
As a technical writer, I get excited every time I start a new project. At the starting point, it gives me freedom as it is wide open with possibilities. Such a freedom motivates me to explore new domains. From that perspective, I find technical documentation consulting exciting as it gives me an opportunity to try new things and learn from them. I'd like to share in this post what I've learned from API documentation consulting I provided a few months ago. More specifically, it is about making an API documentation tool based on source code comments for a new language. I don't mean to create a new tool from scratch but find a good one and apply. Don't expect nor worry you'll need to code a lot.
Nowadays, it has become quite common to produce API documentation from source code comments. Usually document generators like Javadoc or JSDoc are used for widely used programming languages. As a preparation for documentation consulting, I research documentation tools to pair up with a programming language. When someone comes to me for advice on an API reference developed with language A, I usually start API documentation consulting by saying, "Both tool B or C can be used for that language, but I recommend C, considering the project environment." Recently, document generators have become common enough that some clients already have a documentation tool in mind when they come for advice.
In the beginning of this year, I worked on an API documentation consulting case. Interestingly enough, this project was not using one of the widely known programming languages, but scripts dedicated to a specific solution. These scripts did not provide an API document generator, and other tools couldn't be used as the grammar was different. When I almost lost hope for document automation, I found a silver lining when they mentioned that they haven't started documenting yet and syntax rules for comments could be defined. If these rules can be simplified, it would not be that difficult to analyze comments even for an entirely new language. This is how my new project began: "Making an API documentation tool based on the source code of a programming language that doesn't come with an API documentation tool." I'll elaborate on this project in the following order.
- Defining syntax rules for comments
- Customizing a parser
- Documenting information from comments
Defining syntax rules for comments
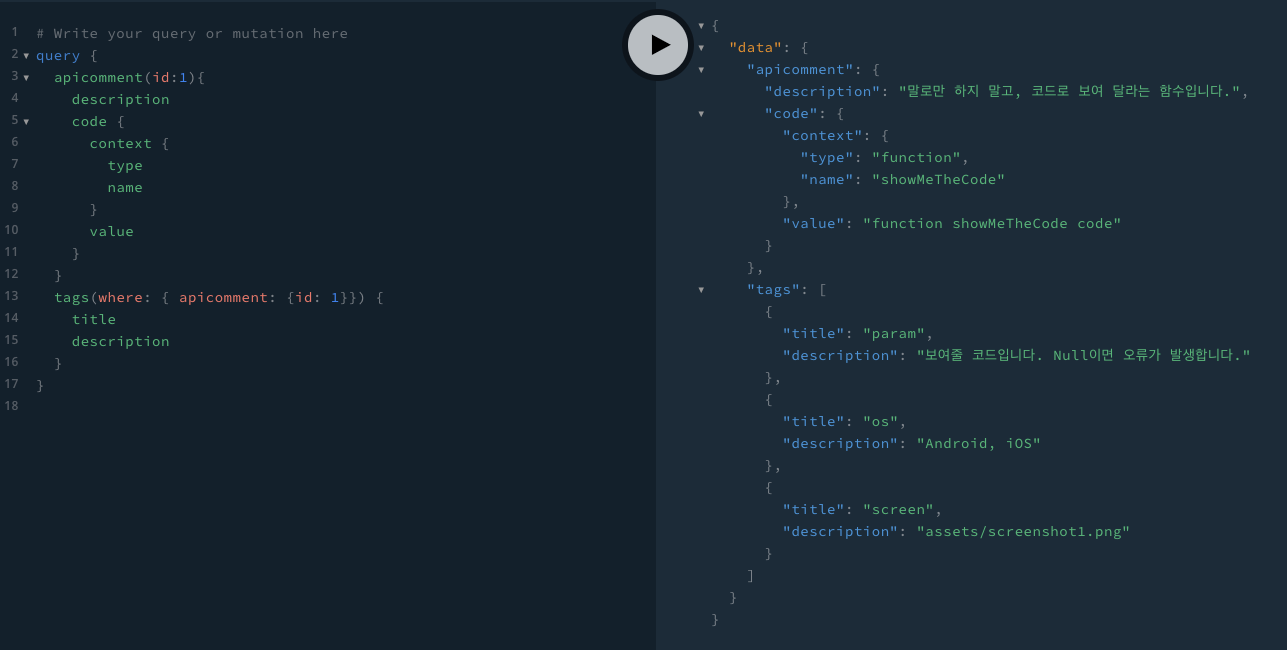
At this stage, we have to decide which API information is to be included in the document and how to state such information in the source code comments. As a first step, I review the API information and requirements of the team requiring documentation, and decide on syntax rules and tags for classification based on widely used API comments. Let's take a look at a simple example of showing basic API description, parameters, supported OS and sample page screenshot. The rule here is to create a comment block on top of the API code and include a basic description in text, parameters with @param tag, supported OS with @os tag, and path of the sample page screenshot file with @screenshot. It looks like this in the source code more or less.
Note. The following source code is for illustration purpose only, and it is not a programming language used for a real project.
(**
Function requesting to give the code instead of just words
Often called after a long description
@param code Code to display. Return an error if null
@os Android,iOS
@screen assets/screenshot1.png
**)
function showMeTheCode code
...
end functionIt would look familiar if you've used a documentation tool like Javadoc. One big difference is how a comment block is indicated. You usually put /* ... */ to create a comment block in other programming languages, but (* ... *) is used in this script language. In addition, a star is added at each end (**...**) to indicate that the comment block is for API information. Consequently, general comment blocks with a single star are disregarded for the tool we'll build here. Based on the basic syntax, I've defined the following rules on how to represent each information.
| Indicator | Definition | Content | Analysis of content |
|---|---|---|---|
| (** | Start of the API comment | Multiple lines of text | Recognizes text without @ as general description and follows respective indicators below for text with @ |
| *), **) | End of the API comment | N/A | N/A |
| @os | List of compatible OSs | {os_name}[, {os_name}] | Lists compatible operating systems separated by a comma (,) (Multiple tags can be used) |
| @param | Description of the parameter | {name} description (javadoc style) | Recognize the first word after a blank space as a parameter name and the following text as a parameter description (Multiple tags can be used.) |
| @screen | Path of the sample screenshot | {file_path} | Path of the image file. Only for one file with a relative path from the root of the source file. |
As @param is commonly used in other tools such as Javadoc, we will follow existing conventions. On the other hand, we are defining rules for @os and @screen for this project. In real life, we would need more tags to produce good API documentation. Here we will leave it simple as-is for illustration purposes. After we define syntax rules and apply them to the source code, we can extract and analyze API comments based on the rules.
Customizing a parser
First step is to find comment blocks with API description in the source code and recognize the rules defined in the table above. As a feasibility test, I used Python to read and process. Seeing as how it was simpler in action than what I'd imagined, I assumed someone would have already implemented it. Bingo! I searched GitHub and found a likely open-source project called parse-comments. parse-comments extracts comment blocks from Javascript-type source code and analyzes Javadoc and JSDoc-like tags to produce JSON objects. It only allowed /** ... */ or /** ... **/ as a comment indicator so this had to be dealt with. Since it has to be modified anyway, we'll let users define the syntax for comments. To this end, two things have to be done.
First, update parse-comments so that we can define our own syntax for comment blocks. We could accomplish this task by changing only a few lines of the code.
Second, implement an extractor that recognizes comments based on the syntax rules of the new script. This extractor will let parse-comments know where API comments exist in the given source code. We could use the basic extractor of parse-comments for comments, starting with /**. But, we need a customized extractor for this project as we need to extract comments, starting with(**.
To-do list for customized extractor
We implemented a customized extractor to recognize comments using different syntaxes. This extractor should generate the following objects after finding comment blocks that start and end with (** and *) in the given source code.
| Name | Value |
|---|---|
| type | Comment block for 'CommentBlock', inline comment for 'CommentLine' |
| value | Text string in the comment excluding (**, **) |
| range[] | Text string in the comment excluding (**, **) |
| loc{} | Object representing the location of the comment in the text string with the number of lines/columns |
| loc.start{} | Start of the comment in the text string including (** |
| loc.start.line | Line number of the start of the comment in the text string |
| loc.start.column | Column number of the start of the comment in the text string |
| loc.end.line{} | End of the comment in the text string including **) |
| loc.end.line | Line number of the end of the context subject to analysis in the text string |
| loc.end.column | Column number of the end of the context subject to analysis in the text string |
We'll get the following location information when this is applied to the API comment example in the beginning of this post. It is presented in an array as there are multiple API comments.
[{
type: 'CommentBlock',
range: [ 0, 138 ],
loc: {
start: { line: 1, column: 1 },
end: { line: 6, column: 3 }
},
value: '
' +
'Function requesting to give the code instead of just words.
' +
'Often called after a long description.
' +
'@param code Code to display. Return an error if null.
' +
'@os Android,iOS
' +
'@screen assets/screenshot1.png',
}]It is a little bit cumbersome to generate range or loc information, but it is not that difficult to find comments with regular expressions.
Applying customized extractor
It is time to integrate this customized extractor into parse-comments to analyze API comments. First, install the modified version of parse-comments that allows users to designate comment indicators.
> npm install https://github.com/lyingdragon/parse-commentsI wrote the following code to get the source code and return API comment information with parse-comments.
apidoc-generator.js
const Comments = require('parse-comments');
const fs = require("fs");
// Comment indicators
const commentPrefix = '(**';
const commentSuffix = '*)';
// Customized extractor, returning an array of the object with API comment information. Use commentPrefix and commentSuffix for this example.
const myExtractor = function (str, options) {
var comments = [];
... ... (Conducting tasks explained under [To-do list for customized extractor])
return comments;
}
// Create a Parse-comments object. Enter the customized extractor and comment indicators
var comments = new Comments({
extractor: myExtractor, // Designate the customized extractor
commentStart: commentPrefix, // String indicating the start of the comment block
commentEnd: commentSuffix} // String indicating the end of the comment block
);
// Print analysis results. test.source from [Defining syntax rules for comments].
console.log(comments.parse(fs.readFileSync('test.source').toString('utf-8')));When this is executed, we get the analysis result of comments in 'test.source' as follows.
{
"apis": [
{
"type": "Block",
"loc": {
"start": { "line": 1, "column": 1 },
"end": { "line": 6, "column": 2 }
},
"range": [ 0, 138 ],
"raw": "Function requesting to give the code instead of just words.Often called after a long description.@param code Code to display. Return an error if null.@os Android,iOS@screen assets/screenshot1.png",
"code": {
"context": {},
"value": "function showMeTheCode code",
"range": [ 139, 166 ],
"loc": {
"start": { "line": 7, "column": 0 },
"end": { "line": 7, "column": 27 }
}
},
"description": "Function requesting to give the code instead of just words.Often called after a long description.",
"footer": "",
"examples": [],
"tags": [
{
"title": "param",
"name": "code",
"description": "Code to display. Return an error if null.",
"type": null,
"inlineTags": []
},
{
"title": "os",
"name": "",
"description": "Android,iOS",
"inlineTags": []
},
{
"title": "screen",
"name": "",
"description": "assets/screenshot1.png",
"inlineTags": []
}
],
"inlineTags": []
}
]
}As you can see, I added just a few lines of code for the customized extractor and we can easily analyze API descriptions and tags in the comments. Unfortunately, we got nothing for code.context in line 12. This line is to give the context of the function code in comments, but it failed to analyze the context. We know which function it is as code.value returned "function showMeTheCode code". There is just a little bit of more work to be done. Let's take this just a step further despite a bit of inconvenience. It will be helpful in handling data during documentation if we can segregate and put "function" in code.value and "showMeTheCode(function name)" and "code(parameter name)" in code.context.
Note. If it were using the Javascript grammar, parse-comments would have automatically filled in
code.context. It returned nothing because the current script grammar is different from that of Javascript.
Let's make a function that separates code.value with a space and fill in code.context. I'll skip the code as it is simple string parsing. When this function is set as a preprocess option for generating parse-comments, this function is executed before analyzing comments.
api-generator.js
...
// Generate a Parse-comments object. Enter the customized extractor and comment indicators as an option.
var comments = new Comments({
extractor: myExtractor,
preprocess: myFunctionParser, // Add code.value parser. Implement it to segregate function/name/parameter.
commentStart: commentPrefix,
commentEnd: commentSuffix}
);
...When it is run again, you can see that function context is included in code.context.
...
"code": {
"context": {
"type": "function",
"name": "showMeTheCode",
"args": "code"
},
"value": "function showMeTheCode code",
"range": [
139,
166
],
...Voila! We were able to extract and analyze comments of a new programming language in a relatively short time frame thanks to an already existing open source project. Next step is to generate documentation using information from these comments.
Documenting information from comments
Note. I actually used my favorite tool, Pandoc, for this project. However, I'll use Handlebars for this posting as more people are familiar with Handlebars than Pandoc.
We'll create a document layout, using a Handlebars template. HTML can be used, too, but the recent trend in the technical writing world is markdown. Let's ride the trend and create a sample template. While real life projects would be more complicated, we will simply return API name, its description, screenshot and parameters for this sample.
# API reference
## Summary
| API | Description |
|---|---|{{#each apis}}
|[`{{this.code.context.name}}`](#{{id this.code.context.name}}) | {{brief this.description}} | {{/each}}
{{#each apis}}
## {{this.code.context.name}} {{#if (getTagValue this.tags "title" "deprecated")}} <sup>Deprecated</sup>
> **Deprecated**
>
> {{lookup (getTagValue this.tags "title" "deprecated")}}
{{/if}}
> **Summary**
>
> **Script file:** test.script | **Supported:** {{#each (getTagValue this.tags "title" "os")}}{{this.description}}{{/each}}
## Overview
{{this.description}}
{{#each (getTagValue this.tags "title" "screen")}}

{{/each}}
## Parameters
| Name | Description | Type | Default |
|---|---|---|---|
{{#each (getTagValue this.tags "title" "param")}}
| `{{this.name}}` | {{this.description}}| {{this.type}} | |
{{/each}}
{{/each}}We'll send the JSON object created by parse-comments to the Handlebars template and create a markdown file.
...
const handlebars = require("handlebars");
const template = handlebars.compile(fs.readFileSync('apidoc.md.hbs', "utf8"));
fs.writeFileSync('out.md', template({apis: ast}));I provided the basic code here for illustration purpose but it would require a few customized helpers such as brief, id, or getTagValue to use this template. On the assumption that we have all the required helpers, we will get an online document when the generated markdown is rendered in GitHub. Find the following result with showMeTheCode as well as another API called mycode.

The result looks just like any other API reference documentation. Unlike tools such as Javadoc, technical writers full of artistic instinct can add an emphasis on branding with just the right 'look and feel'. Of course, it will require more additional effort on the front end and design.
Going forward
After completing the project, I started to imagine where else I could apply this work. This time, it was for API documentation. The essence of this approach is 'extracting comment information from the source code regardless of a programming language.' It doesn't always have to API information. For example, if information on bug fixes per version were included in comments, bug fix reports could be generated from comments. By doing so, the source code can be used for both functionality and documentation, keeping them up to date consistently and allowing automation with Jenkins possible. What I've described herein is effective as it will take shorter to create a customized extractor and template, compared to modifying input and output of already existing API documentation tools. Am I telling you the truth? Why not just go for creating a bug fix report. I wrote the following comments as soon as I got this idea.
/**
@version 1.0.0
@bugfix Resolved the issue of overlapping buttons in mobile version
@issue MYISSUE-1000
**/
class DisplaySystem
/**
@version 1.0.1
@bugfix Fixed the sound error in iOS xxx version
@issue MYISSUE-1242
*/
public class SoundSystem
/**
@version 1.0.1
@bugfix Fixed the Fetch module calculation error
@issue MYISSUE-1243
*/
public class CoreSystemThen, we design a template. Template code can be written just like that. It could take a bit of time to implement a helper to collect comments per version.
# Bug fixes
{{#each (uniqueVersion apis)}}
## {{ @key }}
{{log this}}
{{#each this}}
`{{this.code.value}}`
- {{#each (getTagValue this.tags "title" "bugfix")}}{{{this.description}}}{{/each}}
- Related issue: {{#each (getTagValue this.tags "title" "issue")}}{{{this.description}}}{{/each}}
{{/each}}{{/each}}We now have the following bug fix report in no time. It can be a effective and efficient option for developers who want to keep everything in the source code.
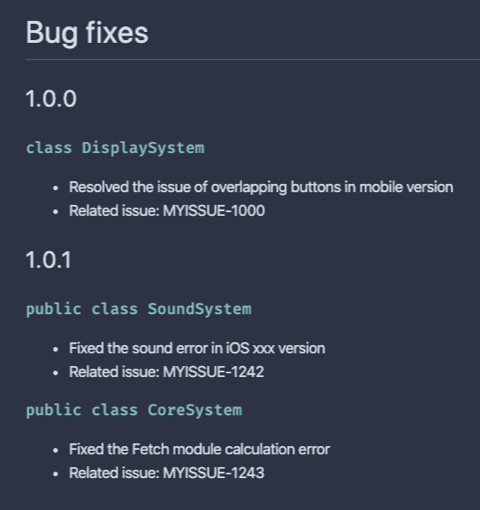
From a technical writer's perspective, what kind of applications can there be? In a previous blog post, one recommendation was to 'define API specifications and convert to markup when there is no source code and convert API information in the comments to markup with Doxygen when there is source code.' This was to group the same type of content together for the final document and easily respond to changes in view. I didn't get a chance to go into detail about converting comments in the source code to markup, but it is quite complicated. After finishing the current project, I realized that there was a way to skip all complications to directly integrate source code comments into API specifications. In other words, what parse-comments returns can be used as basic structure for API specifications. My upcoming plan as a technical writer and document engineer is to save API comment information into headless CMS (content management systems) such as strapi and generate API specifications that can be commonly used, consequently increasing the autonomy of the front end.
I hope to come across more interesting projects and come back here to share my experience. Bye for now!