
大家好,我們是 LINE 台灣資料開發團隊的 Penny、Johnson 與 Nina。很高興能參加這次由台灣大學電信所及資工所,於 2 月 7 號舉辦的專題演講 "Speech Technologies at Google: an Overview"。本演講很難得地邀請到帶領 Google speech 團隊的 Pedro J. Moreno 博士,親自分享 Google 語音辨識服務的技術演進和應用。演講內容深入淺出,從傳統語音辨識的方法,到比較深的 end-to-end 模型,並用 end-to-end 模型帶出幾個主要的應用。接下來我們會針對什麼是語音辨識、如何做語音辨識、語音辨識的應用,以及 LINE 台灣對於中文語音辨識的努力進行分享。
怎麼做語音辨識?
首先,什麼是語音辨識呢?
語音辨識,或稱自動語音辨識 (Automatic Speech Recognition, ASR) 的目標很簡單,就是透過電腦自動把語音內容轉成對應的文字,與大家說的語音轉文字 (Speech To Text, STT) 是同一件事。聽起來好像很枯燥,但其實可延伸出無窮的應用。Pedro J. Moreno 博士在演講中就提到,語音辨識迷人的地方在於,你可任意組合輸入及輸出的元素,形成各種應用。例如語音翻譯,把外國人說的英文語音,翻譯並合成產生中文語音輸出;又例如語音助理,把輸入的語音,透過自然語言理解 (NLU) 轉成在哪個領域 (domain)、有什麼意圖 (intent),以及要完成的任務中須收集哪些關鍵詞,進而完成動作。
Google 的語音辨識最早出現在 2006 年的 Goog-411 產品中,讓用戶可透過語音輸入公司名稱,搜尋到公司電話及地址。雖然此服務在 2010 年終止,卻也因此收集到不少用戶的語音資料,作為之後學習的基礎。2009 年後則陸續出現在 Google Voice、YouTube、Voice Search 等服務中,一直到現在大家熟知的 Google Home 及 Assistant 應用。短短十幾年間,透過類神經網路、深度學習與 sequence-to-sequence 模型的演進、資料與計算上的持續擴充,讓目前 Google 語音搜尋 (voice search) 的字錯誤率 (word error rate, WER) 從原本 20% 降到 6%,是非常大的進步。
所以,該怎麼做語音辨識呢?
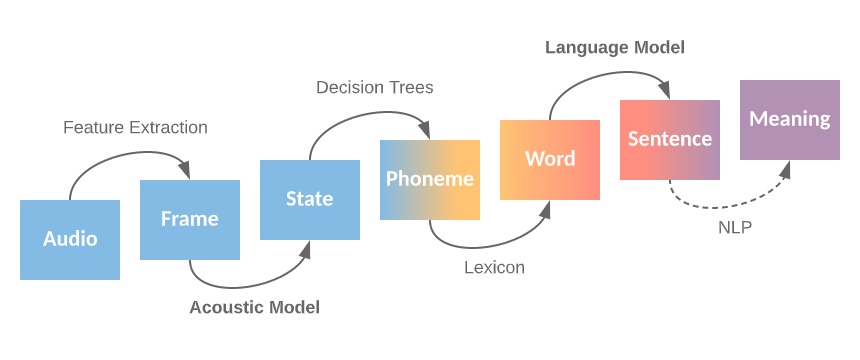
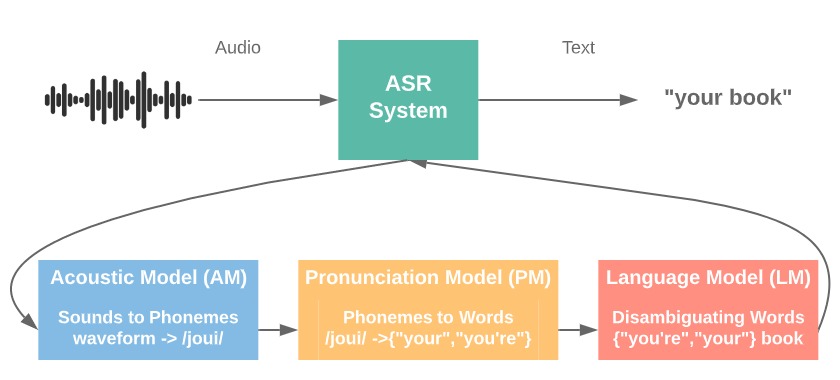
我們可把語音辨識分成幾個小模組 (如下圖一) 以了解細部運作,當一段語音進來後,先等比例切成一幀幀 (frame),透過聲學模型 (Acoustic Model, AM) 轉譯成一個個狀態 (state),接著透過決策樹模型,把狀態分成能區別意義的最小單位:音素,音素經過字典可找出對應的字,最後,再透過語言模型 (Language Model, LM) 把一串字整合成句子,若再加上自然語言處理 (NLP),則可轉成有意義的文字。如把語音辨識 (ASR) 看成一個系統 (如圖二),則可分為三大模組 (sub-modules),包含聲學模型 (AM)、發音模型 (Pronunciation Model, PM),以及語言模型 (LM),這也是語音辨識較為傳統的作法。
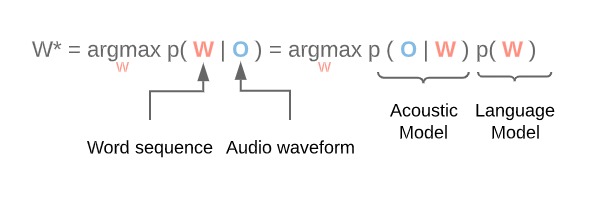
傳統 ASR 模型要解決的問題,其實可看成一個簡單的機率問題 (如圖三),W 是要輸出的文字序列 (Word sequence),O 是輸入的音頻 (Audio waveform),所以這問題的目標就是在已知的音頻輸入下,找到最可能產生的文字序列。透過貝氏定理 (Bayes' Rule) 可拆解成兩個機率分佈:(1) 給定一個文字序列會出現這個音頻的機率,以及 (2) 出現這個文字序列的機率。其中 (1) 就是 ASR 中的聲學模型 (AM),而 (2) 就是語言模型 (LM)。此處聲學模型 (AM) 可拆得更細,表示成音頻屬於某個音素的機率,以及音素對應到文字序列的字典 (PM)。而音素又可透過狀態來進行轉換,如果透過狀態的表示,並假設每個狀態只與前一個狀態有關的話,AM 就可用隱藏式馬可夫模型 (Hidden Markov Model, HMM) 來實現。
從傳統方法轉變到 end-to-end
實務上,以 sub-module 的形式包裝整個語音辨識的流程 (AM → PM → LM) 是十分有效的,這樣的傳統方法沿用於 Google 語音辨識產品。如上面介紹的 AM (Acoustic Model) 將聲學訊號拆解成音素,也就是組成 subword 的最小單位;PM (Pronunciation Model) 將這些片段的音素對應成文字上的形素,也就是可表達文字的最小單位;接著 LM (Language Model) 將這些文字的最小單位按照語言使用的邏輯、機率組成合理的文字,也就是我們看得懂的句子。但這些模型都是分開訓練、使用不同訓練資料、應用不同的調參優化策略,這樣對整體應用的優化將造成阻礙,像是損失 (loss) 的傳遞不能直接透過 LM 的最終答案傳達到 AM 的模型參數優化上,這對機器學習相當不利。所以一個 end-to-end 的模型會是合理又更有效的解決方法。以下會介紹 Google 在應用及研究上大量使用的 end-to-end 模型。
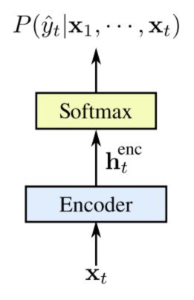
早在 2006 年,為解決語音與文字需要對齊 (alignment) 的問題,常耗費大量人力進行標註。後來,在結合 RNN 模型擁有記憶力的特性下,提出 CTC 模型 (Connectionist Temporal Classification),自動對齊文字訓練材料與語音輸入的每一幀音訊。也就是說,以往需要知道哪幾幀輸入音訊對應輸出的哪個字符、了解如何分割不同輸出字符對應輸入幀的邊界、耗費人力區分音與音之間的邊界,以及填入對應的字符等;而在 CTC 當中,則是利用 blank symbol 空白字符"<b>" 加入輸出字符串中,將對應的輸出字符與空白字符排列好、可對齊每幀音訊,像是對應一段 12 幀音訊 banana,對應聲音不同的停頓點,它可以是 12 幀的 b a a "<b>" n a a "<b>" n a a "<b>",也可以是 12 幀的 b b a "<b>" "<b>" n a "<b>" n a a "<b>",這些分割方式,都可很直觀地將標注字合併成輸出字符 banana。具體的模型如下圖,CTC 模型利用 RNN 模型,將序列的文字輸出編碼成各幀的向量,並透過 softmax layer 產生可能對應的文字輸出 (也就是最可能的分割排列) 機率分佈,數學上可用 gradient ascent 最大化該機率模型。
對於近期語音識別產品最常使用的模型,2017 年 Google speech team 以 RNN-T (Alex Graves, 2012) 架構的應用就是個很好的開始。相比於傳統的 CTC 模型,RNN-T 除了擁有跟 CTC 一樣不需要對齊音頻與文字的特性,還可達到 end-to-end 的效果:聯合優化端到端 (end-to-end) 訓練的參數,並擁有 LM 語言模型最佳化文字產出的效果。RNN-T 示意如下圖:
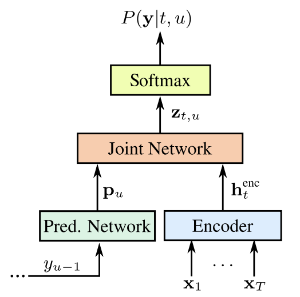
關於 RNN-T 模型,簡單來說可想像成聲學模型 AM Encoder 和語言模型 LM Prediction Network 的結合。具體可理解成 Encoder 這端利用雙向 (bidirectional) 的 RNN-base 模型,將聲音訊號編碼成向量,接著 Prediction Network 這端會將先前識別出的文字當作輸入,以單向的 RNN-base 模型預測下一個可識別的文字之機率分佈,透過一個 Joint Network 將兩邊的資訊統合,最後產出考量了聲學訊號和識別的語言文字序列等,輸入後可識別的文字之機率分佈。實務上,相較於傳統的 HMM 與 CTC 模型,RNN-T 有著模型更小、訓練更快的優勢,且有較好的準確度,使得這類模型可被放在手機等應用端上使用。
隨著深度學習的進展,Google speech team 也將近年來發展成熟的 Attention 記憶力模型加入語音識別的模型中,發展出全新模型,也就是 LAS 模型 (Chan et al. 2015),LAS 的結構如下:
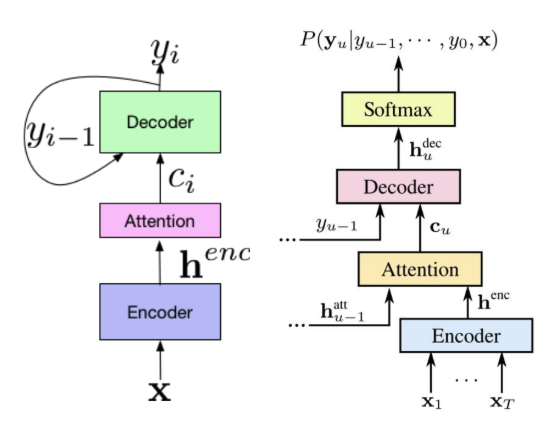
它也可被理解成 AM 與 LM 的結合,AM 可説是圖中的 Encoder,用一個多層的 RNN 模型將聲音訊號編碼成模型的隱狀態向量,可讓模型學到對輸入訊號更多層次的理解,例如可理解 spelling variants 的識別 (像是 "triple w" 與 "www" 的同等性)。完成 encode 後,則通過一層注意力模型,將隱狀態向量,也就是聲音訊號本身學出對每個不同時間輸入的權重,讓模型更有效地捕捉輸出與輸入局部資訊之間的關聯,並產生將當前輸入經過 attention 權重後的 context vector,最後透過如 LM 的 Decoder 模型,將接收的 context vector 轉化成預測識別字的機率分佈。而近年來,Google 針對 LAS 模型的各種改良,可超越傳統模型的 WER (6.7%),達到 WER 僅有 5.6% 的準確度 (Chui et al. 2017)。
語音辨識可解決什麼問題?
常見的語音辨識應用,概念上是訓練一個 AI 模型去偵測聲音,並做出下一步的行動,例如:傳送一個文字訊息,或語意理解後轉成語音命令來控制智慧裝置,讓生活更加便利。但還有一群人因為漸凍人症、中風或失聰等疾病,使得他們的咬字與發音不同於他人,導致他們所說的話不容易被理解,此時,語音辨識模型能帶來很大的幫助,Google 的 Project Euphonia 及 Parrotron 就是在解決這個問題,幫助語言障礙者們被他人理解、接軌世界。
Project Euphonia 可幫助肌萎縮性脊髓側索硬化症 (Amyotrophic lateral sclerosis, ALS) 患者,俗稱漸凍人症,25% 的 ALS 患者第一個症狀是口齒不清,Google 透過 ASR 協助轉譯他們所說的話。Google 以長達數千個小時的標準語音資料所訓練的高精度 ASR 模型為基礎,加入來自語言障礙者的非標準語音特徵小數據集進行 fine-tune,使得原本的 ASR 模型在理解非標準語音上大幅改善。Table 1 顯示出一般標準語音 (Base) 模型和非標準語音 (Finetune) 模型,在識別 ALS 患者及非英文母語人士 (Arctic) 語音的單字錯誤率 (WER),其中 RNN-T 模型僅對兩層網路進行微調 (fine-tune) 就可將單字錯誤率 (WER) 從 59.7% 下降至 20.9%。
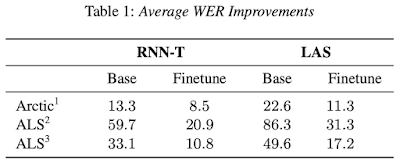
2 FRS 等級 2 之 ALS 患者語音資料集
3 FRS 等級 3 之 ALS 患者語音資料集
註:FRS score 為用以評估語言障礙程度的標準,
等級分為 0 (不可理解) 至 4 (正常)
Project Euphonia 可為語言障礙者建立個性化的模型,先將語音透過 ASR 模型轉成文字,最後合成語音;而 Parrotron 則是直接用 speech-to-speech 語音訓練,不須經過文字轉換,使用者只須輸入非標準語音,模型不須先轉成文字,就可直接轉化成清晰的聲音,所以即便中間出現錯誤,輸出的聲音也比經由文字轉換後合成的,更加接近原本的輸入語音、更貼近說者的意圖。我們可藉由此 demo 影片,看到以普通標準人聲訓練的通用模型和 Parrotron 之間的巨大差異,也更能體會運用 AI 科技、讓語言障礙者重新與世界連結的美好成果。
結語
在理解 Google 對語音辨識所做的努力與進展後,我們也希望能把對技術難題的解法帶回 LINE。LINE 提供的語音服務,也就是廣為人知的 Clova 智慧語音助理,正如先前提到的,這項應用在實務上需要先將語音透過 STT 轉成文字,並透過 NLU 轉成意圖與任務動作,再將回應透過 TTS (Text To Speech) 轉成語音輸出,由於每個階段的模型都會產生誤差,演講中有提到可將 STT 與 NLU 兩個階段要訓練的模型合併成一個 end-to-end 模型,直接將語音轉成意圖,不須先轉成中介文字 (Haghani et al. 2018),這可能是我們未來可以優化的方向之一。而 LINE 台灣目前正積極開發 Clova 中文化的應用,努力達成完整的語料、語料標記等目標。我們的資料開發團隊也試著將不同的 end-to-end 模型,例如 Deep Speech 等,應用於中文語料庫,亦計劃將本次語音辨識講座學到的新知,應用在實務開發中!