
I work on the backend code that supports some of LINE's location-based features, and we've recently had an exciting project to improve our support for keeping track of nearby points of interest (PoIs) — shops, museums, anything you might want to know that you were close to.
In order to deliver this as quickly as possible, we elected to reuse an existing PoI datastore from a previous project — which meant we had to read the data from MongoDB. Although I'd worked a little with MongoDB in an existing codebase, this was my first time introducing it into a system from scratch, and my first time working with it from Kotlin.
Investigating a hotspot
My colleague wrote the initial querying implementation and some test cases — I'm a big believer in "make it work, make it right, make it fast", so this was definitely the right way to start. However, this system needs to handle over 10,000 requests per second, so we had some performance concerns. One thing that we noticed in profiling (using async-profiler) was that a method that was supposed to be a distance calculation was actually spending most of its time in HashMap lookups:

The MongoDB client library was deserializing the results of our find query into a generic Document type — a perfectly sensible way to represent a potentially unknown result (and similar to how every object is represented in some languages, such as Python or Ruby). But for our use case this is very wasteful, since we know exactly what the format of the returned document is. So I wrote some proof-of-concept code to use a custom deserializer instead:
import ch.hsr.geohash.WGS84Point
import org.bson.BsonReader
import org.bson.BsonWriter
import org.bson.codecs.Codec
import org.bson.codecs.DecoderContext
import org.bson.codecs.EncoderContext
data class PoiLocationOnly(val id: String, val location: WGS84Point)
object PoiLocationOnlyCodec : Codec<PoiLocationOnly> {
override fun encode(writer: BsonWriter, value: PoiLocationOnly, encoderContext: EncoderContext?) {
TODO("Not yet implemented")
}
override fun getEncoderClass() = PoiLocationOnly::class.java
override fun decode(reader: BsonReader, decoderContext: DecoderContext): PoiLocationOnly {
reader.readStartDocument()
val id = reader.readString("_id")
while (reader.readName() != "geolocation") reader.skipValue()
reader.readStartDocument()
while (reader.readName() != "coordinates") reader.skipValue()
reader.readStartArray()
val lon = reader.readDouble()
val lat = reader.readDouble()
reader.readEndArray()
reader.readEndDocument()
reader.readEndDocument()
return PoiLocationOnly(id, WGS84Point(lat, lon))
}
}Of course this is not production-quality code, but I wanted to confirm that we'd correctly diagnosed the problem before spending the time and effort it would take to write a proper (fully tested) implementation. So I ran this code on our canary instance for a few minutes and took a profile. The distance method is no longer making hash lookups:

You can't see it from the image above, but the original implementation was part of 1118 CPU samples, with the distance method being just 340 of those. The corrected implementation is part of 267 samples, all of which are in the distance method. The difference between 340 and 267 might be random noise, or maybe due to profiling at a different time of day when the request load was lower.
We also confirmed that this was saving some CPU usage in the methods that query MongoDB — with the original (default) implementation, result decoding shows up in 2647 samples:
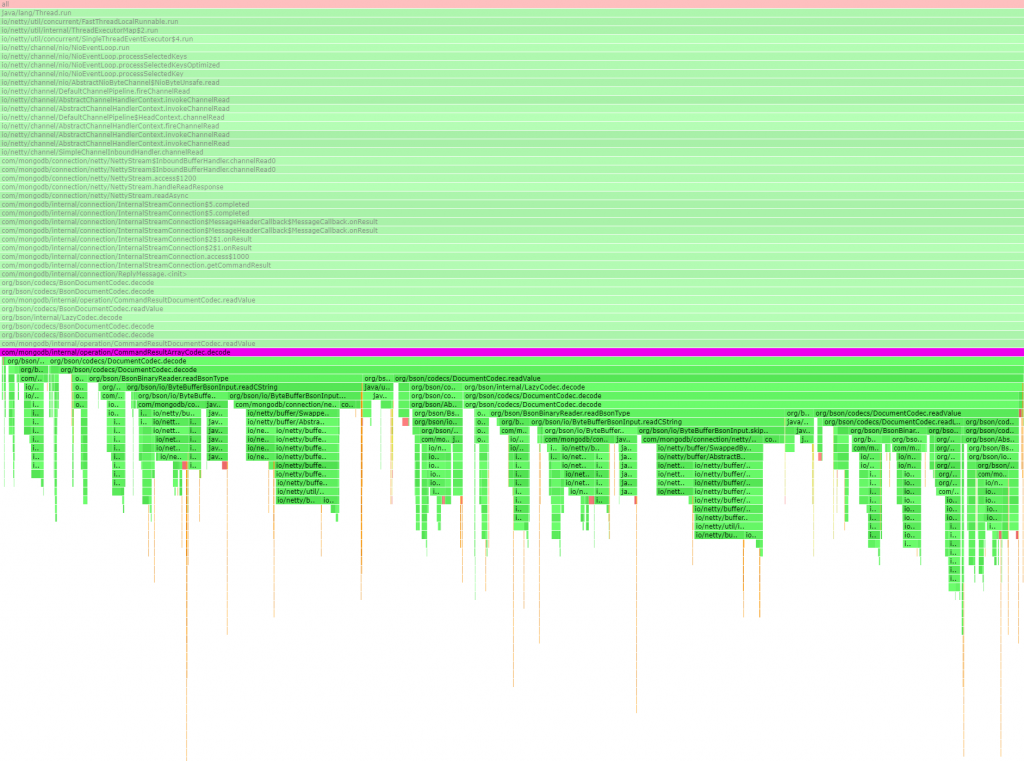
Whereas with the custom implementation, result decoding shows up in 1486 samples, and most of them are inside our custom codec:
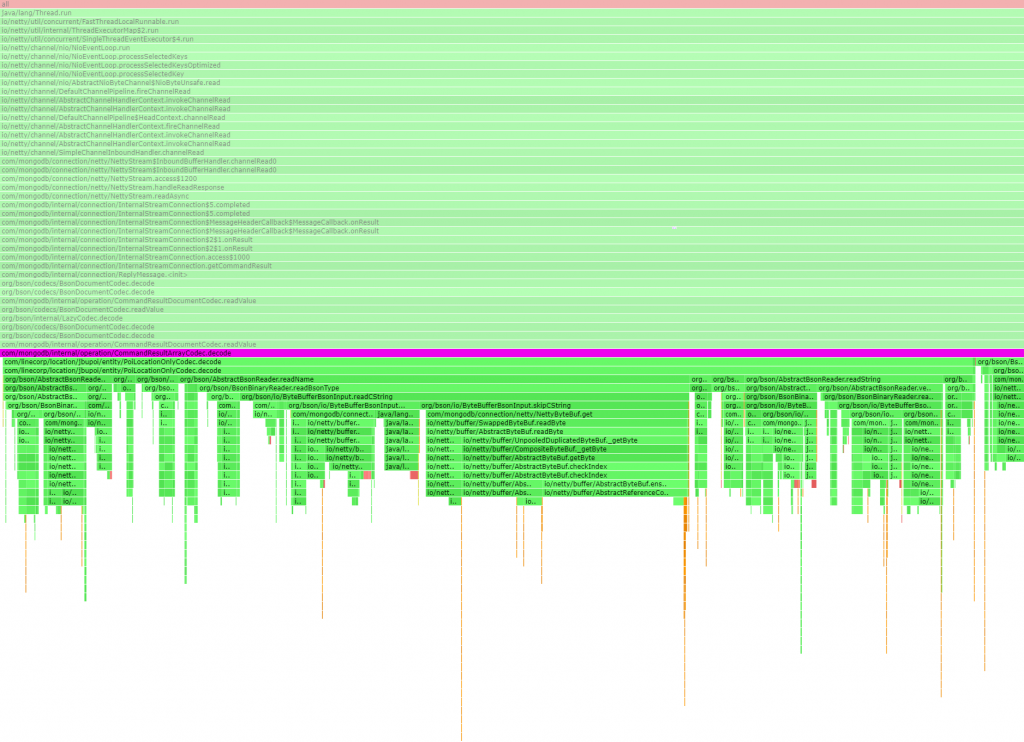
Reaching a conclusion
At this point we had a discussion in the team, where I actually argued for abandoning this line of work. While it was clear that we were spending around 5% of this component's CPU time on redundantly representing these query results in a HashMap-based type, which we then immediately extracted two fields out of, it was also clear that this wouldn't be a game-changing performance improvement.
Saving 5% CPU time is nice, but this component wasn't really the bottleneck in the first place — we were running 6 instances of this backend server (and would still need to run 6 instances if we could reduce the CPU usage by 5%), compared to dozens of significantly higher-spec nodes for the MongoDB cluster proper. So it was clear that the biggest performance gains would come from improving our MongoDB queries. (Eagle-eyed viewers may have noticed a change in method name between the first two profile traces — actually the work to improve our queries was already going on in parallel). Most of all, writing a production-quality deserializer looked like a tedious task that I really didn't want to do — and I was conscious that code that is tedious to write is also tedious to maintain.
As you can tell from the fact that this post isn't ending yet, my colleague convinced me otherwise — he thought that a 5% improvement in CPU usage was very much worthwhile. So I started writing the production implementation — but as I struggled with the boilerplate needed to match the MongoDB API, I thought there must be a better way. So I did what I should have done in the first place: I looked for a library that could help us out, and I found KMongo. While this library offers a lot of functionality that I haven't explored yet, the important part was that I saw it integrated with kotlinx.serialization for no-reflection (de)serialization using generated code. This meant it should be roughly as fast as a handwritten deserializer, but instead of having to write all the boilerplate (such as error handling) myself, all I had to do was write some annotated classes with the same shape as our PoI query results:
import kotlinx.serialization.Serializable
@Serializable
data class Geolocation(val coordinates: List<Double>?)
@Serializable
data class PoiLocationProjection(val _id: String, val geolocation: Geolocation?) {
fun latitude() = geolocation?.coordinates?.get(1)
fun longitude() = geolocation?.coordinates?.get(0)
}And there we have it! From the profiling trace we can see that deserialization now happens via some generated $$serializer inner classes:
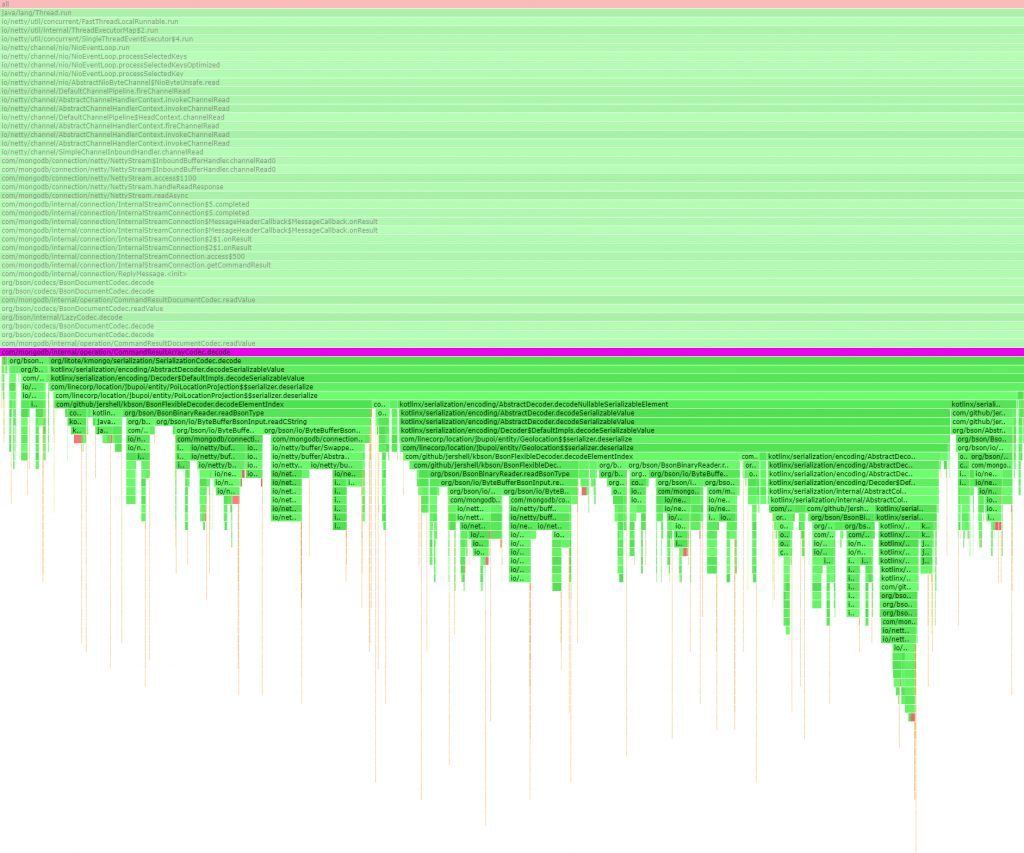
So we're getting high-performance deserialization with no hashmaps and no reflection, similar to handwritten code, but using a (hopefully) mature and maintained library rather than having to write and test some custom code myself. Job done!