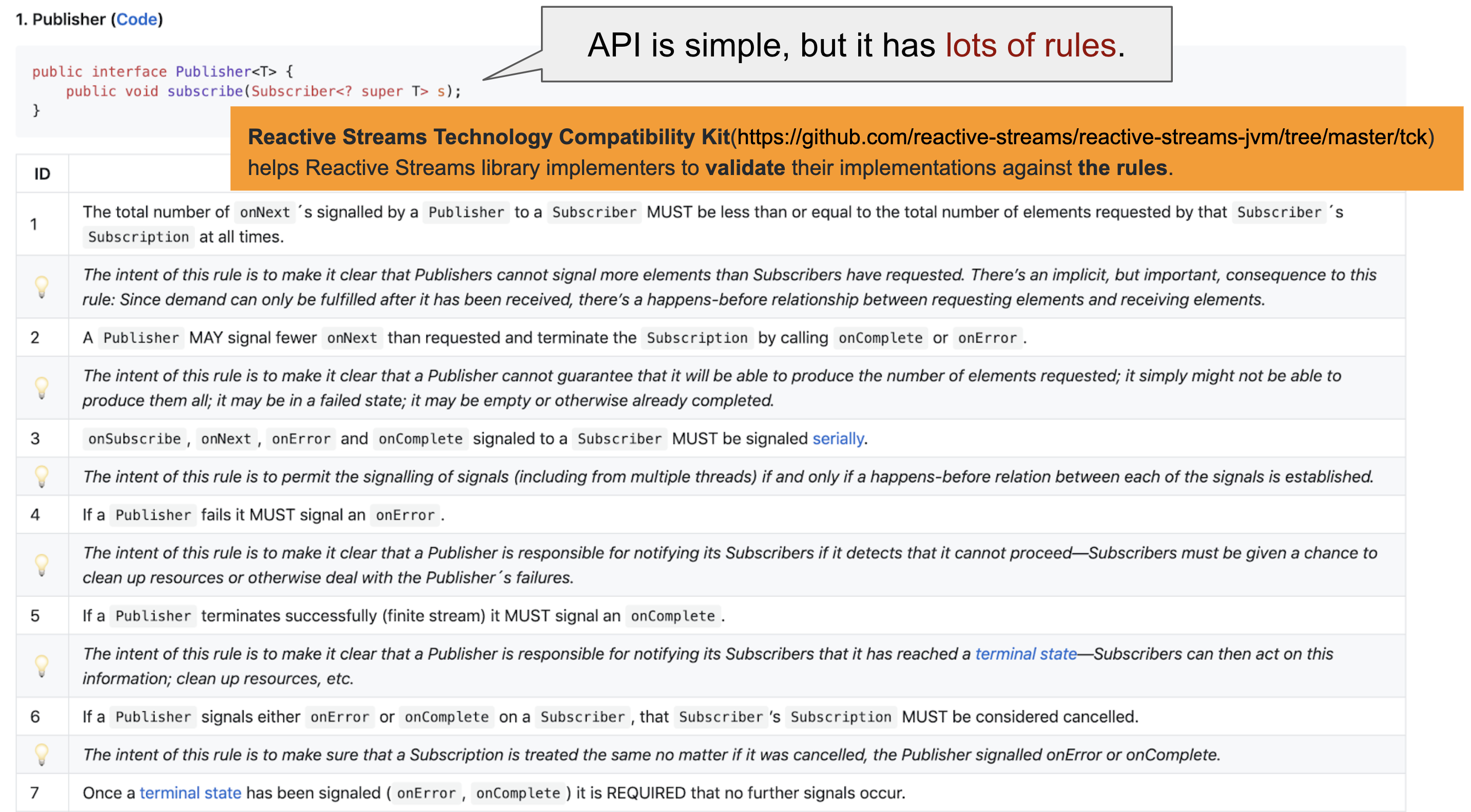
Once you follow the specifications and have an implementation, you can validate it using a tool called Reactive Streams TCK. Unless you're a skilled expert in the field, it's difficult to have an implementation that satisfies all of the given rules. The publisher in particular is especially difficult to implement. For example, here's an issue posted on the GitHub repo of Project Reactor, one of the more well known Reactive Streams implementations. The user in question is having difficulty in connecting their publisher to Flux. The reply from Project Reactor was basically "don't." In my opinion, it's okay to do something like this in a pet project for study purposes. You should not, however, use unverified code in an actual service. Instead, you should create a publisher using a constructor function such as Flux.create(). It's better off to use an existing, validated implementation when using Reactive Streams, rather than creating one yourself. So what are some implementations that you could use?
Reactive Streams implementations and interoperability
There are various Reactive Streams implementations that you can use. Each implementation has its own quirks and characteristics, so you should find one that fits your needs.
- If you only need stream computing processing you could use RxJava, Reactor Core, or Akka Streams.
- If you want to look up data in repositories using Reactive Streams, you could use ReactiveMongo or Slick.
- If you need something connected to web programming you could use Armeria, Vert.x, Play Framework, or Spring WebFlux.
All these different implementations can communicate each other through Reactive Streams.
Interoperating Reactive Streams

Observable in RxJava can be converted to Aremeria's HttpResponse or Project Reactor's Flux through Reactive Streams. MongoDB's DataPublisher can stream compute through Akka Streams' Source.
For example, let's say you're looking up data and computing on MongoDB and then sending it as an HTTP response. Using Reactive Streams to look up data on MongoDB will return publishers that can be subscribed to. Unless a subscriber sends a request through a subscription, any actual data is not transferred.
// Initiate MongoDB FindPublisher
FindPublisher<Document> mongoDBUsers = mongodbCollection.find();As you can see in the code below, using Observable's fromPublisher, you can connect to MongoDB's FindPublisher. Using the map operator allows you to extract the age field from the results.
// MongoDB FindPublisher -> RxJava Observable
Observable<Integer> rxJavaAllAges =
Observable.fromPublisher(mongoDBUsers)
.map(document -> document.getInteger(“age”));Since RxJava's Observable is implemented in an observer pattern, converting it for Reactive Streams requires the use of the toFlowable function as you can see in the code below. After the conversion, you can connect RxJava's Flowable and Flux using the from function.
// RxJava Observable -> Reactor Flux
Flux<HttpData> fluxHttpData =
Flux.from(rxJavaAllAges.toFlowable(BackpressureStrategy.DROP))
.map(age -> HttpData.ofAscii(age.toString()));To use Flux data structure in HTTP responses, you must append an HTTP header to the front of the data. You can then call HttpResponse.of to connect it with Flux and then use it as an HTTP response for Armeria.
// Reactor Flux -> Armeria HttpResponse
HttpResponse.of(Flux.concat(httpHeaders, fluxHttpData));As previously mentioned, it's important to note that unlike typical iterators, any computing has not occurred yet in this process. We have only illustrated how the data will be sent to the subscriber. With Reactive Streams, data transfer must not begin until a subscriber specifically requests it.
Conclusion
In this post, we took a look at Reactive Streams and its implementations, and how they interoperate. You must use back pressure on HTTP requests on responses if you want to use Reactive Streams in web programming. To achieve this you must be able to appropriately adapt to the traffic that flows in. In the next post we will be looking at how we use Reactive Streams with Armeria to do this!
Let’s Play with Reactive Streams on Armeria – Part 2
The features mentioned in this blog post aren't everything there is to Armeria. For more information on what Armeria can do for you, refer to the official website and the following sources.
- GitHub: line/armeria
- Twitter: @armeria_project
- Slack: Armeria
- API documentation
- Armeria examples: line/armeria-examples