
Hello, this is Tung from Clova team. Clova is our AI platform that comes with the first generation smart devices as Clova Friends and Clova Wave. You can find more information on the products here (Sorry, the site is in Japanese).
Today, as we start 2019, I want to invite you to reflect on a very hot topic of 2018 — the emergence of multiple competitive language models, ELMo, ULMFit, OpenAI Transformer, and BERT. There are articles on the internet explaining the internals of each model. So I will try to bring you a different perspective by putting all the four models side by side, making comparison and going into detailed aspects when necessary. Are you ready? Let's go!
Brief introduction of language model
What is a language model?
Simply speaking, a language model is a model to calculate probability distribution over sequences of tokens in a (natural) language. Older models such as n-gram language models have achieved good results but are severely limited by the curse of dimension due to many possible ways to combine n tokens. Newer models based on neural networks make use of distributed representations, that is, low-dimension vector representations of tokens that can mitigate the curse of dimension. Word2vec is a perfect example which you may have heard about. It provides a distributed representation of words that can be conveniently plugged in almost every NLP (Natural Language Processing) models with success.
Why should we care about language models?
Because they can empower a very efficient way of learning, called transfer learning. Transfer learning helps you to train, often unsupervisedly on a lot of data, then to apply the pre-trained model to efficiently learn downstream tasks. In real world situations, those downstream tasks are often supervised learning tasks but lacking enough labelled data to train on. Transfer learning can help this by leveraging knowledge learned from vast data in pre-trained model. (You can read more about transfer learning on Sebastian Ruder's blog here). Word2vec which I mentioned earlier is actually one example of transfer learning, a universal one. Researchers since then have been looking for even better way of transfer learning, which finally results in 2018 language models of our main topic; ELMo, ULMFit, OpenAI Transformer, and BERT.
Language models in 2018
How good are the 2018 language models?
They are said to possess univesality, for the fact that they achieved state-of-the-art scores on various NLP tasks. I combined available scores from their original papers and official website to one place for easy comparison.
Scores of various NLP tasks
△: Smaller than previous state-of-the-art at published timing
*: Not comparable exactly due to different setup
| Task | Description | ELMo | OpenAI Transformer | BERT_base |
| GLUE (consists of 8 small tasks below) |
A set of 8 tasks of language understanding | 71.0 | 72.8 | 79.6 |
| ⊢ 1. MNLI | Predict entailment/contradiction/neutral of a sentence pair | 76.4/76.1 | 82.1/81.4 | 84.6/83.4 |
| ⊢ 2. QQP | Determine if two questions asked on Quora are semantically equivalent | 64.8 | 70.3 | 71.2 |
| ⊢ 3. QNLI | Binary classification version of SQuAD: whether sentence in (question, sentence) pair contains answer to question | 79.9 | 88.1 | 90.1 |
| ⊢ 4. SST-2 | Binary single-sentence classification of movie reviews | 90.4 | △91.3 | 93.5 |
| ⊢ 5. CoLA | Binary single-sentence classification of linguistical acceptability | 36.0 | 45.4 | 52.1 |
| ⊢ 6. STS-B | Score 1 to 5 for semantic similarity of sentence pairs from news headlines and other resources | 73.3 | 82.0 | 85.8 |
| ⊢ 7. MRPC | Binary classification for semantic similarity of sentence pairs from online news | 84.9 | △82.3 | 88.9 |
| ⊢ 8. RTE | Binary entailment task similar to MNLI, but with much less training data | 56.8 | △56.0 | 66.4 |
| SQuAD | Find answer for a question in a text span from Wikipedia | 85.8 | - | 88.5 |
| CoNLL NER | Named entity recognition | 92.2 | - | 92.4 |
| SWAG | Predict sentence entailment from multiple choice question | 59.2 | - | *81.x |
| Coref | Clustering mentions in text that refer to the same underlying real world entities (OntoNotes coreference from CoNLL 2012 shared task) | 70.4 | - | - |
| SRL | "Who did what to whom" tagging | 84.6 | - | - |
| SNLI | Predict entailment/contradiction/neutral of a sentence pair | 88.7 | 89.9 | - |
| SciTail | Multiple choice question-answering given candidate knowledge sentences | - | 88.3 | - |
| RACE | Multiple choice for sentence completion after reading comprehension | - | 59.0 | - |
| ROCStories | Binary choice question-answering after reading comprehension of short stories | - | 86.5 | - |
| COPA | Common sense binary choice question-answering | - | 78.6 | - |
Architecture comparison
Of the four language models, two are LSTM-based and the other two are Transformer-based.

So why are LSTM and Transformer used for making language models? We will investigate what their linguistic capabilities are in the sections following.
LSTM
LSTM stands for Long Short Term Memory, which is a special type of recurrent neural network. (You can find a very good introduction to LSTM here). Architecture-wise, its recurrency is suitable for sequential processing which seems a natural fit to handle text sequence. Additional mechanisms such as bi-direction and attention have helped to make LSTM even more successful for many NLP tasks. There are recent active researches to un-blackbox LSTM learning capabilities. Today, I want to introduce some key results from papers mentioned in "Trying to Understand Recurrent Neural Networks for Language Processing" (Goldberg, Blackbox NLP workshop EMNLP 2018 - might take a while to be loaded). Please refer to the original papers below for more details.
- LSTM can learn basic, simple linguistic features (Conneau et al., ACL 2018)
- Unsupervised LSTM can learn syntax-sensitive dependencies (Kuncoro et al., ACL 2018)
- There are effective context spans that affects LSTM learning (Khandelwal et al., ACL 2018)
- Nearby and far context
- Different types of tokens need more or less context
- Dropping and replacing target token affect perplexity differently
Practical takeaways
- LSTM, especially unsupervised LSTM which is used in language model case, can learn linguistic features
- Different context and token types have different impact on LSTM learning. We think this is a very important implication for designing task objectives like BERT (will get back to this later)
Transformer
Despite the catchy title of the original paper, "Attention is all you need" (Vaswani et al., 2017), deeper understanding of attention mechanism in Transformer architecture still requires more researches. There are several papers looking deeper into Transformer with interesting results; I've listed a couple below. Note that these papers are about NMT (Neural Machine Translation), a task that is different from language models, but they still provide useful information for analysis of linguistic learning capability.
In the "Attention is all you need" paper, ability of modeling distant dependency efficiently is considered the key attribute of attention. But does it imply that Transformer can learn longer context than RNN/LSTM?
- "Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures" (Tang et al., EMNLP 2018)
- Result: Transformer outperforms RNN-bideep (implemented in Junczys-Dowmunt et al.,2018) for distances 11-12, but RNN-bideep performs equally or better for distance 13 or higher
- Thus, we cannot conclude that Transformer models are particularly stronger than RNN models for long distances
Attention was used extensively in Transformer, but does it have the same effect every where?
- "How much attention do you need?" (Tobias, ACL 2018)
- Result: Attention importance is not the same throughout Transformer architecture
- Other techniques like residual connection, layer normalization also play important roles
This leads to the question, can we combine RNN/LSTM with other techniques in Transformer paper for a better result? An affirmative answer was given in the paper below.
- "The best of both worlds" (Mia Xu Chen et al., ACL 2018)
- Result: RNMT+ architecture scored even better than Transformer
Another natural question is, given their similarity based on Transformer: what makes OpenAI Transformer and BERT different? It is believed that the bi-directional characteristic in BERT architecture as well as BERT's task objectives, as listed in the table below, make BERT learn context better. (Refer to Google AI blog and code on Github)
You may have recognized by now that the setting task of BERT using masked language model sounds very familiar to the conclusion of "different context" in the LSTM section. We hypothesize that Transformer architecture has a similar dependency on different contexts, which implies alternating context was what helped BERT learn better than OpenAI Transformer. Let's expect more researches on this topic this year.
How to transfer learning
Once you have pre-trained a language model, there are two general ways to apply it to other downstream tasks: one is feature-based, and two, fine-tuning. In principle, both ways can be used for all the four models.
Feature-based
This method utilizes task-specific neural network models. It usually adds a latent output vector, composed of appropriate layers from the pre-trained language model. For example, you can add a latent output vector from ELMo to the CNN model for text classification as shown in the diagram below.

The pros and cons of this model are:
- Pros
- Requires less resources than fine-tuning
- Cons
- Requires a customized model for each downstream task
- (Generally) Scores lower than fine-tuning
Fine-tuning
A unified architecture of a pre-trained network plus several simple linear layers can be used for any task like example from OpenAI Transformer as shown below. The pre-trained network will be trained again (fine-tuned) together with extra linear layers on the task specific data set.
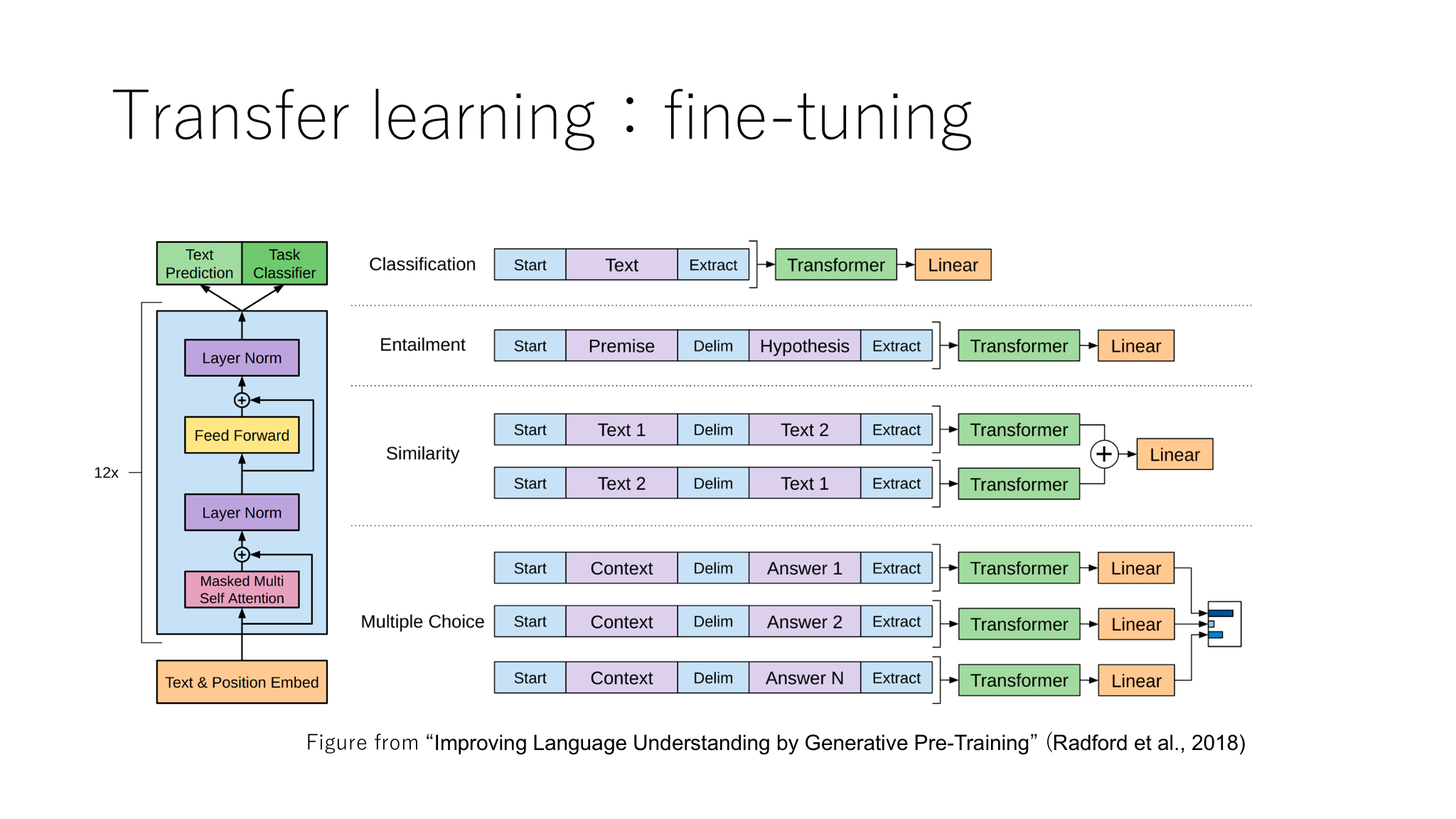
The pros and cons of this model are:
- Pros
- Simple structure
- (Generally) Scores higher than feature-based
- Cons
- Requires more resources due to re-training pre-trained models that are originally big
- Larger latency is expected when serving (as a trade-off for higher score)
Summary
Thank you for going through this with me. Let's wrap-up and draw some practical conclusions from an engineering point of view.
- Advanced language models have universal linguistic capabilities
- More detailed theory of what they can, and can’t are likely to be the focus of coming researches this year
- Development of best practices has not completed (yet)
- Basic components such as LSTM/Transformer can be combined with other techniques to strengthen its features
- Task design plays crucial role to enhance learning
- Different from research, deployment into production will require careful design and trade-off between raw score and system performance
Happy new year to you all, and do look forward to more exciting advancement in NLP!