
Hi everyone, my name is Detai Xin. I joined the LINE Speech development team for my summer internship during July 2020 to October 2020. The goal of my internship program was to publish the research outcome at a prominent conference. During these three months, I developed and implemented a method for obtaining a disentangled speaker and language representations for cross-lingual text-to-speech synthesis. Our paper "Detai Xin et al., Disentangled speaker and language representations using mutual information minimization and domain adaptation for cross-lingual TTS, ICASSP2021" was accepted by the ICASSP2021 (IEEE International Conference on Acoustics, Speech and Signal Processing).
In this blog I will briefly introduce our research.
Introduction
Text-to-speech (TTS) is a kind of speech technology that can convert language text into speech. For example, the audio of speech assistants like Siri is synthesized by a TTS system.
Cross-lingual TTS synthesis refers to a task that requires the system to synthesize speech of one target language of a speaker. In this research we synthesize Japanese speech for English native speakers and vice versa. This task can be applied in the speech translation system to generate the target language speech of a source language’s native speaker; such as generating English speech for a Japanese native speaker.
The simplest way to accomplish this task is training a TTS model using a bilingual dataset. However, in practice it is difficult to collect such data since it needs many bilingual speakers to get bilingual speech. Therefore this task is often accomplished in a semi-supervised setting by training a multilingual multi-speaker TTS model on multiple monolingual multi-speaker datasets. Generally, such a TTS model is trained by conditioning the popular single speaker TTS model Tacotron2 on speaker embedding and language embedding extracted from acoustic features. After training, the cross-lingual speech can be synthesized by simply replacing the language embedding with the target language's embedding.
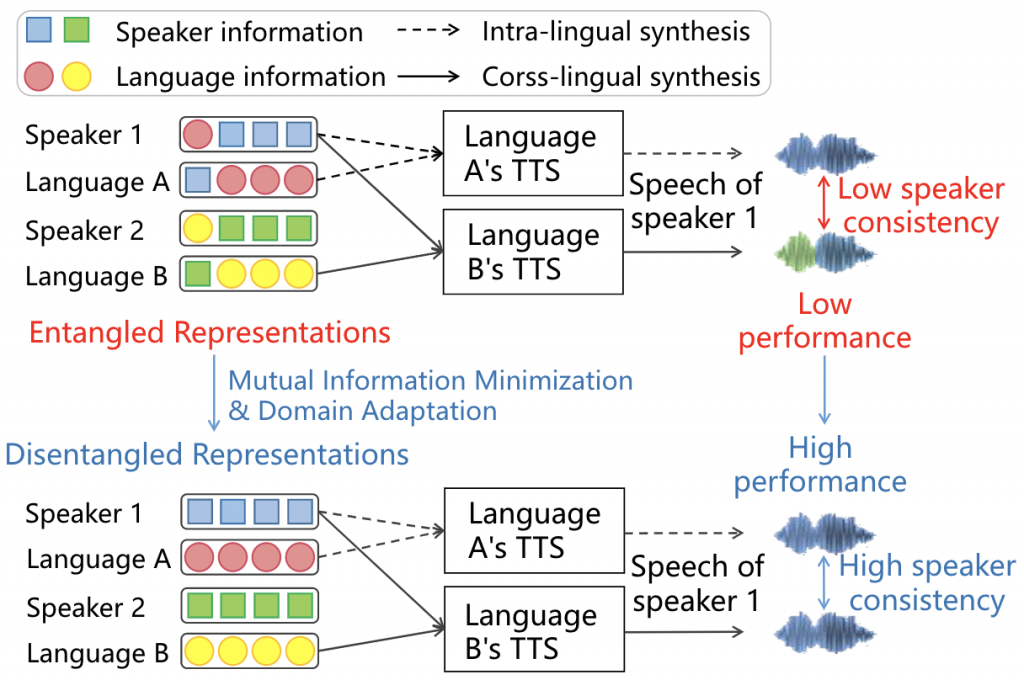
However, in practice replacing language embedding may change the speaker identity and naturalness of the synthesized speech, and also cause performance degradation consequently. We think the reason is that the speaker embedding and language embedding are entangled. As illustrated in the top half of Figure 1, the entangled language representation includes other speaker's information, thus using it to synthesize cross-lingual for other speaker may change the speaker identity.
Thus the goal of this research is solving this problem and obtaining disentangled speaker and language representations.
Proposed method
To tackle the problem of entanglement, we use domain adaptation and mutual information minimization to get disentangled speaker and language representations. As illustrated in the bottom half of Figure 1, by using these two technologies, the language embedding extracted by the proposed method includes relatively few speaker information. In other words, changing language embedding has almost no influence on the speaker identity of the speech.
The embedding extraction module architecture of our proposed method is illustrated below in Figure 2.
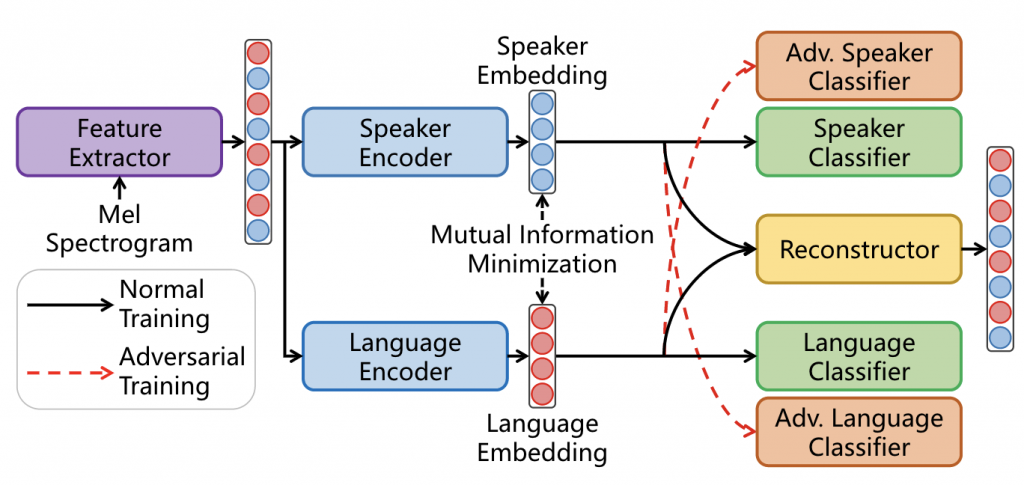
We first generate a fixed-length feature embedding from a mel spectrogram, then use a speaker encoder and a language encoder to extract speaker embedding and language embedding, respectively.
The domain adaptation module includes two normal classifiers and two adversarial classifiers. Take the speaker classifier and adversarial language classifier as an example. The speaker classifier is trained to learn speaker labels from the speaker embedding. The adversarial language classifier tries to learn language labels from the speaker embedding. At the same time we reverse the gradient back-propagated from the adversarial classifier to remove language-related information from the speaker embedding. Similarly, the language classifier and the adversarial speaker classifier force the language embedding to include language information and exclude information related to the speaker.
To enhance the disentanglement between speaker and language embeddings, we further use mutual information minimization. Mutual information (MI) measures the dependence of two random variables from the perspective of information. In our work we use contrastive log-ratio upper bound (CLUB) to approximate and minimize upper bound of the mutual information.
Finally, to ensure there is no information loss during the disentanglement process, we reconstruct the initial feature embedding.
Experimental Result
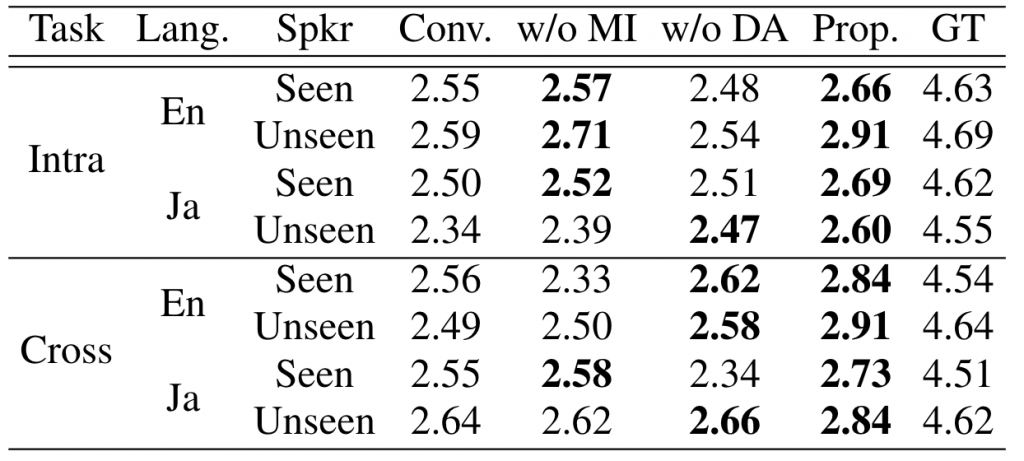
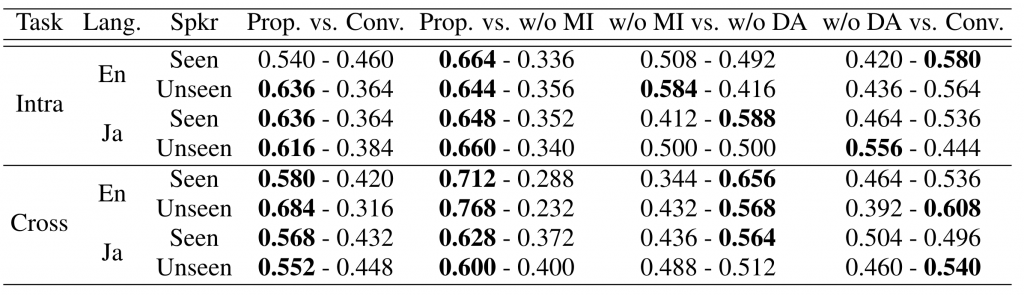
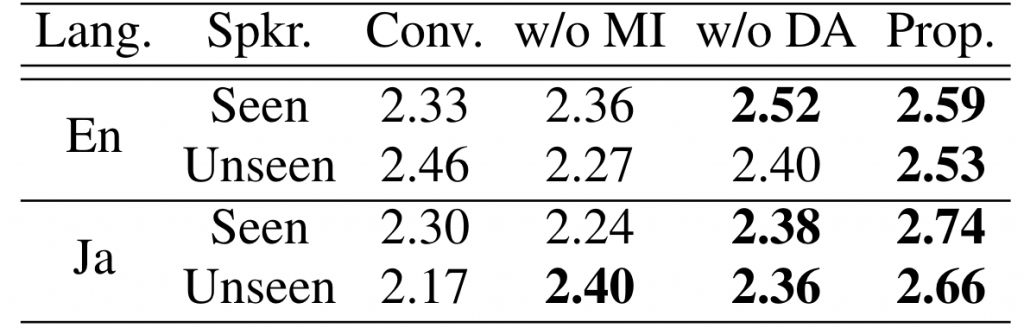
We use the English dataset VCTK (link in Japanese) and the Japanese dataset JVS to do the experiments. A model using domain adaptation only on speaker embedding is used as the baseline model (Conv.). Apart from training the proposed method (Prop.) using domain adaptation and mutual information minimization, we also trained the proposed method without domain adaptation (Prop. w/o DA) or mutual information minimization (Prop. w/o MI) as ablation experiments to evaluate the effect of domain adaptation and mutual information minimization separately.
We evaluate the synthesized speech from three perspectives: naturalness, speaker similarity, and speaker consistency. Naturalness measures the fluency of the speech; speaker similarity measures the similarity of the speaker identity between synthesized and ground truth speeches; in speaker consistency evaluation we ask the rater to evaluate the similarity between the synthesized intra-lingual speech and cross-lingual speech. The results are shown in Table 1, 2, and 3. It can be observed that the proposed model Prop. outperforms the baseline model Conv. on all evaluations.
Final thoughts about the internship
During the internship, I was very excited to discuss my idea with my colleagues and implement the proposed method. It was exciting to wait for the result of the experiment. Although at most of the time I had to work at home due to COVID-19, the kindness and support of my colleagues still made me happy and satisfied about the internship.