
Hi, this is Yang Xu from Data Engineering 1 of the Data Platform department. Our department runs a huge Hadoop cluster and provides various services for data analysis, machine learning, and so on. One mission of our team is providing a batch ingestion service, which ingests data from different storages into our Hadoop environment for all of LINE products to meet their requirements for daily and hourly analysis.
In this article, I would like to talk about solutions for batch ingestion and introduce Frey, our new self-service system.
Traditional batch system
Overview
Let's imagine what a typical batch system should be like:
- To run batch tasks, it accepts scripts and puts them on a scheduling engine
- It has a general programming framework with tools and libraries for users to write standardized scripts which can be managed easily
- It integrates with version control tools like GitHub
Below is our first generation batch ingestion system which has been running for more than four years:
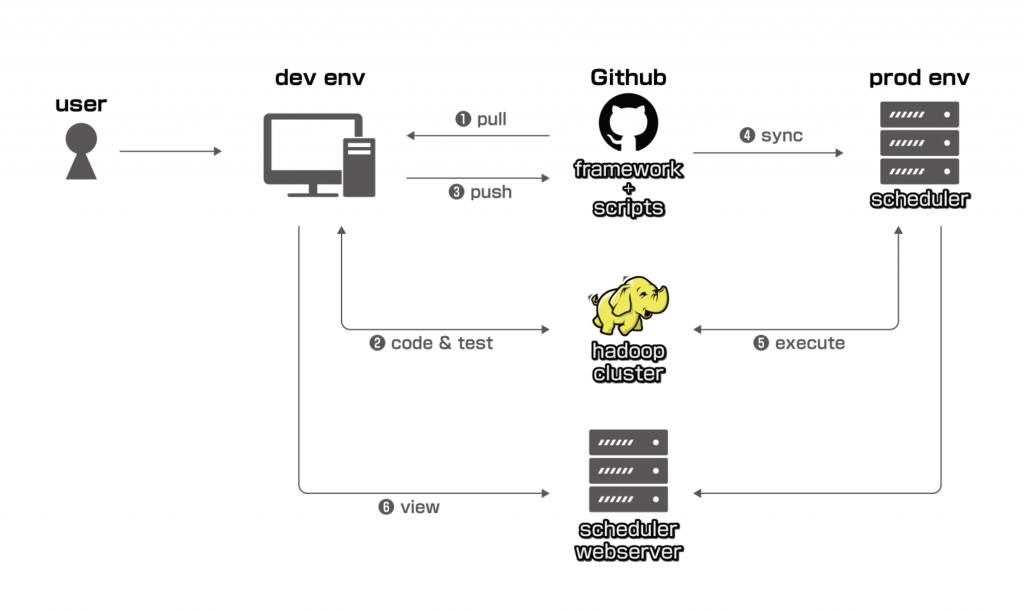
Problems
This system does achieve the goal of executing and managing batches of data ingestion and it works fine for a small to medium number of users and tasks. But as we increase the scope to all of LINE products, we have been running into some problems as time went on:
Coding (Step 1, 2, 3)
Users must have knowledge of Git or GitHub, UNIX terminals, programming, and Hadoop to submit his batch script. For data engineers or data scientists this is fine, but for users it costs too much and is impractical to demand them to learn all of these prerequisites and then use the batch system. What makes it worse is that there are so many batch ingestion requests everyday, usually we developers have to do those tasks and this requires quite long hours of work so we have no time to focus on the investigation and development of the ingestion system, which is our original duty.
Execution (Step 5)
The system is deployed on a single server, which means it has no HA and capacity is restricted by server specs.
Check and monitoring (Step 6)
Users must be familiar with scheduling engines such as Azkaban and Airflow to manage their tasks and be able to read logs for troubleshooting. Like step 1-3, it costs too much for them to learn and is impractical. It also became something that we developers had to take care of.
Permission control
Scripts and information of different products are not isolated so they are open to everyone. And anyone can fix files in the GitHub repo or operate others' tasks on the scheduling engine.
Data/task owner
It is hard to find who is in charge of some data and tasks in this system design.
Frey
Core concept
After analyzing hundreds of scripts on the traditional batch system, I found that they could be classified to be X2Y patterns where X is the source and Y is the destination, and every pattern could be described with certain parameters. So here comes the core concept of the new system: we describe one task with a config file instead of a real script, in other words, "Task as Config," compared to the traditional system which would be "Task as Script."
From now, a batch flow is called a "job," and each job consists of one or more "tasks." For example, in Airflow, a dag is a job and tasks in the dag are tasks.
Below is a template of a job config:
id: job_id
name: job_name
description: job_description
owner: owner # comma split user names, e.g. "a.b,c-d"
owner_group: group # comma split group ids, e.g. "1,2"
mail_to: email # extra email addresses except for those of owners and groups, comma split, e.g. "a.b@linecorp.com"
start_date: yyyymmdd # fixed, '19700101'
end_date: yyyymmdd # fixed, '99991231'
schedule: 0 8 * * * # cron expression, can be empty
retry_time: 5
retry_interval: 10 # in minutes
service: line # can nearly be considered as hive database name
task:
- {{ x2y_0 }}
- {{ x2y_1 }}
dependency:
- {{ x2y_0.name }}
- {{ x2y_0.name }}->{{ x2y_1.name }}
task_config_global:
{{ global config for all tasks }}Each task type (X2Y) has its own format, for example, mysql2hive:
id: task_id
name: task_name ## generated by Frey
type: mysql2hive
origin:
server:
- [id0, db0, table0]
- [id1, db1, table1]
column: [c0, c1, ..., cN]
filter:
timezone: JST
destination:
cluster: datalake/iu
database: frey_dev
table: test
ddl: ddl_string
partition:
- {key: dt, value: '%Y%m%d'}
option:
jdbc_param: {k0:v0, k1:v1, ..., kN:vN}
partition_lifetime: ''
alert:
- {"key":"RowCount","op":"==","value":"0"}Architecture
Based on the concept of "Task as Config," we've built up the next generation batch system — Frey:

Component and key features
Frey-app
Frey-app provides a web UI for users. This enables all staff to create their own batch ingestion tasks even if they have no engineering skills and know nothing about programming, UNIX terminals, scheduling engines, and so on. As long as a user has the basic knowledge about the data source and destination of their task, Frey can help them generate a config automatically.
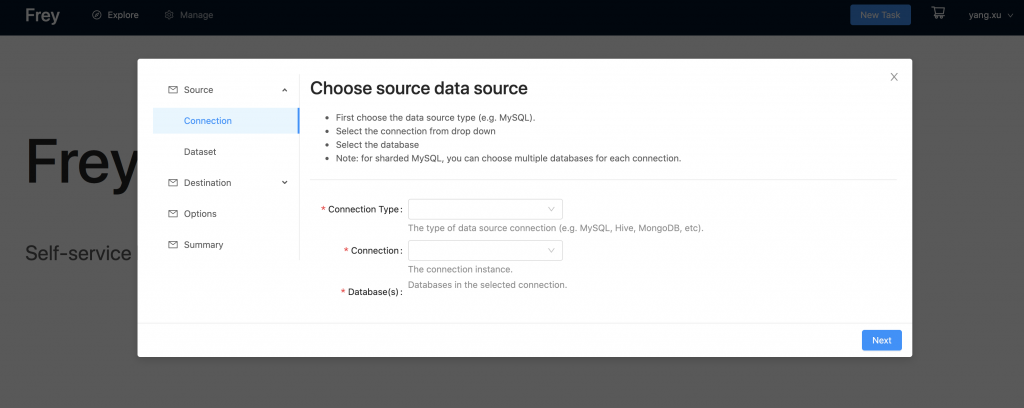
Frey-app has API to integrate with scheduling engines such as Airflow. Once a user's job is created and deployed, they can get all the information such as execution status and logs, and perform operations such as backfill and rerun. It is not necessary for users to learn how to use scheduling engines such as Airflow and Azkaban.

Frey-app has modeling for every aspect in batch ingestion: connections, jobs, tasks, users, groups, and so on. This enables Frey to flexibly scale out to support new X2Y types.
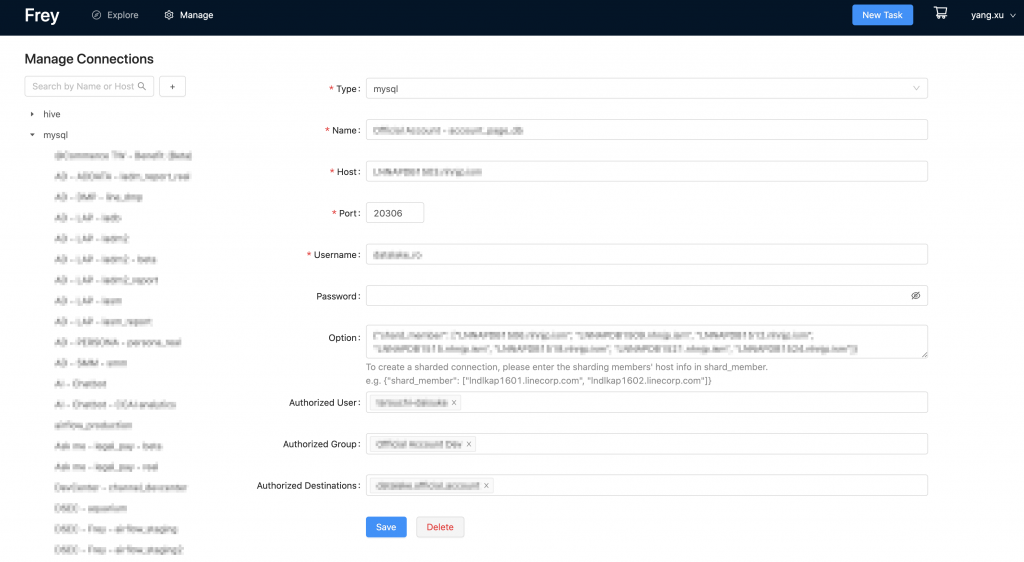
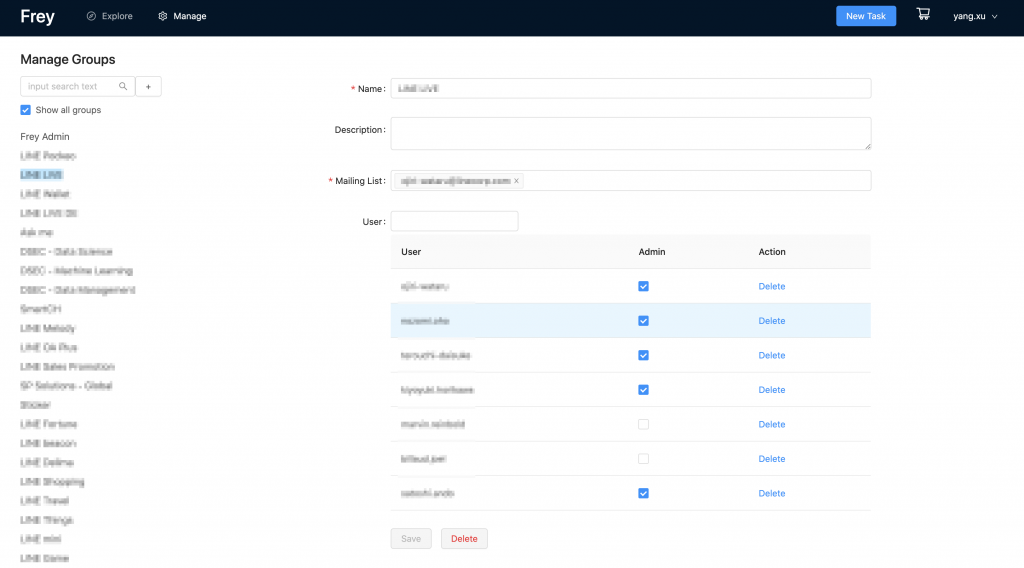
Frey-app provides admin tools to manage permissions easily. The user/group permission makes sure that every user/group can only see and operate their own connections, jobs, and tasks. With connection permission, data from one connection (source) can only be put into restricted destinations.
Frey-conf
Frey-conf is the GitHub repo where all the config files are stored. It also contains renderer and templates to generate code from config.
Below is a sample of a X2Y task template:
{{ name }} = KubernetesPodOperator(
task_id="{{ name }}-{{ destination.cluster }}_{{ destination.database }}_{{ destination.table }}",
name="{{ pod_name }}",
image="{{ image }}",
image_pull_policy="Always",
namespace='{{ namespace }}',
affinity={{ affinity }},
in_cluster=True,
do_xcom_push=False,
secrets=[keytab, mysql_host, mysql_port, mysql_username, mysql_password, mysql_db, frey_iu_keytab],
cmds=["bash", "-i", "-c"],
arguments=['''
......
......
# script content
cat <<"EOF" > main.py
from datetime import datetime
import sys,os
from mysql2hive_plugin import *
from utils import *
{% if origin.server|length > 1 %}
t = MultiMysql2hiveOperator(
{% else %}
t = Mysql2hiveOperator(
{% endif %}
# operator parameters
......
......
)
t.execute({'execution_date': datetime.strptime("{{ '{{ execution_date }}'}}", "%Y-%m-%dT%H:%M:%S+00:00")})
EOF
pip freeze
exec python main.py'''],
dag=dag
)One of the advantages of "Task as Config" is that every job/task is standardized. It is easy to know what a task is doing by just checking several config parameters instead of reading scripts written by different people with different coding styles. Even users without programming skills can achieve this so code (config) review becomes easy too. This is really useful when upgrading versions of components such as Python and Airflow, there could be the problem of compatibility if we keep "Task as Script" and it is expensive to fix and migrate. But by using "Task as Config," we can do this easily and quickly as long as we prepare renderer and code templates. The most important point is, with "Task as Config," we finally succeeded in separating the duty of different staffs in different teams: developers can focus on system and tool development (such as Frey), while users build the batch ingestion pipeline, and management staff are in charge of data and permission management. The days of developers doing tasks for users and management members are long gone.
Frey-plugin
Frey-plugin consists of tools to work with certain scheduling engines. At present, we are using Airflow so we developed various Airflow plugin to do X2Y tasks.
Kubernetes
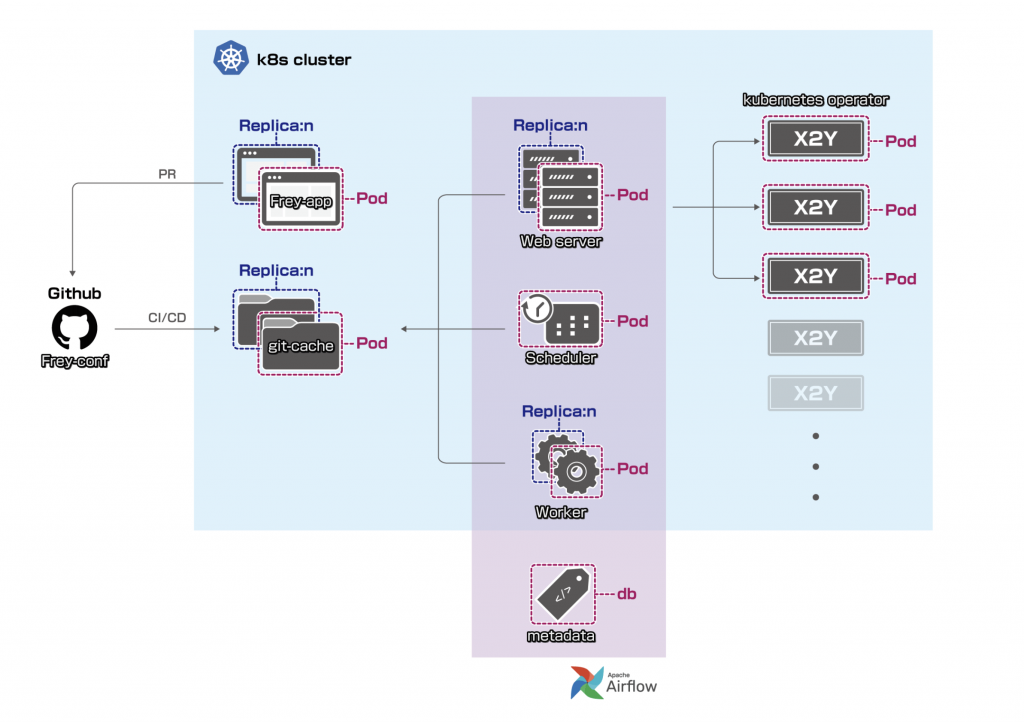
We have Frey's web app and scheduling engine deployed in a K8S (Kubernetes) environment. This ensures:
- High availability
- Easy deployment to dev, staging and prod environments
- Flexible configurations and dependencies
As our scheduling engine is Airflow, we also created docker images for every X2Y type and use KubernetesOperator to launch pods for tasks.
Below is Frey's K8S architecture:
Audit
We send both Frey-app and scheduling engine logs to ElasticSearch.
Notification
Users can choose whether to receive notifications or not when creating tasks. Currently we support Slack and email notifications for almost all user operations and job executions.
Brief comparison
| Frey | Traditional system | |
|---|---|---|
| User | All LINE employeesAuthentication and authorization with customized rules | Experienced engineers and data scientistsNearly no access and permission control |
| Operation | All jobs are managed by users (owners) themselvesMultiple owners are also supportedOperations (CRUD) are all done via a web pageCI/CD to generate real code and deploy to scheduling engineEstimated time to create an ingestion job with one table: 1-5 mins | No clear rules of who manages which jobEveryone has to write code on dev environment and then request code reviewEstimated time to create an ingestion job with one table: 30-60 mins |
| Scalability | Config file and code templatesStandard libraries and toolsEasy to migrate | Scripts in user's own style |
| Security | Separated user permission control for login, connection, and job CRUDCode review before deployOwner based control for data flow operation | Code review before deployAnyone can view and operate any data flow |
| HA | K8S | N/A |
Conclusion and future tasks
We have successfully built Frey, an easy-to-use, self-service batch ingestion system, and as a self-service tool of batch ingestion for LINE staff, Frey is running without downtime (except Hadoop cluster maintenance).
By the end of October 2020, on Frey there are:
- more than 200 users from over 80 LINE-related services
- more than 300 jobs and 1500 tasks running everyday
- more than 6TB data ingested from over 240 connections everyday
With Frey:
- The cost of building mass batch ingestion pipelines has been reduced remarkably
- The duty division of related teams has become more reasonable
- The overall efficiency has increased because Frey automates nearly everything and manual operation is rarely required
Currently, mysql2hive, oracle2hive, cubrid2hive, and hdfs2hive are available on Frey and we are developing mongodb2hive and hbase2hive.
We are planning to support more data storages as both sources and destinations. Also, on Frey-app, we are planning to develop more user-friendly features such as a troubleshooting helper.