
Hello, my name is Moznion and I'm part of the team working on LIVE: a video-based social media service that connects stars and celebrities to their fans.
On LIVE, users can watch their favorite stars participating in programs or performing concerts all in real-time. LIVE is currently available on iOS/Android and on PC web browsers, and quickly gaining popularity.
In this blog post, I'd like to explain how we handle large amounts of consecutive requests sent on LIVE.
Introduction

On the iOS/Android version of LIVE, we have a feature that lets users tap on a "heart" to send support to the current broadcast that they are watching (No. 1 on the screenshot above). Users, or viewers in this case, can tap on the heart as much as they want, and the total number of hearts sent is represented on the screen in real-time (No. 2 on the screenshot above). Broadcasters can directly see how much support they are getting from their fans, and viewers can feel a sense of solidarity with other viewers while they immerse themselves in the experience.
Our engineers have a separate name for these "hearts." We call them "loves," and that is what I'll refer to them as in this blog post.
As you can imagine, live broadcasts from popular idols receive a huge surge of "loves" instantaneously and require the back-end to efficiently distribute these requests so that the service can maintain itself. In the following sections of the post, I'll elaborate on how we implemented a counter system on LIVE to have high capacity and near-instantaneous reactivity, with the ability to handle the amount of "loves" sent by a massive amount of users.
Architecture
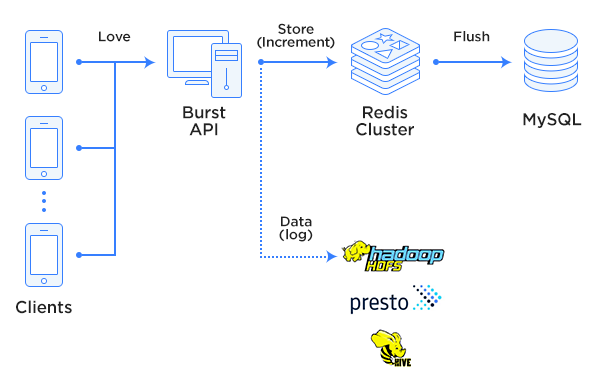
The architectural structure of our system can be seen below. The following sections will go into each part of the diagram in better detail.
First step
One way to provide a stable service is to reduce the number of requests. This method is a surefire solution in most cases.
For example: if each press on "love" sends a request, and the server must handle and return every single one of those requests, that would waste too much resources and would be difficult to scale. In some situations, it might cause a stall on the network class. That would be bad news.
Because of the reason above, it seems fairly obvious why the solution of grouping several requests to reduce the overall number of requests would seem like a good idea. One little idea we had was to have the client buffer "the number of times "loves" were sent in a certain time window" and only send the accumulated number of results when it exceeds that buffer. The server would then receive that number and reflect it on the counter.
What we ended up doing with LIVE was to have the client buffer the timestamps from the "number of times "love" was tapped on a certain point of time of the video" as a list instead of a pure count, successfully reducing the number of requests from each viewer. The "timestamp list of taps" is also used later on for analysis. More on this later in the post.
One caveat to this method is that you have to be ready for users that may exploit the system. If a user with malicious intent sends a massive amount of counts in a single request and if the server receives and tries to process that request at face value, it would spell doom for all of us. That is why LIVE has also prepared several countermeasures to combat these kinds of attempts.
Using high-speed storage
Live broadcasts tend to attract more viewers, or in other words more concurrently active users. More viewers also mean more "love" requests.
This is why LIVE chose to place the counter in an in-memory-based KVS, efficiently handling IO with access increments. This method was better than storing the "love" count on RDB (LIVE uses MySQL) and increasing it each time there was a "love" request, which would mean accessing the DB each time there was a request.
LIVE uses the clustering feature that has been available since version 3 of Redis, and the "love" counter uses the same Redis Cluster. As seen in the specifications here, Redis Cluster is a high performance, high capacity, and highly scalable in-memory KVS. LIVE uses Redis Cluster for other purposes as well.
Our internal process works like this: When the size of the timestamp list is acquired by request, the outgoing Redis "love" counter is increased with INCRBY by the same amount.
When the live broadcast ends, the counter is flushed to MySQL from Redis and then deleted from Redis. This is because we don't need the data to be perpetual on Redis. Perpetual data can be handled with RDB, and Redis is used to handle data that is volatile and requires high throughput (such as cache data or "love," the topic of this post).
While this is slightly off-topic, we put name spaces in front of entry keys when we use Redis. For example: "[service-name]|[phase]|[entry-key]" ("phase" represents the current stage of development. If it's a real environment, we put "release," and if it's a staging environment, we put "staging."). This benefits us in two ways: we can immediately tell what the service is and what phase it's in by just looking at the key name, and it also protects other services from being affected if we mistakenly mix up entries from different services or phases.
Using a simple data structure
Using a simple structure for both stored data, and data stored on requests is required for high throughput. In-memory KVS with complex data structures not only make it difficult to store them, but they also complicate extracting or referencing data.
That led to the decision to design the structure in a way that everything we need can be achieved by a simple set of commands, with Redis only used to create a simple counter. Values are updated with the INCRBY command, acquired with the GET command, and removed with the DEL command.
Choosing an appropriate data structure is crucial.
For example: If "loves" on a certain broadcast are used for more complicated uses such as ranking "number of transmissions per viewer," it's simpler and more efficient to match a sorted set kept on Redis to a broadcast and score the number of "loves," set member as a viewer ID, and use ZRANGE or ZREVRANGE to acquire rankings than ranking directly on the application through a simple counter.
In conclusion, using the simplest data structure that is available for use with each domain is an integral part of maintaining high throughput.
Data analysis
Whenever the "love" count increases, LIVE sends an analysis log to the company HDFS storage using Fluentd. These logs contain various data such as "Where users tap "love" on this video." These collected logs are then analyzed through Hive or Presto and used to further improve the quality of our service.
While I did say that using a simple data structure is required for improving throughput, at the same time we do still want to analyze the data. However, trying to achieve both may either put unnecessary stress on parts of the system or cost us more resources. That's why we decided to have a logger (Fluentd in our case) working parallel with the main process to collect data, store it on HDFS, and then have a separate component analyze the stored data.
When the component handling the actual service and the one analyzing data is divided in this way, the heavy load put on the system during data analysis won't affect the actual service, and vice versa. The analysis results are pulled on-demand when we send a request to the data analysis component when we need it. This method works in our case since LIVE does not require the data to be analyzed in real-time.
Server distribution
LIVE operates on distributed servers. One is used for common API and the other has components to handle heavy loads that may be put on the system due to "loves." We call the API server that handles heavy loads the Burst API server.
If we used one API server to handle all these tasks, heavy loads on certain components could affect other components, and in the worst case scenario could bring the entire service down. We prevent this by having a separate server for components expected to be put under heavy load.
If we experience a heavier load than we expected, we can expand the server and scale up or scale out. This allows for more flexibility so that even if there is a sudden load while the application engineer is away, the engineer in charge of infrastructure or operation can handle the situation on their own.
Closing words
To sum up,
- Minimize the number of requests. Be prepared for exploits.
- Use high-speed storage where needed.
- Use a simple data structure for high throughput.
- If you don't need real-time data analysis, save and analyze the data on a different component.
- Place components that may experience heavy loads on a separate server.
This concludes my post about how we handle large amounts of consecutive requests on LIVE.
You too can "love" broadcasts by downloading the app on an iOS/Android device, and logging in with your LINE account. Try it out!
LINE LIVE (Japanese) LINE LIVE on the App Store (Japan only) LINE LIVE on Google Play (Japan only)
LINE is always looking for engineers interested in handling video and consecutive requests. Join us!
Server-side engineer [LINE GAME] [Family Apps] [LINE Pay] (Japanese) Server-side engineer [LINE Platform] (Japanese)