
Production-grade systems usually consist of multiple interconnected components that depend on each other. Popularization of the microservice architectures in recent years has led to an increase in the number of components and their interconnectivity. To protect each component from overloading and guarantee overall system quality of service, rate limiters can be used.
Many articles and tutorials discuss server-side rate limiters for a service running on a single host. In this article, I will mainly cover client-side rate limiters for high-throughput distributed systems. The topic is inspired by the 2020 LINE New Years Campaign system development. This campaign started at the time of one of the highest traffic periods during the year for LINE services – at midnight on January 1st. One of the challenges we faced was avoiding putting more load on internal services than they could handle while preserving a good user experience.
Concept and terminology
Systems that expose endpoints that might suffer from overloading often implement some kind of server-side rate limiting technique in order to protect themselves from excessive use. The client-side usually needs all of its requests to be properly processed, therefore it is in the interest of the client to properly obey the rate limit set by the server-side.

"Client-side" and "server-side" terms might be confusing within complex systems as one component can act both as a client and a server depending on the point of view. In this article I will use the following terms:
- Provider (of API) - part of a system that accepts requests from a consumer of an API.
- Consumer (of API) - part of a system that makes requests to a provider of an API.
- Provider-side rate limiter – rate limiter on the provider side, limiting the rate of incoming requests.
- Consumer-side rate limiter – rate limiter on the consumer side, limiting the rate of outgoing requests.
- Rate limit – allowed quantity of requests within a particular period of time.
Consumer-side and provider-side rate limiting
Even though consumer-side and provider-side rate limiters are similar in concept, there are some differences. The main difference is in the behavior when the rate limit is reached. While provider-side rate limiter implementations often just reject requests, consumer side implementations have a variety of approaches they can use:
- Wait until it is allowed to make requests again. This approach makes sense in applications that make requests as a part of an asynchronous processing flow.
- Wait for a fixed time period and timeout the request if the rate limiter still does not let it through. This approach can be useful for systems that directly process user requests and depend on a downstream API which is being rate limited. In such a situation it is only acceptable to block for a short period of time, which is often defined based on the maximum latency promised to the user.
- Just cancel the request. In some situations it is not possible to wait for the rate limiter to allow a request to go through, or processing each request is not critical for the application logic.
Another challenge in implementing a rate limiter for high-throughput distributed systems is making sure that the rate limiter itself can handle the number of requests being processed by the system. In the following sections, I will discuss several ways to implement a rate limiter for distributed systems.
Rate limiters for high-throughput distributed systems
A modern microservice may be deployed as many independent instances. This improves reliability and allows for horizontal scaling of the system when necessary.

Since all instances of the service do the same kind of processing, all of them use the same API provider and therefore must share a rate limit for this provider. Some coordination is needed between consumer instances in order not to exceed the allowed rate limit.
Rate limiters with centralized storage
One of the most popular ways to coordinate the utilization of a rate limit among multiple consumer instances is by using centralized storage. In the simplest implementation, one counter per API provider is stored. The counter is increased each time a request is made to the API provider and reset when one second elapses. At any given time, the current value of the counter represents the number of requests made within the current second and can be used to determine if the rate limit has been reached.
There is an official manual from Redis Labs explaining how to implement a simple rate limiter with Redis.

Unfortunately, even though this is a simple and efficient solution for low throughput systems, it does not scale well. By design, a single counter in Redis will always be stored on one node. If your consumer makes too many requests to a single provider, Redis might become a bottleneck of the system.
Moreover, having a single node handling all rate limiter counting becomes a single point of failure. Even with replication set up it is not the best solution as failover does not happen instantly and all API consumers will be blocked until the failover process is completed.
This solution requires one access to Redis per API request which inevitably increases the total latency of each request. Redis is one of the fastest storage solutions available but we need to take network round-trip time into account.
For the 2020 LINE New Year's Campaign we wanted to safely handle more than 300,000 requests per second of rate-limited traffic, so we decided not to go with a centralized storage solution.
Distributed in-memory rate limiters
As an alternative to the centralized storage approach, we proposed a distributed in-memory rate limiter. The idea is to split the rate limit of a provider API into parts which are then assigned to consumer instances, allowing them to control their request rate by themselves.

To implement such an approach each consumer instance has to know its own "partial" rate limit. If the traffic is well-balanced between consumer instances it can be calculated this way:
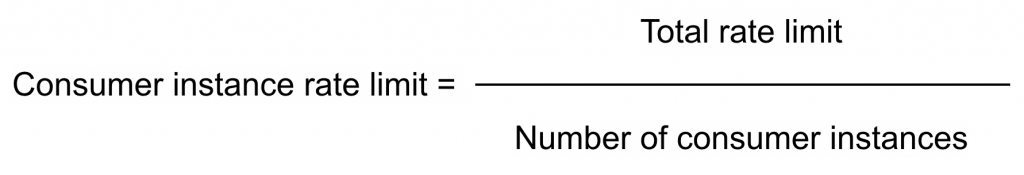
In real life, both of these variables can change while the application is running. For example, the consumer instance quantity may change in the event of server failure or a scaling operation. The total rate limit may change in the case of availability issues on the provider side. This is why we introduced another entity to our system – a configuration server. It provides a total rate limit and the number of consumer instances for each API provider and allows an operator to edit these variables without an application restart.

We used Central Dogma[1] for this purpose. Consumer instances are initialized with data from Central Dogma at startup and are updated when the configuration server notifies about a change.
Each API consumer instance has its own rate limit and the sum of all requests to a given API provider should not go over the total rate limit during a time window. This means that all consumer instances should be well synchronized and agree on the time at which a given window starts and ends. To solve this problem we are using a time window strictly linked to the wall clock. Each time the actual wall clock second changes, the request counter is reset on each consumer instance.
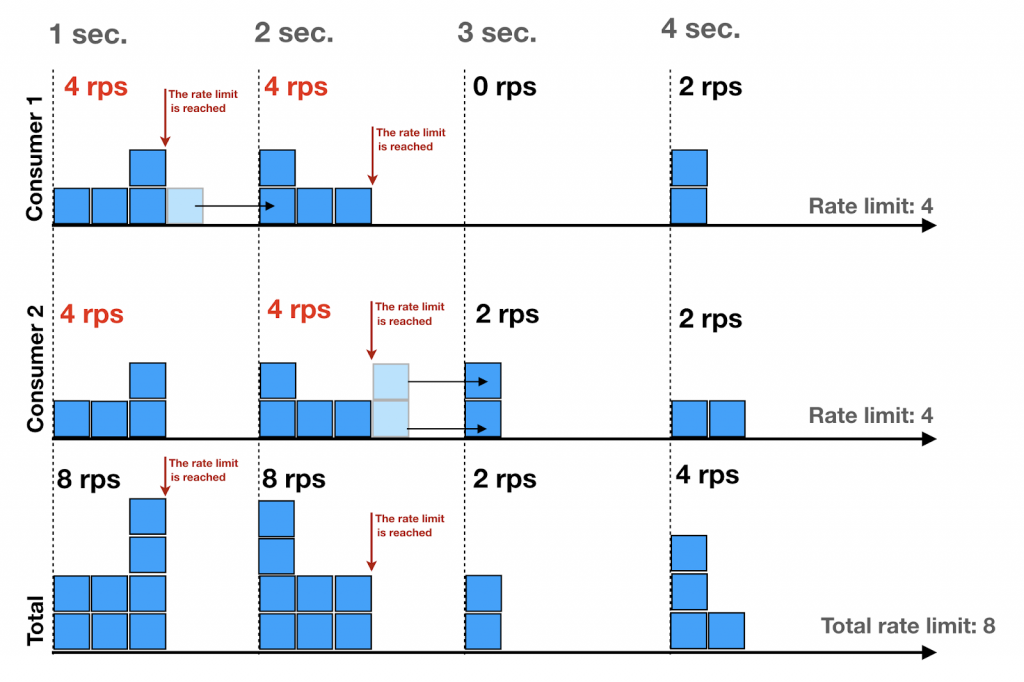
It is important to remember that for this to work, consumer server clocks should be synchronized using Network Time Protocol, though doing that does not guarantee perfect synchronization. The complexity of the network can cause errors of 100 ms and more in the worst cases.
Rate limiter approach comparison
| Centralized storage | Distributed in-memory |
| ✅ Requests do not have to be balanced | ✅ Able to provide high throughput |
| ✅ Rate limit can be fully used up | ✅ Almost no latency increase by the rate limiter |
| ❌ Increases latency due to request to DB | ❌ Unequal distribution of traffic can cause rate limit to be not utilized fully |
| ❌ Does not scale well | ❌ System clock synchronization is important |
| ❌ Single point of failure | ❌ Need additional configuration system to manage a number of consumer instances |
Non-blocking high-throughput distributed rate limiter implementation
In this section, I will introduce one way in which a non-blocking high-throughput distributed rate limiter can be implemented.
Non-blocking rate limiter implementation
Lately the reactive programming paradigm has been gaining popularity on the server-side. Blocking implementations are generally wasteful for applications that deal with I/O operations such as database requests or network calls. The system for the 2020 LINE New Year's Campaign was developed as a fully non-blocking application with the use of Armeria[2], an asynchronous web service framework for Java, and RxJava2, an asynchronous reactive stream processing library.
It made sense to implement the rate limiter using a non-blocking approach in order to avoid using too many threads while waiting for I/O.
Here is the interface we used for the rate limiter implementation (Kotlin):
interface ApiRateLimiter {
/**
* Acquire a permit for request from rate limiter.
* @param maximumWaitForMillis Maximum time to wait for rate limiter to open in milliseconds.
* @return Completable that will complete when permit is acquired
* or Completable.error(RateLimiterTimeoutException) if rate limiter was closed
* for longer than maximumWaitForMillis.
*/
fun acquire(maximumWaitForMillis: Long): Completable
}The acquire method returns an RxJava2 Completable that completes when the rate limiter permits the request to be executed. The method also accepts a maximumWaitForMillis argument which determines the maximum time that rate limiter can wait.
If the rate limit was already reached for the current second, the program uses RxJava2 to schedule another call to acquireInternal recursively for the time when the next second will start. The reference implementation below shows a basic implementation of such rate limiter logic.
/**
* Acquire a permit for a request from the rate limiter.
* @param maximumWaitForMillis Maximum time to wait for the rate limiter to open in milliseconds.
* @param beforeWaitedForMillis Accumulative time that has been spent waiting for the rate limiter to open
* up until now now. Due to the recursive nature of this function,
* beforeWaitedForMillis is used to account for previously waited time.
* When this function is called for the first time the value of this parameter
* should be 0L (because no time has been waited yet).
* @return Completable that will complete when the permit has been acquired
* or Completable.error(RateLimiterTimeoutException) if the rate limiter was closed
* for longer than [maximumWaitForMillis].
*/
private fun acquireInternal(
maximumWaitForMillis: Long,
beforeWaitedForMillis: Long
): Completable {
// Each call, including recursive ones gets a new rate limit, because it might be changed while waiting.
val currentLimit = consumerInstanceRateLimit
val waitForMillis = tryToIncreaseCounter(clock.instant(), currentLimit)
val totalWaitForMillis = beforeWaitedForMillis + waitForMillis
return when {
// open rate limiter
waitForMillis == 0L -> {
Completable.complete()
}
// waited too long for rate limiter to open, throwing error
maximumWaitForMillis <= totalWaitForMillis -> {
Completable.error(RateLimiterTimeoutException())
}
// wait for rate limiter to open and recursively try to acquire again
else -> Completable
.complete()
.delay(waitForMillis, TimeUnit.MILLISECONDS)
.andThen(Completable.defer {
acquireInternal(maximumWaitForMillis, totalWaitForMillis)
})
}
}
/**
* Holds the epoch second for which the limit is being counted.
* Checking [rateLimitedSecond] and increasing [counter] is done in a critical section
* in [tryToIncreaseCounter]. They must be checked and updated together, atomically.
*/
private var rateLimitedSecond: Long = clock.instant().epochSecond
/**
* Holds count for the current epoch second.
* Checking [rateLimitedSecond] and increasing [counter] is done in a critical section
* in [tryToIncreaseCounter]. They must be checked and updated together, atomically.
*/
private var counter: Long = 0
/**
* Try to increase the rate limiter counter.
* If the current rate limiter's fixed window has ended, start counting for the next one.
* If we are still within the current rate limiter's fixed window, try to increase the counter and if the
* rate limit is hit, calculate how many milliseconds until the next fixed window starts.
*
* @return 0L - if the counter was increased.
* amount of milliseconds until the next fixed window - if the rate limit has been reached.
*/
@Synchronized
fun tryToIncreaseCounter(now: Instant, currentLimit: Long): Long {
return if (rateLimitedSecond == now.epochSecond) {
if (counter >= currentLimit) {
val nextSecondStart = now.truncatedTo(ChronoUnit.SECONDS).plusSeconds(1)
nextSecondStart.toEpochMilli() - now.toEpochMilli()
} else {
counter++
0
}
} else {
rateLimitedSecond = now.epochSecond
counter = 1
0
}
}Before every rate-limited API call, we need to call the acquire method and wait for the returned Completable to complete.
acquire(MAX_TIMEOUT)
.andThen(Single.defer { someService.someApiCall() })
.map { ... }In the example above I use the RxJava andThen method to perform an API call as a sequential action after the rate limiter is acquired.
Usage of non-blocking rate limiter
API usage can be separated into two categories based on the nature of the application issuing the requests.
- Immediate response required: for example, if API called as a part of HTTP request processing with fixed timeout.
- No immediate response required: for example, if a request is made as a part of message processing of some stream processing application based on technology such as Apache Kafka.
In the first case one can use the maximumWaitForMillis argument in the above implementation in order to limit waiting time when the rate limit has been reached.
The second case makes it possible to fully take advantage of a non-blocking rate limiter implementation. A concrete example of a task that can be implemented this way is the Onedari (おねだり, Japanese expression for pleading) feature of the 2020 LINE New Year's Campaign. This feature allows a user to ask a friend for a New Year Campaign sticker by sending a specially formatted LINE message.
The application in this case uses internal LINE API to send the message to a particular user. To implement this, we accept an Onedari request from the sender, produce an event to the Onedari Kafka topic and immediately respond to the sender indicating success. The consumer of the Onedari Kafka topic does not have to worry about a user waiting for the response. It can process the events asynchronously and call the internal API while obeying its rate limit.
Possible improvements
Above I described a straightforward implementation for a high-throughput distributed rate limiter based on a fixed-window algorithm. There are some improvements which can be made which I will discuss in this section.
Uneven distribution of requests in time
The first problem is that there is no control over the request rate distribution within the time window. Look at the following picture, which shows a typical request distribution when using the rate limiter implemented as proposed in this article.

You may notice that most requests are issued at the beginning of the second and after the rate limit is reached no requests are made.
Formally, the consumer from the picture obeys the rate limit. With a rate limit small enough it does not usually cause any problems. If the rate limit is high, such peaks at the beginning of the second can cause a significant load on the API provider.
One way of solving this problem is to use request distribution data from previous time windows and introduce short delays in order to improve distribution. There are various ways to do this, but the basic principle is to use historical data and some kind of proportional-integral-derivative controller.
Uneven distribution of requests between instances
Another potential problem is when load is not well balanced and a subset of consumer instances is generating more requests to a provider API. If this is a concern in your application, you may want to split the rate limit according to the need of each consumer instance. It requires a separate coordination service that will observe rate limit usage and redistribute quotas in real time. One such system is Doorman, developed by the YouTube team at Google.
Conclusion
We successfully developed and applied a high-throughput distributed rate limiter for the 2020 LINE New Year's Campaign. At that time the system experienced a very high load and the rate limiter together with asynchronous processing using Kafka helped to serve all users at a high capacity without overloading LINE internal services.
Before using it in production, we performed a load testing of the rate limiter on 96 consumer instances. It worked perfectly for rate limits ranging from as low as 10 requests per second to as high as 2 million requests per second. The described approach proved to be production ready and scale well. We are planning to improve it and use it for other systems in LINE.
Footnotes
1. ^ Central Dogma - an open-source highly-available version-controlled service configuration repository based on Git, ZooKeeper, and HTTP/2.
2. ^ Armeria - Armeria is an open-source asynchronous HTTP/2 RPC/REST client/server library built on top of Java 8, Netty, Thrift and gRPC.