
Machine learning (ML) is getting more and more popular these days. You probably are using it already at your work, or have been encouraged to have a go at it. Thanks to its popularity, we see more tools and frameworks for machine learning emerging. Not only that, anyone can learn linear regression, logistic regression as well as various deep learning algorithms such as Perceptron, Adaboost, Random Forest, Support Vector Machine and XGBoost. Although we are seeing growth in tools and frameworks for learning, there are not enough tools or frameworks for operating machine learning modules. Which brings me to introduce a machine learning management platform, Rekcurd, we use for the LINE's AI platform, Clova.
Machine learning
Adapting machine learning consists of the following two tasks:
- Building a machine learning model
- Distributing a machine learning model
Building a machine learning model
Building a learning model consists of tasks such as collecting data, cleansing data, designing features, choosing algorithms, network design (for building deep learning models), tuning parameters and evaluating machine learning. The tasks are listed in detail below. Machine learning engineers and data scientists put a great effort in each task.
- Data
- Collection (supervised learning, unsupervised learning, distant supervision)
- Cleaning/Cleansing (outlier filtering, data completion)
- Features
- Preprocessing (morphological analysis, syntactic analysis)
- Dictionary (wordnet)
- Training
- Algorithms (regression, SVM, deep learning)
- Parameter tuning (grid search, Coarse-to-Fine search, early stopping strategy)
- Evaluation (cross validation, ROC curve)
- Others
- Server setup
- Versioning (data, parameters, model and performance)
In the last few years, we've seen a growth in machine learning (Machine Learning) tools and frameworks. If you are Python developer, you can use machine learning libraries such as scikit-learn, gensim, Chainer, PyTorch, TensorFlow and Keras. To monitor learning progress or to create reports, Jupyter Notebook, JupyterLab, and ChainerUI, TensorBoard can help you out.
Google just recently announced a tool for setting up a development environment, kubeflow, a machine learning platform that can be boot on Kubernetes and that provides a parallel computing environment. Thankfully, we are seeing more of these tools and frameworks to help machine learning engineers and data scientist.
Deploying a machine learning module
Deploying a machine learning module requires numerous tasks; making a machine learning module into a service, implementing high availability in services, integrating with the legacy system, updating machine learning models or services, monitoring services. Based on these tasks, frameworks for deploying machine learning modules shall provide the following features:
- High Availability
- Management
- Uploading the latest model
- Switching a model without stopping services
- Versioning models
- Monitoring
- Load balancing
- Auto-healing
- Auto-scaling
- Performance/Results check
- Others
- Server setup
- Managing the service level (e.g. development/staging/production)
- Integrate into the existing services
- AB testing
- Managing all machine learning services
- Logging
Tasks related to server are usually handled by infra engineers or server-side engineers, but this isn't the case for machine learning. There are times when pre-processing or post-processing specific for a machine learning module is required. So, to serve a machine learning model, we need to involve machine learning engineers. Sometimes, machine learning engineers take over the wheel for serving machine learning modules, but if you think about it, they are not server experts; service quality can fluctuate depending on engineers' competency. Also, repetitive tasks on servers setups, machine learning module maintenance and operation steal time on building the model itself, from machine learning engineers. We can give you a long list of other possible problems.
An option to solve these issues is TensorFlow Serving, with which you can automatically deploy TensorFlow models to gRPC services. But, with TensorFlow, we couldn't include pre-processing or post-processing in services, and machine learning models had to be TensorFlow models (July 2018). Our requirements couldn't be satisfied; we wanted to contain machine learning model together with pre-processings and post-processings serving our needs in a set, and also wanted to deploy models built with scikit-learn or gensim. To satisfy all our requirements, we decided to build our own platform, Rekcurd, with Kubernetes, for operating and managing our machine learning module.
What is Rekcurd?
Rekcurd is a framework for serving machine learning modules. Its characteristics are:
- Easy to serve machine learning modules
- Easy to maintain and run machine learning modules
- Easy to integrate a machine learning module on a legacy system
- Compatibility with Kubernetes (Rekcurd works on Kubernetes, too!)
Clova's platform for serving machine learning module
Clova's machine learning service platform is structured as illustrated below. It uses both Rekcurd and Kubernetes.
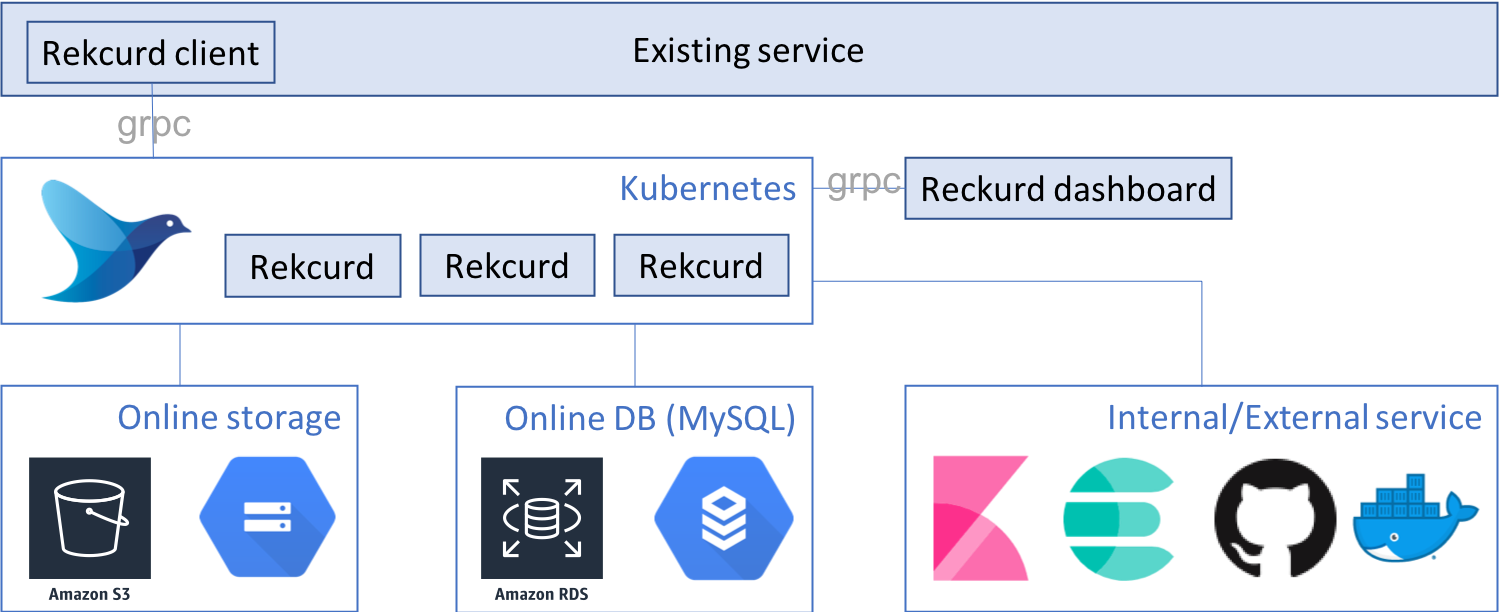
The platform consists of the following components. On this post, we'll call the machine learning module a Rekcurd application, the web service for the machine learning model a Rekcurd service, and the container created for the implementation of high-availability, a Rekcurd Pod.
- Rekcurd
- Kubernetes
- Load balancing - nghttpx
- Rekcurd dashboard
- Rekcurd client
- Logging - fluentd-kubernetes
- Docker registry x Git repository
- Online storage
- MySQL
Rekcurd
Rekcurd is a gRPC micro-framework. By injecting a machine learning module into the template, you can turn the module into a gRPC micro-service. Using Rekcurd is similar to using Web API framework such as Django and Flask. Speaking at code level, you need to make an implementation class of the PredictInterface class of Rekcurd. The gRPC specification is defined in the Rekcurd repository, so don't worry if you are unfamiliar with gRPC. You can easily setup a gRPC server with Rekcurd.
The input parameter of the predict() method can be a string, bytes, list[int], list[float] or list[string]; these are common data types used for machine learning inputs. To provide additional information such as device information or user ID, use the optionparameter, which is of a dictionary type. By the way, there is no limit to depth in dictionaries. To learn more, check out details here.
class Predict(PredictInterface):
def __init__(self):
super().__init__()
self.predictor = None
self.load_model(get_model_path())
def load_model(self, model_path: str = None) -> None:
assert model_path is not None,
'Please specify your ML model path'
try:
self.predictor = joblib.load(model_path)
except Exception as e:
print(str(e))
os._exit(-1)
def predict(self, input: PredictLabel, option: dict = None) -> PredictResult:
try:
label_predict = self.predictor.predict(
np.array([input], dtype='float64')).tolist()
return PredictResult(label_predict, [1] * len(label_predict), option={})
except Exception as e:
print(str(e))
raise eKubernetes
Kubernetes is a well-known tool for managing containers, so I won't go into the details of it, but let me just list out its features to convince you why Kubernetes is a good tool:
- Rolling update
- Auto-healing
- Auto-scaling
- Service level (development/staging/sandbox/production) management
- Service operation control - Not running Pod with different service level on the same node, Not running the same Pod on the same node
Rekcurd supports Kubernetes. You can build a strong machine learning service platform if you combine the two. Building your own Kubernetes module can be done using services such as Google GKE or Amazon EKS or Rancher. To learn about setting up Kubernetes clusters with Rancher, see Rancher's documentation or Rekcurd's.
Load balancing - nghttpx
To access the inside of Kubernetes from outside Kubernetes, we use Ingress. The first thing to do is to allocate DNS (Example: example.com) on all or some nodes of Kubernetes cluster. And then set the DNS subdomain with the name and ID of the machine learning module built with Rekcurd, like the following. This endpoint, when called, accesses our machine learning module through the Rekcurd client which we will look into details later.
http://<app-name>-<service-level>.example.com
Subdomain name is assigned as the application access point. We use nghttpx ingress controller as a load balancer. nghttpx supports HTTP2; nghttpx ingress controller is able to handle HTTP2 requests to port 80. However, the nginx ingress controller in the official repository of Kubernetes does not support HTTP2 at port 80 — it does from nginx v1.13.10 — so, our only option was to use nghttpx ingress controller.
Rekcurd dashboard
Rekcurd-dashboard is connected to the Rekcurd part we discussed earlier. You can manage all Rekcurd services on the dashboard; you can access Kubernetes, manage Rekcurd services that run on Kubernetes, and many other tasks as listed below:
- Uploading a machine learning model
- Versioning a machine learning model
- Change the loading model of a machine learning module
- Evaluate and visualize machine learning model performance (work in progress)
- Connect to Kubernetes and run Rekcurd
One of the good points of having a dashboard, to name a few, are having a centralized place for machine learning model management, being able to change machine learning models easily and being able to run Rekcurd on Kubernetes. Although, we still have remaining problems and improvements to be resolved. For example, Rekcurd-dashboard v0.2.0 is yet to support performance evaluation, evaluation visualization, a monitoring service for checking service status and CPU, memory usage, like Kubernetes dashboard does, and user authentication. We are looking forward to have these features on the dashboard.

Rekcurd client
Rekcurd-client is an SDK for connecting to Rekcurd. Since Rekcurd uses gRPC, we can have an SDK in a preferred programming language automatically generated, based on the gRPC specification. Rekcurd-client becomes an extension of a Python SDK generated automatically based on the gRPC specification. To access Rekcurd on Kubernetes, we use the client like the following.
logger = SystemLogger(logger_name="drucker_client")
domain = 'example.com'
app = 'drucker-sample'
env = 'development'
client = DruckerWorkerClient(logger=logger, domain=domain, app=app, env=env)
input = [0,0,0,1,11,0,0,0,0,0,
0,7,8,0,0,0,0,0,1,13,
6,2,2,0,0,0,7,15,0,9,
8,0,0,5,16,10,0,16,6,0,
0,4,15,16,13,16,1,0,0,0,
0,3,15,10,0,0,0,0,0,2,
16,4,0,0]
response = client.run_predict_arrint_arrint(input)Logging - fluentd-kubernetes
For logging, we use fluentd-kubernetes, an official Kubernetes support system provided by Fluentd. Have fluentd-kubernetes run on Kubernetes, then you can send standard output and errors of all pods on Kubernetes to any server. With Clova, we send Rekcurd logs to the Kibana & ElasticSearch server.
Docker registry x Git repository
When managing services with Kubernetes, services are updated generally by updating the container image, and users are expected to be capable of handling container images. However, since Rekcurd provides a basic container image for you, users are not required to know how to make container images, in order to provide services on Kubernetes. When the container is ran, the Rekcurd code is pulled from the Git repository to run the service. 'git pull' via SSH is also available. Since Rekcurd Pod mounts the '/root/.ssh' of a Kubernetes node, storing the ssh key in the Kubernetes node will allow the pod to access Git using ssh.
Online storage
A machine learning model is stored on online storages such as AWS EBS, GCS or WebDAV. Structure-wise, Rekcurd Pods mounts a Kubernetes node (default: /mnt/drucker-model/); if you mount an online storage on the directory in a Kubernetes node, all pods can mount the online storage. This is how all machine learning services share the machine learning model.
MySQL
MySQL manages allocating machine learning models to be loaded by Rekcurd. In other words, Rekcurd refers to MySQL to identify which machine learning model to load. On Kubernetes, pods are removed in the event of errors or updates and new pods are ran. So, the point is, keep the parameters outside of Pod.
Managing machine learning modules
I'll briefly show you how you manage machine learning modules on the dashboard. For details on setting up Rekcurd & Kubernetes, please check out the official documentation.
- Accessing the dashboard
- Adding a Kubernetes host
- Running a new machine learning model on Kubernetes
- Adding and changing a machine learning model
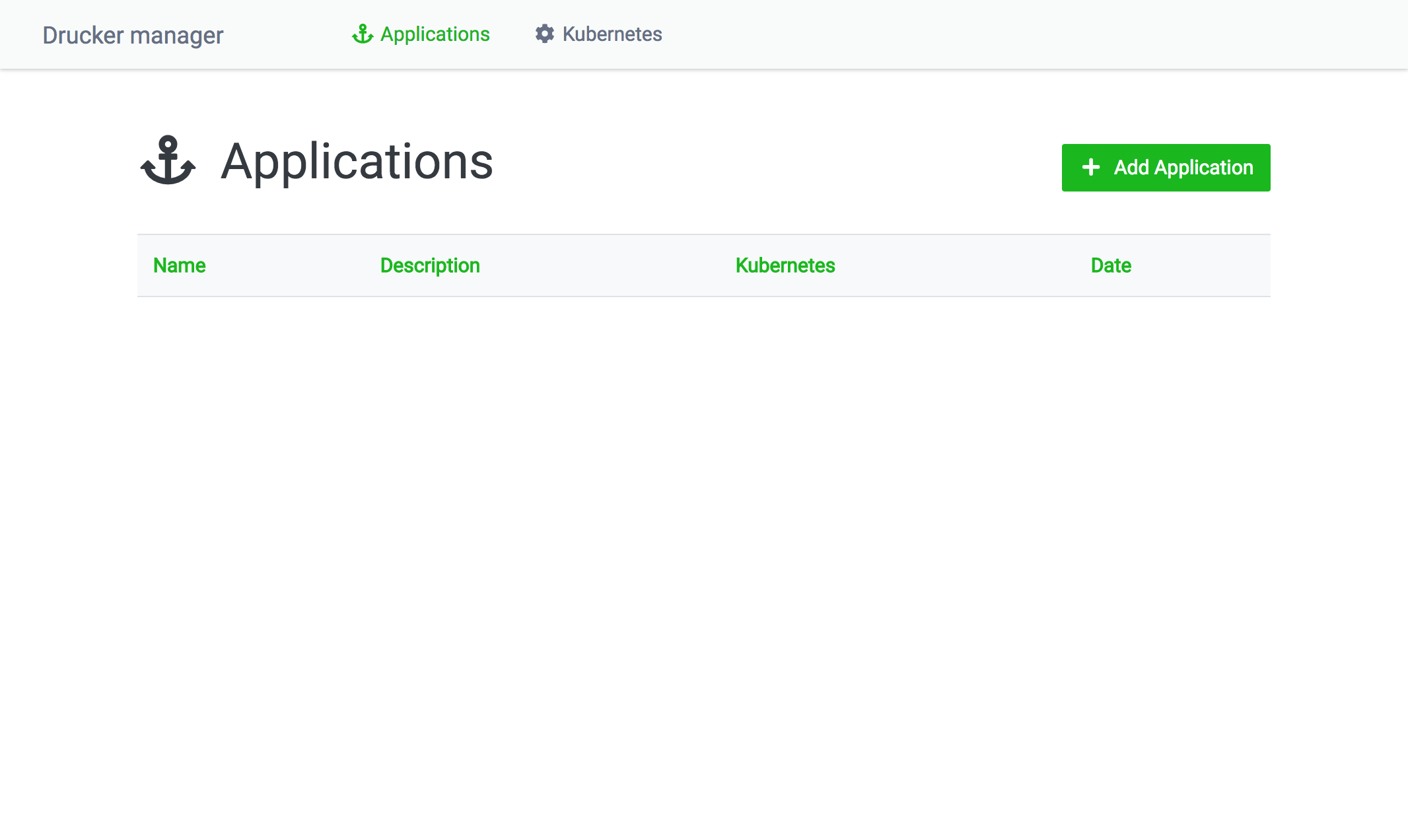
Accessing the dashboard
After running Rekcurd-dashboard, open up http://localhost:8080/ to access the dashboard. The first screen you see is a list of Rekcurd applications that are managed by the dashboard.
Adding a Kubernetes host
To display a list of Kubernetes clusters, click the Kubernest menu at the top on Rekcurd dashboard. The Add Host button will take you to the registration page for adding new Kubernetes clusters, while the Sync All button will send a search request to the Kubernetes clusters on the dashboard to obtain the information of the Rekcurd services running. Synchronizing is to keep the information on Rekcurd dashboard up to date, because you can operate on Kubernetes without using Rekcurd-dashboard.
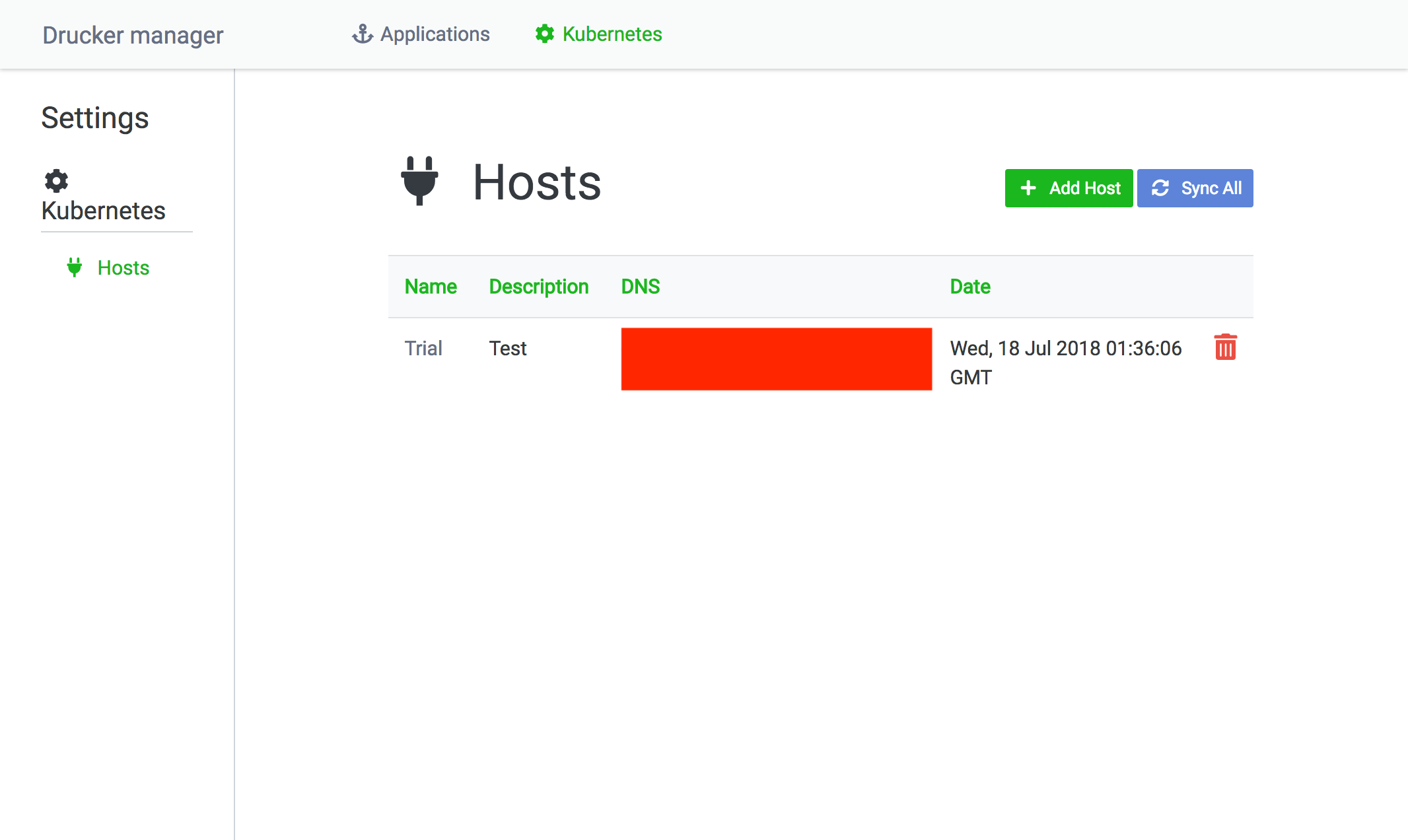
Here is a page where you can register a Kubernetes host.
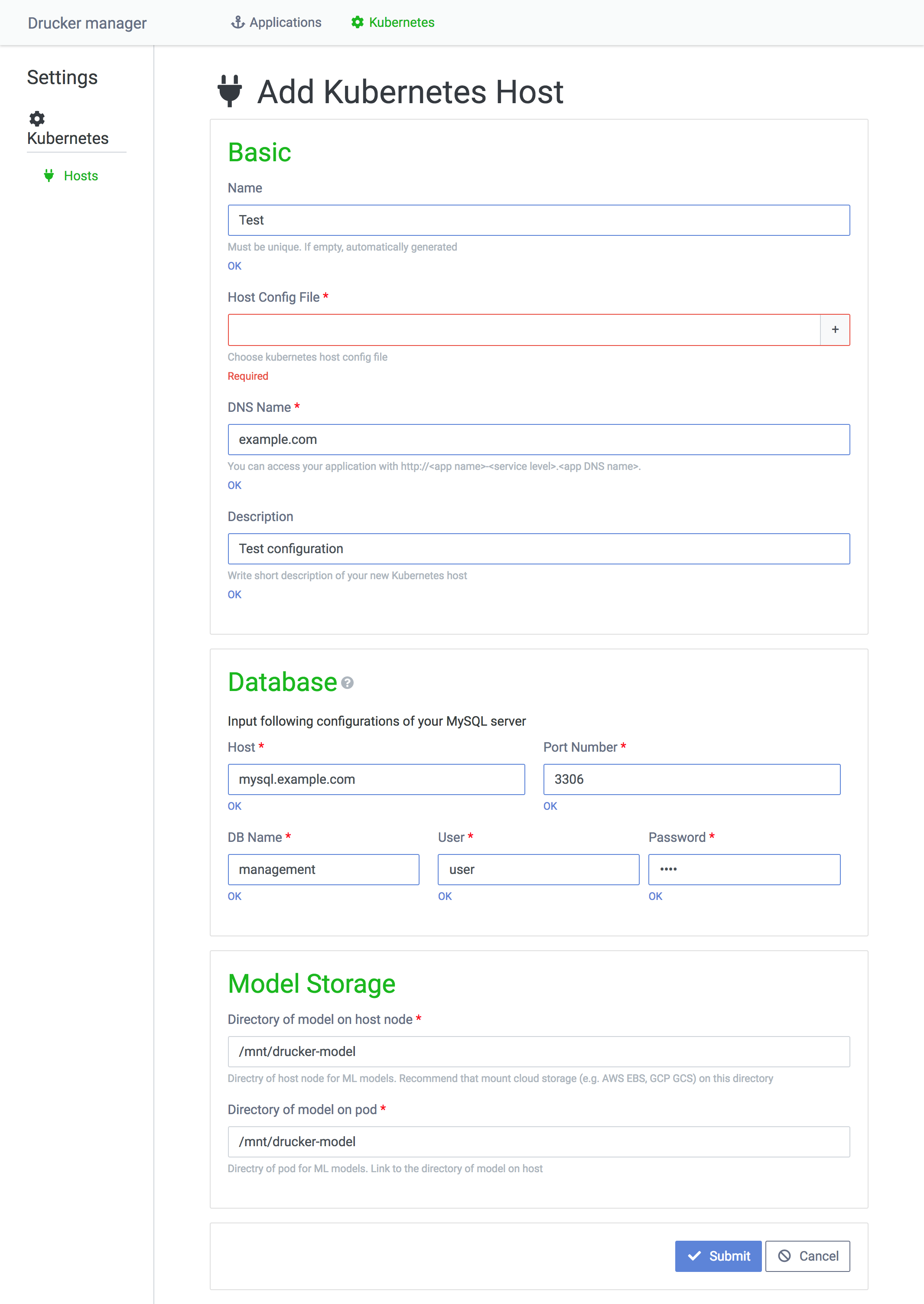
I'll go through a few of the fields.
- Host Config File: The file that contains a token required to access a Kubernetes cluster. To find more about obtaining the token, see the document here.
- Database section: A section to assign the database referenced by a Rekcurd Pod to load machine learning model.
- Model Storage section: A section to assign the directory where machine learning models are stored, which also happens to be where Rekcurd Pods mount a Kubernetes node directory. For all pods to share the machine learning model, the directory of theKubernetes node shall have an online storage mounted on it.
Running a new machine learning module
To run a new machine learning module on Kubernetes, you need to add the module as an application on the dashboard. To add an application, go to the Applications page — using the Applications menu on the top navigation bar — and click the Add Application on the page.
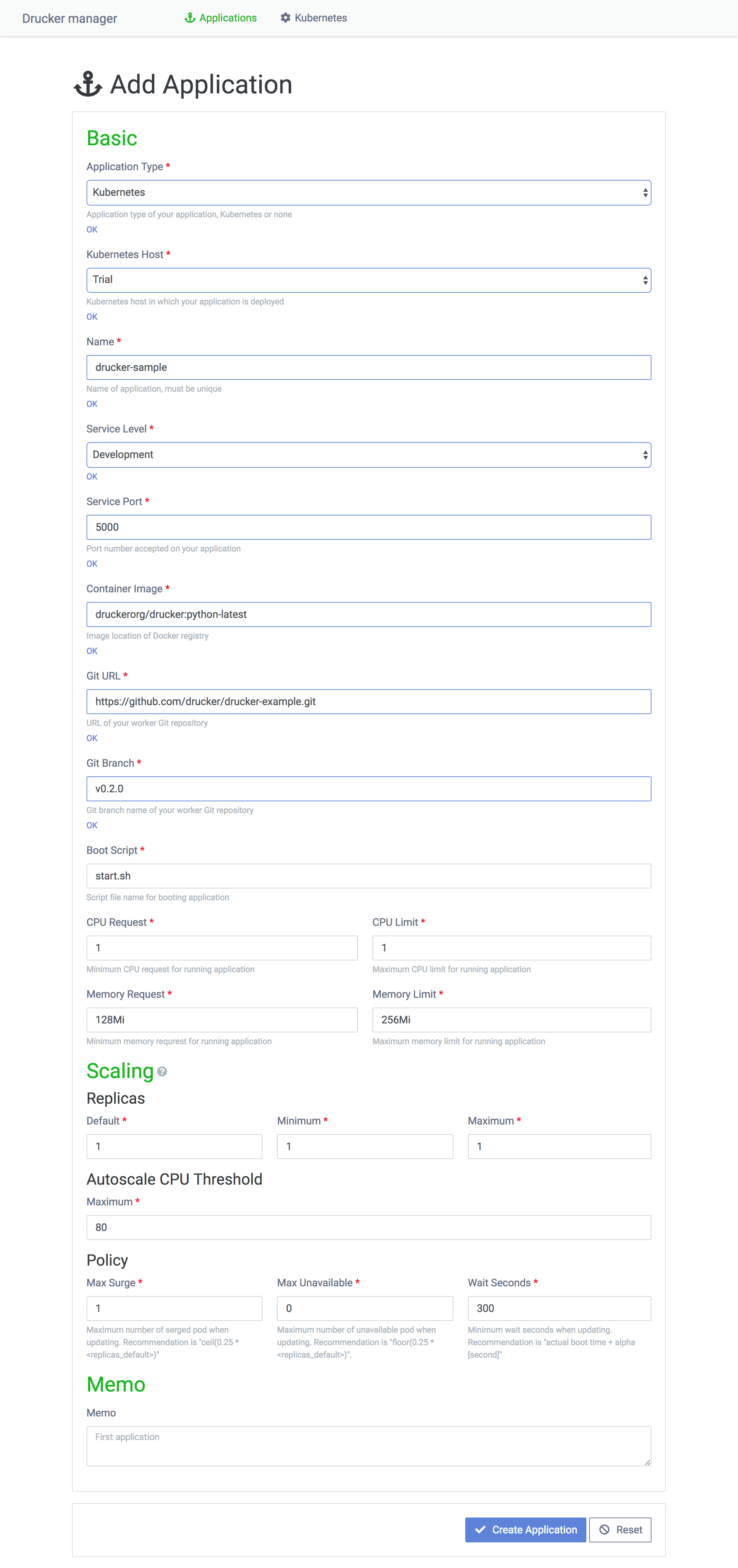
The fields on the application form are as follows:
- Application Type: Select Kubernetes.
- Kubernetes Host: Select the Kubernetes cluster to run.
- Name: Enter the name of a Rekcurd application. Rekcurd dashboard treats machine learning modules as applications. Machine learning modules and Rekcurd services with different service levels are managed as applications too.
- Service Level: The phase of development. Select development or production.
- Service Port: The port for a service to be run on Kubernetes Pods.
- Container Image: The container image for a Rekcurd Pod. You can use an official Docker image provided by Rekcurd or a customized extension of it. Register the container image on Docker Hub or Private Docker registry.
- Git URL, Git Branch: Specify the git repository containing the code machine learning module that is made into a service by Rekcurd.
- Boot Script: Specify the shell script in the git defined in the Git URL and Git Branch fields. If you use the official Rekcurd image, running the container pulls code from a repo defined by the Git URL and Git Branch fields, and runs a Rekcurd Pod using the file defined in this field.
- CPU Request, CPU Limit: Specify in floats how many CPUs you request and the maximum limit of CPU per Rekcurd Pod. For example, 1.0 means one CPU.
- Memory Request, Memory Limit: Specify strings containing the required memory and the maximum memory for each RekcurdPod. (Example: 128Mi, 1Gi)
- Scaling> Replicas: Set the number of pods on the basis of usage frequency of the Rekcurd service and the size of the Kubernetes clusters. Default, Minimum, Maximum implies the number of pods executed initially, the minimum number of pods executable and the maximum number of pods executable respectively.
- Scaling> Autoscale CPU Threshold: The trigger for automatic expansion. For example, if the value is 80, auto expansion is triggered when the CPU usage exceeds 80%.
- Scaling> Policy:
- Max Surge: The number of new Rekcurd Pods executed at a rolling update.
- Max Unavailable: The number of running Rekcurd Pods that are to be concurrently deleted at a rolling update.
- Wait Seconds: The time for a pod executed at a rolling update to be stabilized. If this time is too short, the system may not recognize Rekcurd Pod failure and thus continue to delete running pods, which may result in halting a service. Be careful with the value you set.
- Memo: This field is literally a memo for you. You can leave additional information such as the release date and what has been updated.
Once you fill in the information required, press the Create Application button to complete the process.
Adding or changing a machine learning model
There are times when you wish to check what machine learning model a Rekcurd service is using, to add a new machine learning model, or change the model that is being used. To do any of these, you first need to check the list of application services of the service to change. To check the list of Rekcurd services of your application, click the Applications menu at the top of the dashboard. The list is presented in a table where the machine learning model is listed in the first column followed by services. You can see right away which Rekcurd service uses which machine learning models.
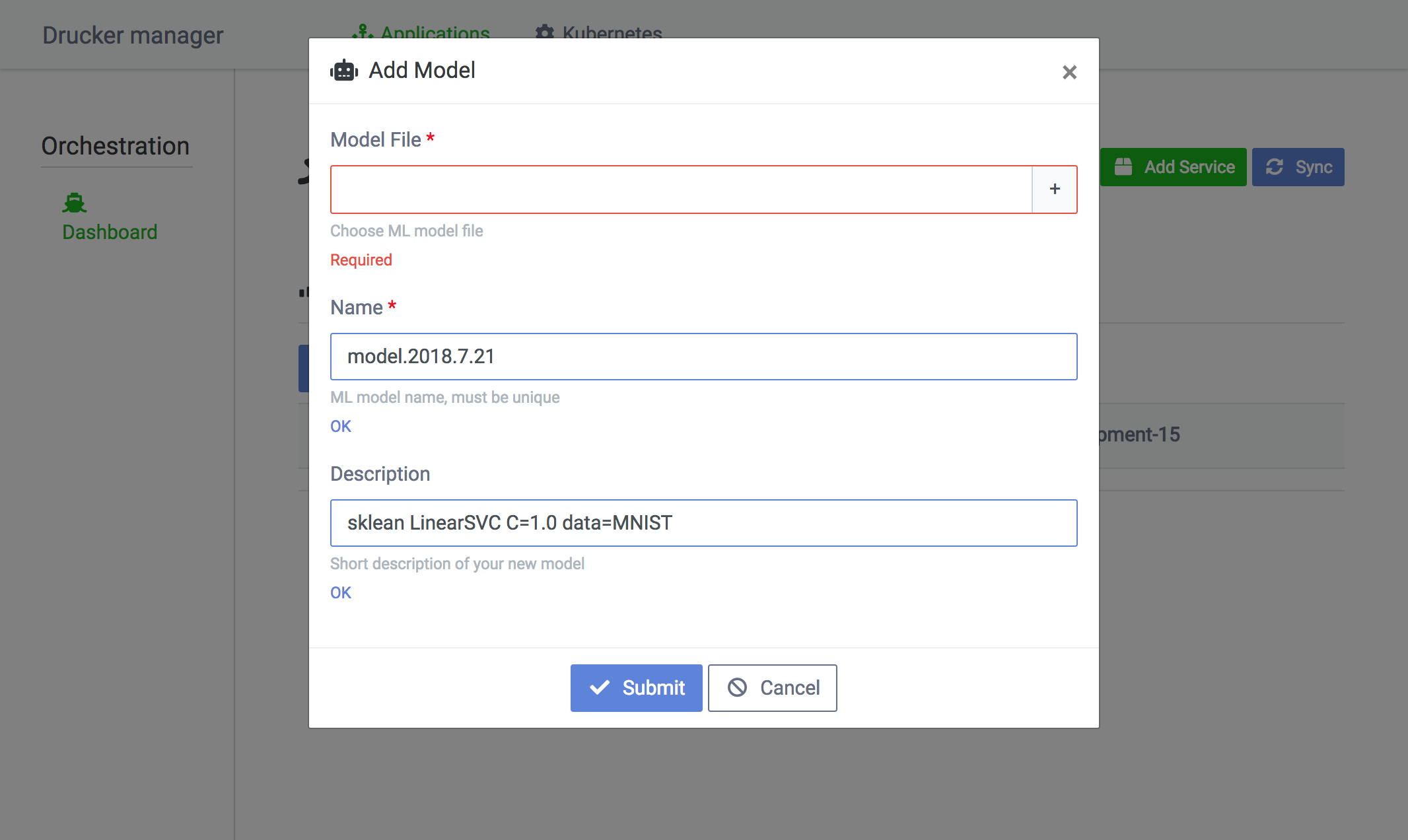
To add a new machine learning model, click the Add Model button from the service list. Leaving information in the Description field on the model's created dates and configurations will become helpful in managing models.
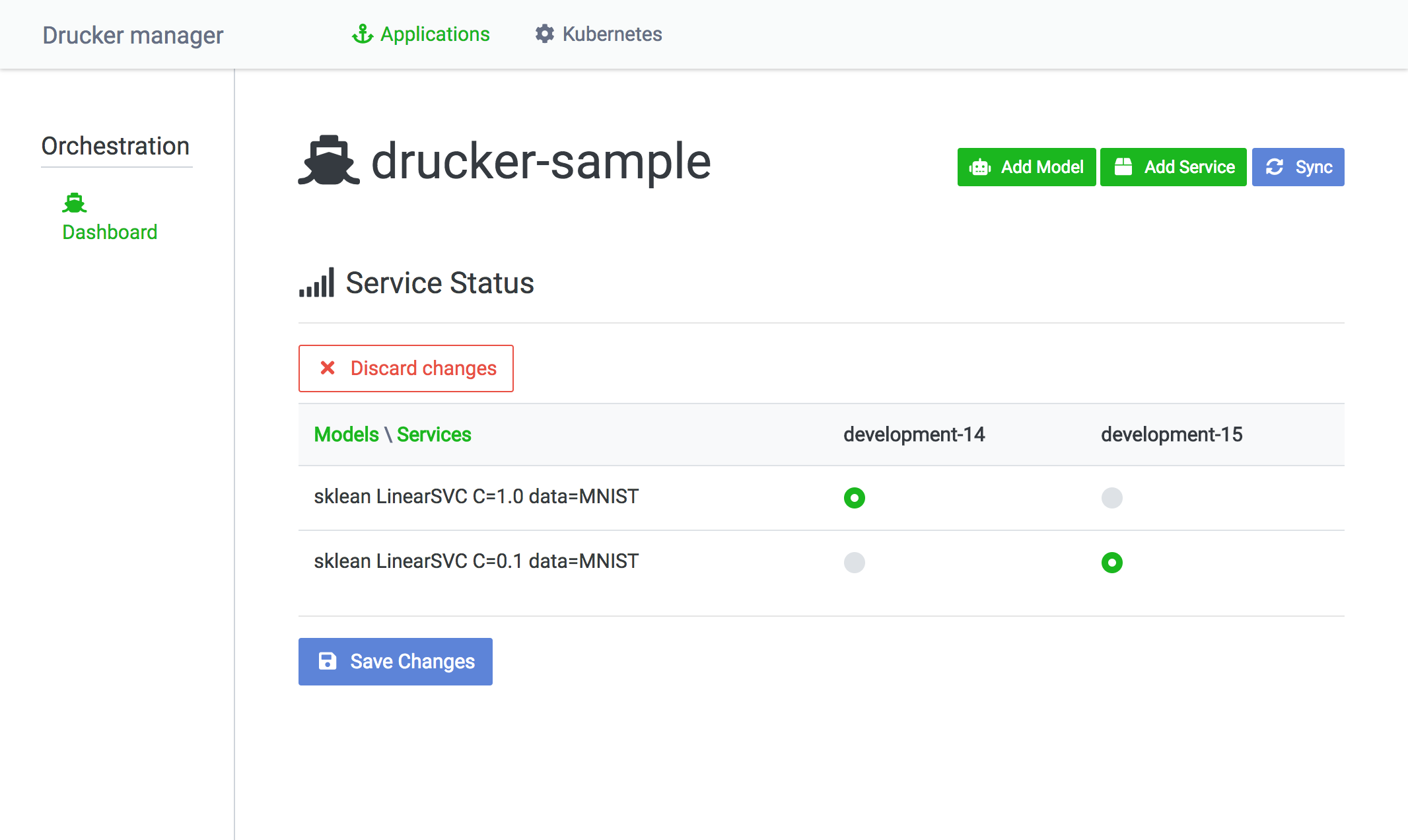
To change the models a service uses, click the Switch models button.
Once you changed required information, press the Save Changes button which will trigger a rolling update on Kubernetes.
Last notes
I've introduced Rekcurd, a platform to serve Clova's machine learning module. With the flexibility Rekcurd provides, you can distribute various types of algorithms and easily manage and operate machine learning models using the dashboard. With Kubernetes running in background, you can automate service monitoring as well as expansion. Being a gRPC service, you can automatically generate SDKS in different languages. In addition, setting an app name on a Rekcurd client enables you to change a machine learning module to use; this means you can access all the machine learning modules distributed by Rekcurd & Kubernetes only with a single client. Rekcurd still is in development, with many areas to be improved, but I'd like to see it grow to a strong OSS with many commits.