
Hello, we are WJ and KH and we are in charge of game security development at LINE.
A massive number of players play LINE Games at any given time, and that is why quick issue analysis and response can be difficult. With the large increase in LINE Game players and users from abroad, many instances of abuse (profiting through unauthorized actions) are being observed. Abusing the system affects other players that are playing the game by the rules, while also directly affecting the game itself. Responding to these abuses as quickly as possible is crucial to keeping the game stable, and to protect players that are playing the game as intended.
In order to respond quickly to these abuses, we must collect and analyze different logs to find the issue and deal with them. To do this, we must be able to process these large logs as fast as possible. With the increase of the data that requires processing, the traditional methods of analysis prove to be inadequate. We needed something that would not take up to hundreds of minutes of response time when it came to analyzing big data. We also needed a way to account for the difficulty of connecting data, something that would not be affected by different data types (RDB, NoSQL, File, API) or data sharding technology needed for large services; especially since popular games tend to have large amounts of data influx. We attempted to come up with a solution by combining various open source software. As a result, Apache Mesos and Apache Spark was chosen for task distribution and resource utilization, Apache Zeppelin was chosen for visualization. These software were the closest to match our requirements. We attempted to construct our own solution using them.
Spark, Mesos, Zeppelin, and HDFS were used in the process. We were able to establish a stable analysis environment that can process 15TB of various connected data in 10 minutes, while also isolating abusers based on game, access, and billing data. In the end, we were able to build a system that is capable of finding and verifying offenders quickly and accurately. We named the system: Airborne.
Objectives of Airborne
The following were put into consideration while we were constructing Airborne.
- Distributed parallel data processing
- Managing system resources for task distribution and
- optimization in distributed environments
- Flexible server expansion
- Effective visualization
- Processing streaming data
- Dealing with system failures
Airborne architecture
The architecture of Airborne is as below. 
Systems of Airborne
The systems of Airborne are as below. 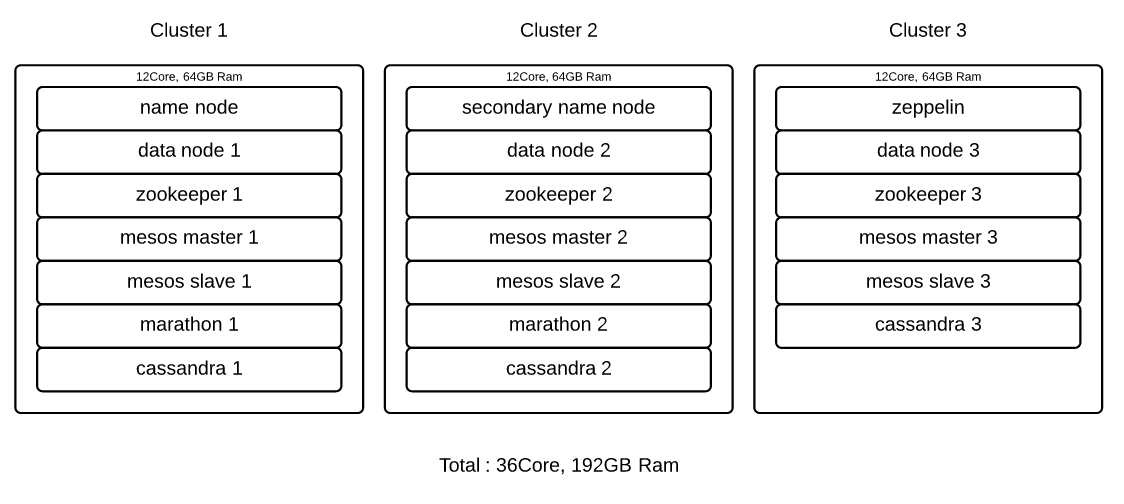
We use Python, Perl, and C to collect data in the form of RDB, SNS, and LOG. In the case of MySQL, we use the mysql binlog utility to collect time series data in real-time. Instead of acquiring data through queries, remotely collecting cloned logs and parsing them is also an option.
In the current configuration, Spark is used in standalone mode while Mesos manages resources. We decided to keep HDFS and Spark executor as close as possible to maintain locality. SSDs were used to secure high I/O speeds. On initial launch, Mesos will unzip the Spark executor package stored on HDFS to the location being manage, setting up the environment automatically. Also, Zeppelin is used to define and configure the required data. Spark SQL is used to quickly visualize the data.
Cassandra on Mesos is used for distributed data storage, storing summarized information acquired from processing large amounts of data. The Cassandra node was configured in a way that can be easily expanded through Marathon. Marathon maintains fault tolerance. If needed, node factors can be added to expand clusters automatically.
Analyzing security data
Airborne was constructed through countless trial and error, but it was worth it as we are using it to conduct various security operations. Now we can query large amounts of data in a short amount of time, while also efficiently isolating issues by visualizing that data. This is of course, a much easier and flexible way of looking at different types of data compared to the old method of putting them side-by-side. For some data, even near-real-time visualization is possible.
The following are a few cases of abuses that were detected and analyzed.
Case 1 - Detecting coin abuse cases through billing data analysis
 We regularly analyze billing data and detect abuse cases by using filters. After responding to some of these abuse cases according to our policies, we saw a decrease in the number of abuse cases discovered.
We regularly analyze billing data and detect abuse cases by using filters. After responding to some of these abuse cases according to our policies, we saw a decrease in the number of abuse cases discovered.
The decrease can be seen at the position marked with an arrow above. Abusing methods include using hacking tools to alter memory or code so that the logic acts in an abnormal way. This was a case where we detected such methods and responded accordingly.
Case 2 - Detecting abuse cases through LINE Rangers game data analysis
 We detected various hacking attempts through Airborne, and were able to implement the required security measures by analyzing the game data. The detected abuse was set to be monitored and automatically analyzed hourly and daily for further observation.
We detected various hacking attempts through Airborne, and were able to implement the required security measures by analyzing the game data. The detected abuse was set to be monitored and automatically analyzed hourly and daily for further observation.
One method of abuse that spread through social media was detected and dealt with, the results can be seen in the position marked with the arrow above. Leveling up characters or tampering with leaderboards without actually launching or playing the game are also considered as an abuse, and was dealt accordingly in this case.
Case 3 - Detecting abuse cases in LINE Bubble
 Since we can now process data more easily and quickly than before, analysis environments can be set up for newly released services to be monitored regularly.
Since we can now process data more easily and quickly than before, analysis environments can be set up for newly released services to be monitored regularly.
Newer services are free from abuse at first. But as abuses can be detrimental to the potential growth of these services, we make sure to monitor similar patterns of abuse found in other services as a precaution.
The data circled in yellow and red are normal, being approached and monitored from several different angles.
Conclusion
With Airborne, people in development and management can now directly detect and respond to issues that were previously untouchable due to the large size. As it is only in its initial phase, there will be inevitable problems down the line. But it is meaningful in that we can now detect issues from data that was previously impossible to process quickly, and respond to those issues quickly as well.
The field of big data processing is quickly advancing, but establishing an environment tailored to your needs and obtaining results is still difficult. With the system that we have set up, we are working hard to provide a safe gaming environment by keeping the games stable and detecting abusive users. Ultimately, we think Airborne can be used in instances where quick data processing is required as well.