
Foreword
A feature called "Discover" (known as "Explorer" in regions outside of Japan) and a new subscription model called "Follow" have been added to the LINE Timeline service. Although users are familiar with these features, we ended up writing this post because we wanted to share the parts that we had considered and made efforts on within these features. Starting with this introduction, we have planned a three-part series to bring you more detailed information.
- LINE Timeline's New Challenge Part I - "Discover" for Exploring Recommended Content and the New Subscription Model "Follow"
- LINE Timeline's New Challenge Part II - Introduction to the Discover Delivery System
- LINE Timeline's New Challenge Part III - A Closer Look at the Discover Recommendation Model
A new challenge begins
"Discover" and "Follow" have been subjects of discussion since several years ago from the service perspective, and we've been contemplating them for a long time since we had to consider LINE's social environment, which is strongly perceived as a space for individuals. Currently in Timeline, one must be friends with another to subscribe to their content. But as we use the app, we somehow tend to gradually become hesitant to write on Timeline because our social graph now extends to the people we added as friends just to keep them in our contacts. As a result, instead of seeing news from our friends, our Timelines were covered with spam posts from business accounts. Since developers are also users, we have discussed a lot about how to escape such a predicament from the user's position. Through these two features, LINE Timeline intends to engage in a new challenge in both the service and technical perspectives.
What are Discover and Follow?
Timeline is generally considered as a closed type of acquaintance-based social media. Although we can receive various types of information through Official Accounts, this is also something that can only be subscribed to by accepting a friend request. This can be both a strong and weak point. Although there is a lot of public content that everyone can see, it is very difficult to reach this content. The permission of Timeline public posts is set to Public. But this just means the content's permission is set for everyone to read, not that it is delivered to everyone. Timeline delivers the content only to people who are friends with each other. So we have introduced a space to discover and consume good content that cannot be regularly reached by users, and a device to continue subscribing to the content you're interested in. This is composed of the "Discover" and "Follow" features.
Note. Discover and Follow are available in LINE version 10.3.0 or later. These features are currently provided in Japan (as "Discover"), Taiwan and Thailand (as "Explorer"). Extensions of these services to other countries is under consideration.
Discover
If you press the planet icon ( ) on the top right section of the Timeline tab, you can use the Discover feature. Or you can enter it through "Discover Preview" on the Timeline feed. This is displayed as "ディスカバー" in the Japanese version, and "Explore" in the English version.
) on the top right section of the Timeline tab, you can use the Discover feature. Or you can enter it through "Discover Preview" on the Timeline feed. This is displayed as "ディスカバー" in the Japanese version, and "Explore" in the English version.
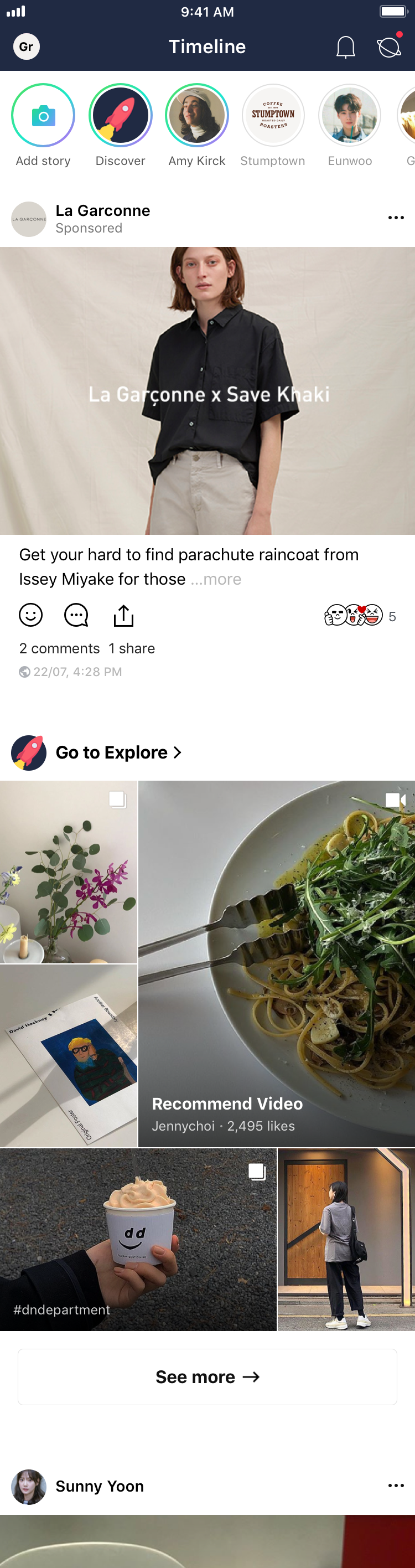

What is the difference between Timeline and Discover?
Timeline and Discover are spaces to show the content produced by users or business accounts. But these two spaces play somewhat different roles.
- Timeline: The space to subscribe to the content of your friends or users you have Followed.
- Discover: A space to explore and consume content that people may be interested in.
Most of all, the recommendation system properly filters the content that is inappropriate or is low quality and only shows content that is worth seeing. In this process, users can personalize the content based on their interests. By selecting content, it provides them with an opportunity to continue searching for similar content in the future. In addition, there are changes made for content producers. As shown in the image below, you will have an opportunity for more people to see your content if you write public posts. Now you have an opportunity to become a famous influencer on LINE as well. We are considering many things to support this feature, and thank you for your anticipation.
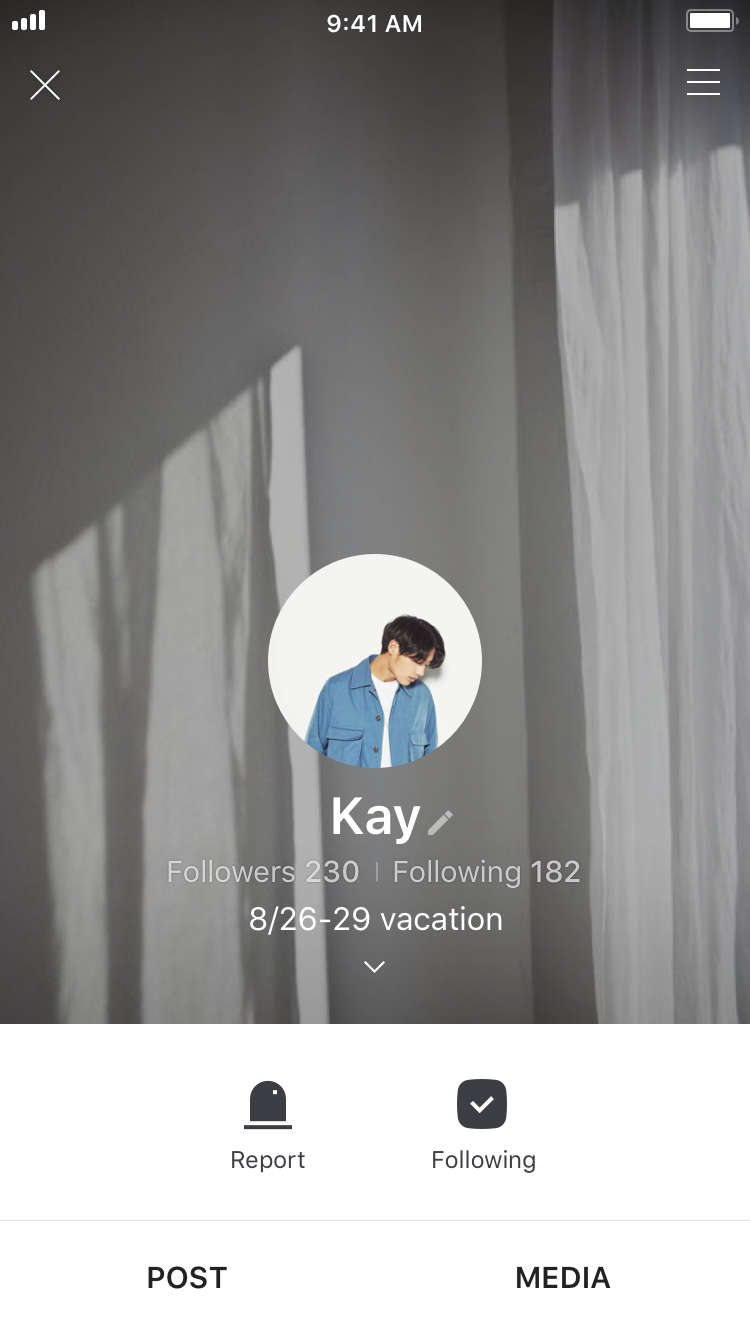
Follow
Follow provides the method for subscribing to the content of users who are not friends. Since Follow isn't tied to the messaging function, you can use this service if you do not want to talk in LINE but just want to subscribe to the content. You can check the Follow status in My Profile home.
More information on Discover and Follow is available on the LINE Timeline official blog (Japanese only).
Discover's basic operation method
As it has been stated in many blog posts already, LINE is developing and operating large-scale services with NoSQL-based products, such as Redis or HBase. LINE's Timeline and Discover also use the same technology to provide their services. Since it has been prepared well with years of know-how, we managed to develop them without much difficulty. This also includes the responses to reliability, scalability, and fault tolerance. These factors must be considered at all times. That's why we had more time to concentrate on other things.
Focus on "How" rather than "What"
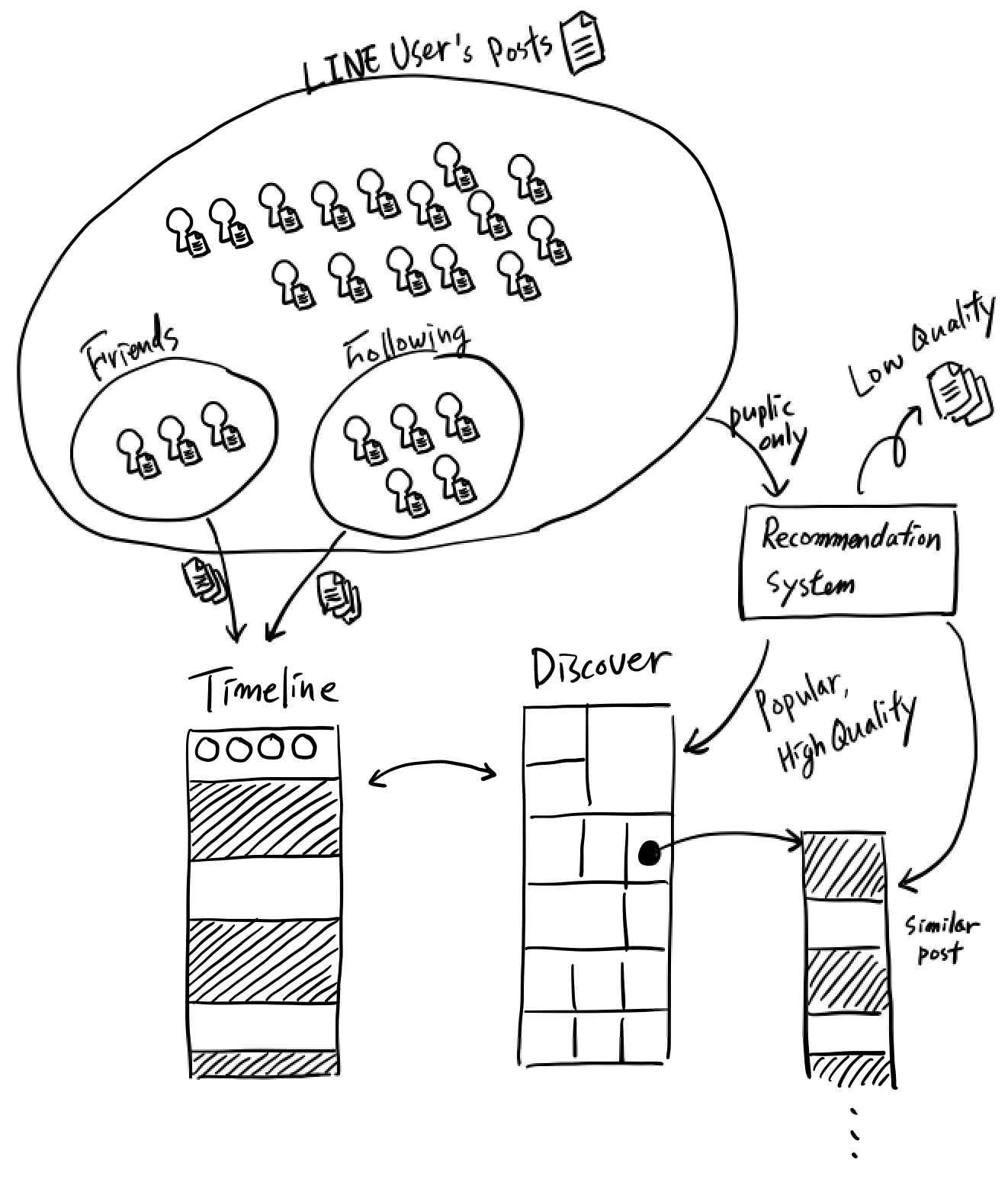
Discover is a project where the key point is selecting which content to show. A few years ago, large-scale data storage and fast delivery were the main topics. Now, the core ability is based on which interest the data will be pulled out of and discovered. We combined the image/video analysis component, such as PicCell, which was introduced in LINE DEVELOPER DAY 2019, and machine learning technology. Tasks such as binding similar users or dividing them into segments or into groups with similar interests became possible by making a learning model based on the data acquired by Timeline, classifying content using this model, and delivering the interests shown by individual users. The operation process cycle is as shown below.
The interest delivery cycle and its main components
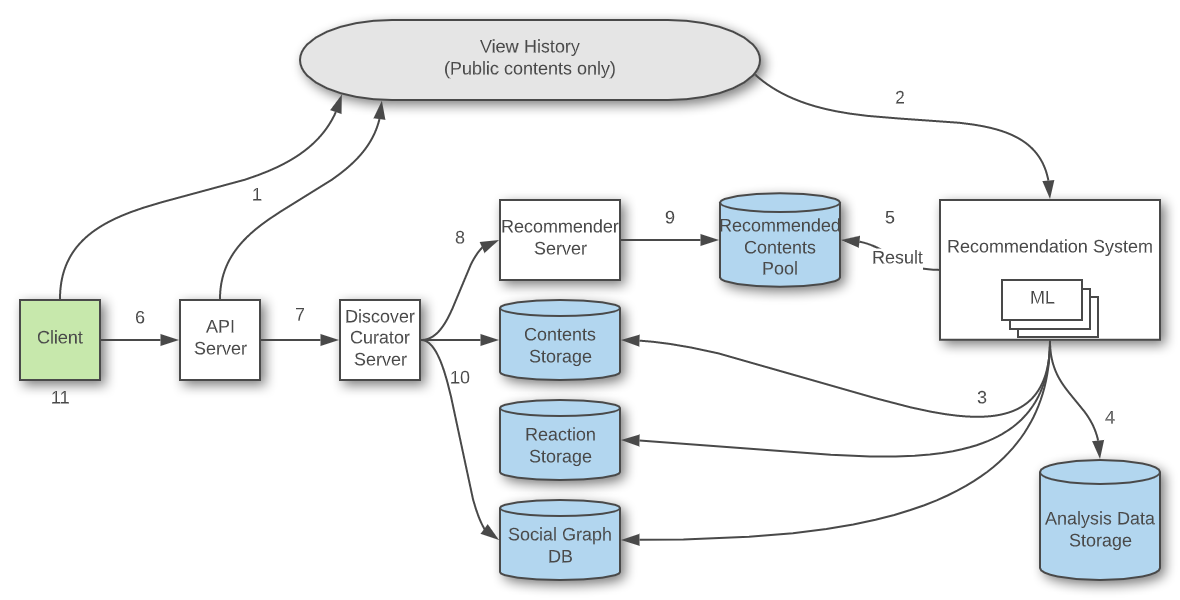
Note. The data recommended to Discover is limited to content where the access privilege is set to public.
1. To recommend content, the first thing you need is data to determine the popularity or interest level of the content. Content information seen by users and reaction information, such as "Likes" or comments, are stacked in an analyzable form.
2,3,4. Data is collected in Analysis Data Storage, and the recommendation system produces the results through the various types of ML (Machine Learning) models. Which topic to classify into and which content to not recommend are determined here.
5. Data models made by ML and the results are converted into a form that can be served to a service and stored into a storage with a fast reading speed (Recommended Content Pool). Now the data has reached a serviceable area.
6. The client requests the details of Discover.
7,8,9,10. The request is sent to the Discover Curator Server and configures a grid view after obtaining the recommended content from the Recommender Server. At this time, images, videos, etc. are properly arranged by referring to My Social Graph.
11. The data is transferred to the client and rendered on the screen.
We'll explain the main components in detail.
Discover Curator Server
Imports content from the Recommender Server and Content Storage to play a role in creating the Discover grid view. It is implemented as a scalable form so that various content, such as advertisements or LINE Story, can be attached to Discover.
Recommender Server
Plays a role in delivering the Recommended Content Pool data so they can be used in services. It manages and organizes the Recommended Content Pool data, and also stores content by classifying data according to the various requirements. For example, data is classified into various topics, such as age, gender, country, media type (image or video), or content type (animal or person).
Recommender System
Creates the Recommended Content Pool, which is a group of recommended content candidates with a quality that is worth recommending in Discover from among the public posts. Content that is determined to be low quality or not useful is eliminated here. It measures the similarity of content to create a similar content graph, and it creates the raw data required for serving to be stored into the Recommended Content Pool. It handles the tasks internally as shown below.
- Similarity Measurement: Finds the posts similar to the posts which the user had seen and shown interest in the past from the group of recommended candidates to create a list of similar content
- Ranking: Aligns the content according to the user's preference.
- Testing: Tests the Discover recommendation model using various ML methods.
Contents & Reaction Storage
This is storage space for storing all content including Timeline posts, reaction information, such as Like or comment, and external link content. It is configured as a large data system because all data is stored permanently. Although this has been expressed as a box in the image above, it is actually composed of several components. Since it has to serve from the cold data up to the most recent data that must be quickly accessed, several storage products are used.
Social Graph DB
In Timeline, the subscription relationship is very important. The Social Graph DB stores and serves the final subscription relationship considering the mutual settings, such as blocked users or hiding content from the feed based on the Follow relationship with the friend. Internally, we're using a self-developed Hbase-based graph database. The part related to this will be explained once more in Follow.
Discover's recommendation model
We have provided a very extensive explanation. But after all, it is a model for recommending the content that is popular among many people and the content that users have shown interest in. It also recommends content that is similar to the content you are looking at here. Due to the limited space, we'll cover the details on recommendations in the next section and just look into the sketch flow.
To determine the similarity, it is necessary to convert data into vectors. The target public post is filtered and the first processing is performed to create the vector data by each category. Here, you can think of a vector as data which depicts the content's characteristics by converting it into numbers.
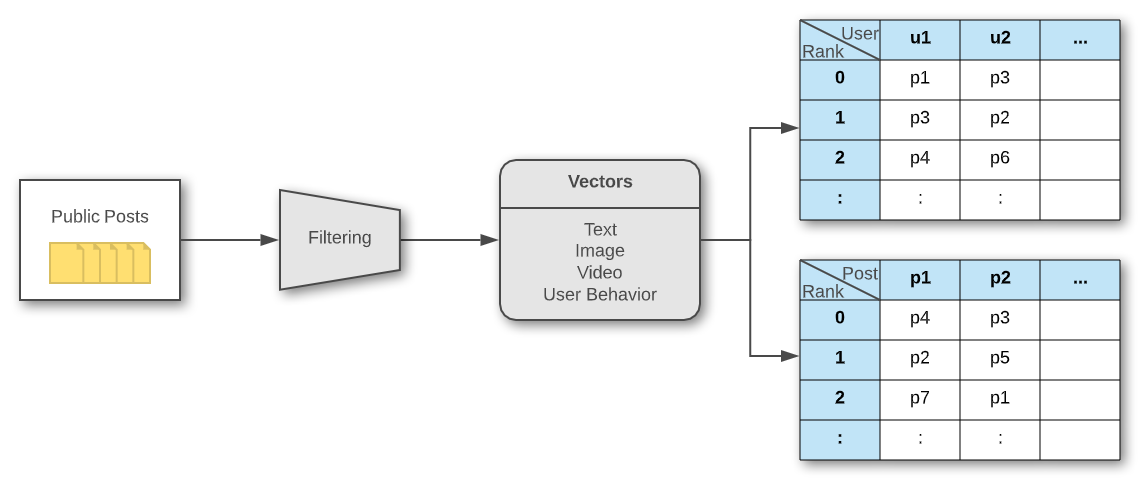
If content is expressed as vectors, you can measure the similarity of content using the cosine similarity of these vectors. Four types of vectors (based on text, image, video, and consumption history) are created per post. These vectors are combined properly and become aligned as one. You can make a recommendation list which includes posts with similar text as content users were interested in, as well as posts with similar images, posts with similar videos, and posts that are consumed in a similar pattern.

Follow's introduction process and concerns

Follow provides a way to extend your existing friend-based social graph even further in the Timeline space. To facilitate relationship extension, we need a space for unknown content to be noticed by users, and that's what "Discover" is for. These two features are a perfect match.
Countless questions from yourself
"Would the social graph as social media be the same or different from LINE's friend list?" This is the topic which we really considered and discussed a lot. Although LINE is a messaging app, it also provides a social media style Timeline. So the following equation is both true and false.
Talk exchange relationship = Timeline exchange relationship?
Let's actually determine whether this is true or not. Let's say you're wondering how your friend is doing. But in Timeline, there are friends that you don't want to share your status with and vice versa. That's why the equation above is partially true but you don't want to make it so. So there are many filtering features in Timeline. Some examples are shown below.
- Do not share my content to the public (close/exclude)
- Hide specific users from the news feed (user hide)
- Hide specific posts from the news feed (post hide)
- Block a friend (block, the most powerful method that even blocks conversation)
Using these features, you can create a space to receive only the news that you want. But that is a bit difficult. Then what should we do?
Separation or Extension of the Social Graph
The best thing to do is starting from the LINE friend relationship, but also filling up with just the people you want to talk with in Timeline regardless of friend status after separating a specially managed relationship list. But since this is not an easy thing to do, we chose the method of extending rather than separating for now. If we do so, it also matches the purpose of making the Timeline space a more open space as we mentioned earlier.
Using the Follow feature, we can set up a subscription relationship without being tied to a larger scheme called LINE Contacts. We need to pay attention to this. If we summarize the relationships in Timeline based on Follow, we can make a graph which is different from LINE's existing social graph. If we can set up only the people we want to talk with among existing friends, that is if we can migrate, we can separate the social graph. Naturally, it would take a bit more time until the social graph for the content subscription is organized. But as a result, we think users will be able to head toward the desired form and direction.
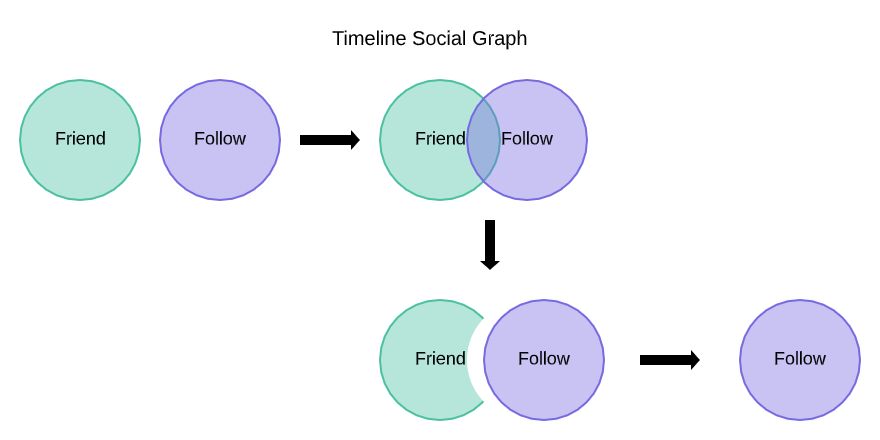
Concerns and efforts for a gigantic relationship information service
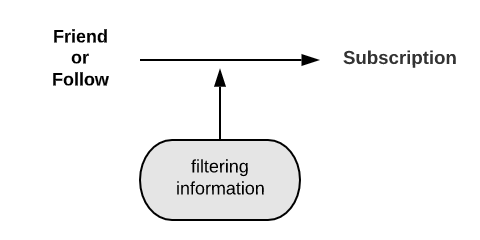
In Timeline, a space to connect content creators and consumers is required, and such a relationship must be stored after making it into data. The former is the Timeline feed, and the latter is the subscription relationship. You can gain the subscription relationship by combining friends and Follow relationships, and various types of filtering information. Filtering is a feature to hide or make your content private to specific users.
Subscribing to a friend's content can be expressed as the graph shown below. For the sake of convenience, we'll replace this as friend relationship instead of a subscription relationship. In the image below, the left side shows the friend relationship and the right side shows up at the post writing edge. We can say the right side expresses the subscription relationship.
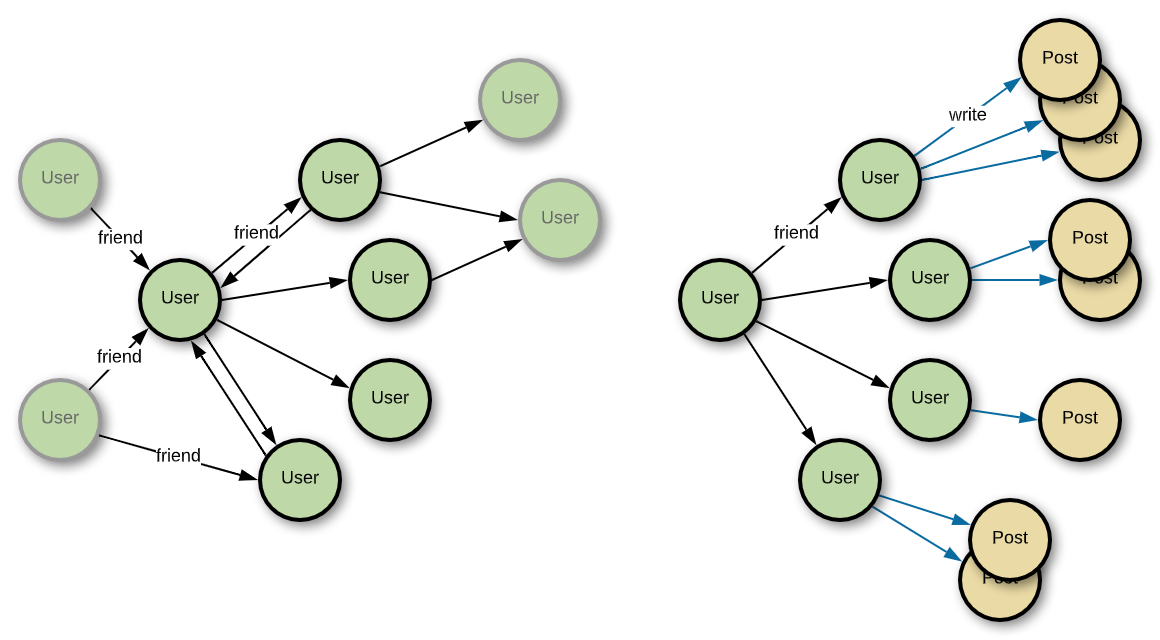
In Timeline, it is important to effectively store and maintain this subscription relationship information. Although we had stored and used a simple key-value type at first, there were many cases where we had to redesign the key or generate the key again each time the feature is modified or extended. Currently, we're using a self-developed graph database to effectively store and use this relationship information. The advantage of graph database is that we only need to connect a new edge to the existing vertex without having to define and develop a key-value set to respond when a new relationship is created. Since the graph database provides CRUD (Create, Read, Update, Delete) for the vertex/edge and the method to search graphs, it isn't necessary to make the key-value every time. However, since there are issues that we must overcome, such as limited performance, just with the graph database, the relationship information is stored and used for the service by using a graph service that has covered these issues once more.
The image below shows a user following the friend edge to find a post that was written by a friend's friend. Using a graph database, it is also possible to explore as shown in the image below without additional development.
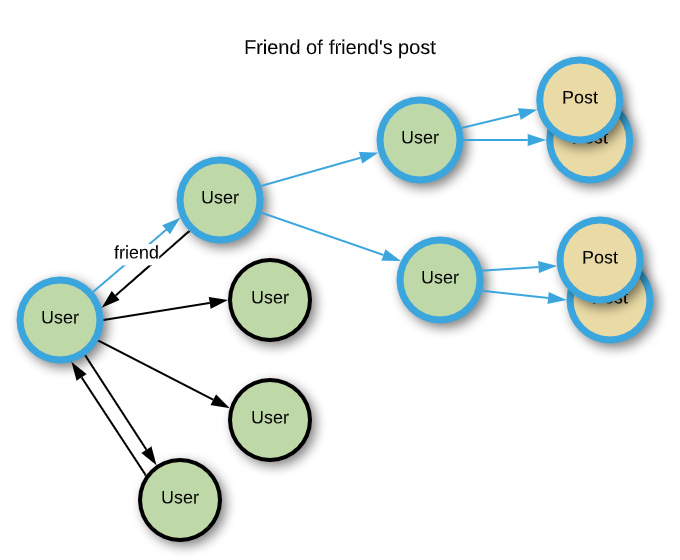
Since the actual service must be able to look up such information very quickly, it doesn't depend just on the graph database. Due to the low performance of a deep graph search, parallelism plays an important factor to quickly search and find a vertex by each level. Since the ideal situation and reality always differs, we're devoting a lot of effort to improve this aspect.
Because of the Follow feature, there will be a lot more final subscription relationship edges as the subscription relationship extends to friends and Follows.
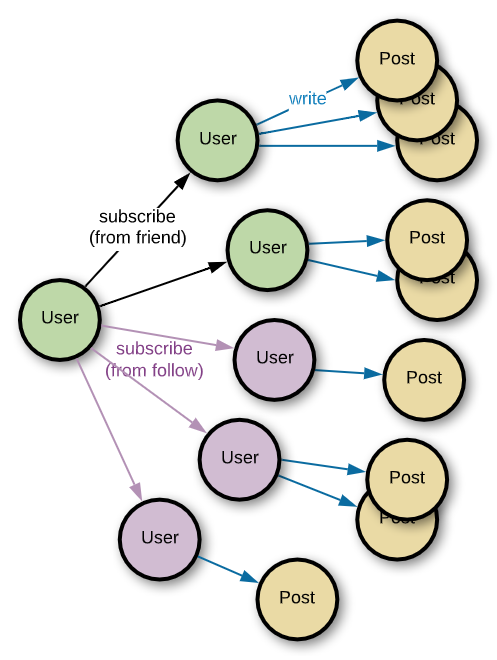
Although this is an anti-pattern from the perspective of the graph system, users that we need, such as famous influencers or famous Official Accounts, show this pattern. So we're solving problems by splitting and sorting one person's subscription graph into a form that can have a performance advantage. Such sorting cannot become generalized and must be made to fit the service because it is a part which varies depending on the service details and requirements.
Follow may look like a simple feature, but it requires a lot of consideration and effort for the service and technology aspects underneath. We hope this becomes a reference for people who have a similar concern.
Epilogue
Discover has great significance for pulling out content that couldn't be found in the past. And Follow provides a new social relationship by allowing users to subscribe to the content of people other than their friends in LINE. Through these two new features, we hope Timeline becomes a space that gets spotlighted and developed a bit more. What we truly want is that Timeline becomes a place for content exchange and publicity for many family services and external services within the dimension of LINE service and to be a space where users can have fun and find information. At least we hope Timeline becomes more open and wish that it becomes a starting point for creating a new social graph. We intend to work this out with Discover and Follow. For this, we're planning to use all kinds of technology available at LINE. You can also look forward to our future updates.
We'll introduce the "Discover Delivery System" in the next post. We hope you will enjoy it.