
IEEE ICASSP 2021 at Toronto

前言
儘管至今 COVID-19 疫情持續了將近兩年,學術研究與技術研發的腳步也是不會停歇的。語音研究相關的頂級學術會議 (top 1 tier) 之一 ICASSP 繼去年開始線上舉辦,今年也在多倫多同時舉辦線上的學術研討會。不過今年的線上會議不同於去年是免費開放各方來參與,會開始恢復以往學術會議需要註冊繳費的形式來參加;但以去年參加的經驗來說,整體的體驗更加順暢,顧慮到講者與聽眾在異地及不同時區的時空差異,互動形式也更彈性、更豐富了,像是官方這次設計了 Gather.Town (如圖一)讓各個與會者可以像是實際參與會議般在 Gather.Town 裏與其他與會者們互動。我是 LINE 台灣的資料科學家 Johnson,就由我來與各位分享這次的學術饗宴。
ICASSP 是什麼?
ICASSP,全名是 International Conference on Acoustics, Speech & Signal Processing. 是 IEEE SPS (美國電機工程學會 - 語音訊號處理分會)每年舉辦的國際學術會議之一,其組織 專注於數位信號處理、音訊處理、影像處理、通訊與多媒體系統、信息理論等領域之發展,而 ICASSP 正好在語音訊號處理上學術評價為最高級別的國際學術會議之一。儘管如此,會議上還是有呈現很多領域的研究,像是 NLP, CV 的論文也是會出現在這個會議當中。
Keynote (Plenary)
今年的 keynote 特別專注在深度學習 / 機器學習轉換到實際的應用上,第一位大師講者 Karl Friston 是從認知神經科學 (cognitive neuroscience) 與機器學習差異的角度出發,以強化學習 (Reinforcement learning)、離散時間動態規劃 (Bellman optimality principle) 的角度來看待大腦在做決策 (decision-making) 以及選擇實際行為 (behavior choice),是有多不同於機器學習通常在產出時是以預測編碼 (predictive coding) 與貝氏優化的方式進行。中間提出非常多的數學推導,有興趣的同學可以參考影片連結 (非常幸運的這個公開連結有許多部分是當天講者有涵蓋到的:
我覺得以 LINE 來說,這是個很值得思考的情境,我們有許多機器學習模型應用在服務當中,能夠應用強化學習做更近一步的效能提升,甚至是能有更合人情的決策。
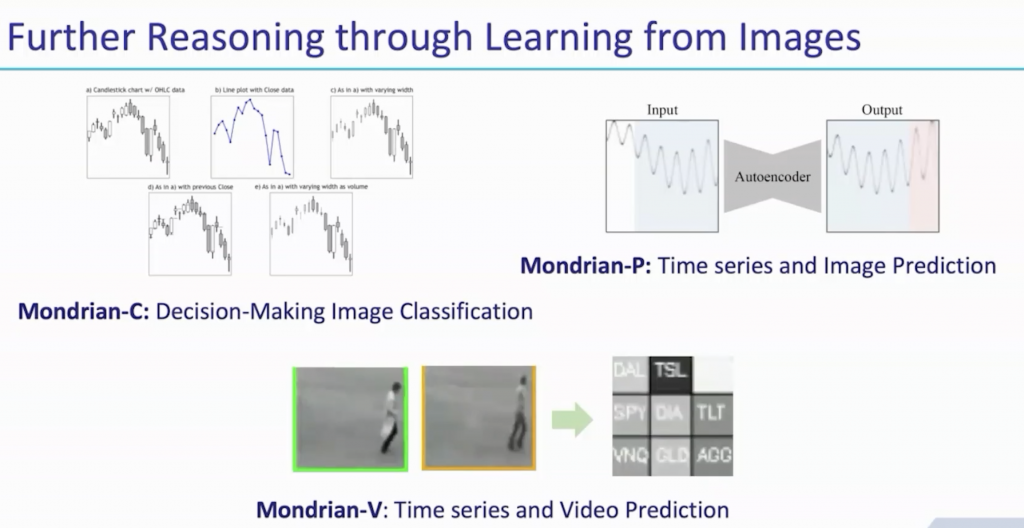
而第二位講者 Manuela Veloso 則帶來許多關於 Finance data 應用的觀點,其中有提到利用將走勢圖、訊號圖等資料應用成有時間序列 (time-series) 的圖像預測上來觀察該訊號在未來的趨勢走向(圖二),而很意外的,這些預測出的趨勢都不會與實際上的訊號圖相差多少。講者也有提出關於 multiAgent learning 的觀點,利用強化學習的概念在於學習市場決策者的行為模式。我想對於熟悉強化學習的讀者來說,可以透過講者分享的一些強化學習要件來了解這項應用是怎麼進行的(圖三),簡單來說,市場決策者(模型)需要去接收實際交易數據等等資訊(模型輸入),來學習該做出的對應,會是該為投資者定價、或是做避險庫存等等行為 (action),同時市場上會有一些反應 (reward):正負面反應甚至是處罰作為 agent 學習的反饋。這樣的模型很有效的幫助實際上的決策者判斷,在價格歪斜 (price skewing) 上做出及時修正以及正確避免需要執行避險庫存造成損失。關於 Fintech 甚至是 Martech,都是我們最近時常關注的新應用領域,關於 time-series 相關應用的研究與嘗試也是我們很重視的題目之一。講者後續還有提到非常多關於 finance data 應用圖像以及訊號儲利的案例都非常有趣,有興趣的讀者們可以參考講者提供的連結:https://www.cs.cmu.edu/~mmv/Veloso.html

最後一個我想與讀者分享的 keynote 是來自於北京清華的 Helen Meng 教授關於在語音辨識技術帶來的革新進步。首先講者提到關於資料不足 (data scarcity) 挑戰的應對方式。舉凡在為有構音障礙 (Dysarthria)、阿茲海默症與老年人的語音識別上都有資料數據不足的問題(僅 30 小時的數據),可以透過 data augmentation 的技巧再優化,講者有提到約提升 30 到 130 小時的數據量,錯誤率 (word-error-rate) 就能有效降低 5~10% 以上。接著講者提及應用 self-supervised pretrained model 帶來的效益。在 NLP 界我們有熟知的預訓練模型包含 BERT, XLNet, ELECTRA 等等透過大量資料預訓練的語言模型,在語音界就以 facebook 的 wav2vec (2.0) 為大家熟知(960 小時無標籤資料),而可以用少量(約 24 小時標籤資料),就能有效提升有嚴重口音的英語辨識錯誤率達 7~10% 以上。除了最近非常火熱的 self-supervised learning (SSL), 講者也提到應用元學習 (meta-learning) 的效益,有類似於遷移學習 (transfer learning) 的效益,meta-learing 專注在多個 task 的學習上的差異,讓模型可以透過學習 (across-task training) 擁有大量資料 task, 例如英語辨識,接著學習 (across-task testing) 僅有少量資料的目標 task: 例如構音障礙者的語音辨識,來完成快速降低並達到最低辨識錯誤率的模型,講者就有提到使用當今比較多人使用的元學習架構 MAML (learn to initialize) 加上 adapt to unseen speaker 帶來的效益。雖然我們在對於僅有少數資料的語音辨識任務還沒有這麼多著墨,但 LINE 本身也有進行大量語音辨識任務的訓練,以 clova 為應用的產品是大家最為熟知的,利用 data augmentation, 元學習來學習相對少量資料(如中文語音辨識)的任務對我們來說會是非常有提升模型表現的方法。
論文分享
這次 ICASSP 總共有 1757 篇論文被接受 (詳 https://2021.ieeeicassp.org/Papers/AcceptedPapers.asp),有很多不同領域的論文發表,這邊就我覺得幾個與 LINE 台灣開發最為相關的幾點來與各位分享。因為數量眾多,礙於篇幅有限,有興趣的讀者還可以去上面提到的連結了解更多內容。
unsupervised (pretraining) 與 self-training 的互補
paper: Self-Training And Pre-Training Are Complementary For Speech Recognition by X. Xu et al.
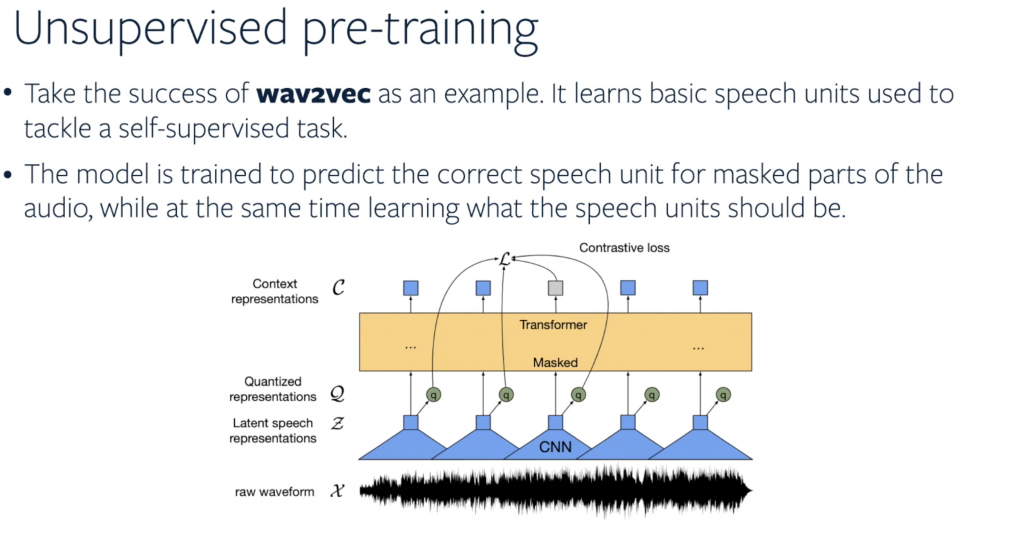
其實這幾年來 BERT 等等預訓練模型為各個 AI 服務在 nlp 領域帶來飛躍性的效能提升,在語音方面就有 wav2vec 的成功案例。圖四的投影片呈現了 wav2vec 是如何學習語音訊號的辨識,而 Facebook AI Research 提出了一種訓練架構,可以讓無監督式學習與自訓練能相互結合近一步提升 wav2vec 訓練成果。所謂的 self-training, 是一個很直觀的訓練方式,就是從原始 supervised model 開始透過重新標注無標籤資料進行不斷再訓練的過程。而無監督學習與自訓練這樣的結合方式如下:
- 用 (54k 小時) 無標籤資料預訓練模型 - base model
- 用 (960 小時) 有標籤資料 finetune 模型 - Fine tuned model
- 透過語言模型 (LM) 將 finetuned model 預測在無標籤資料上的結果轉錄 (decode) 成偽標籤 (pseudo label) 資料
- 少數的有標籤加上偽標籤進行(擇一)
- 訓練 sequence-to-sequence model (s2s model)
- 回到第二步 fine-tune base model (finetuned model)
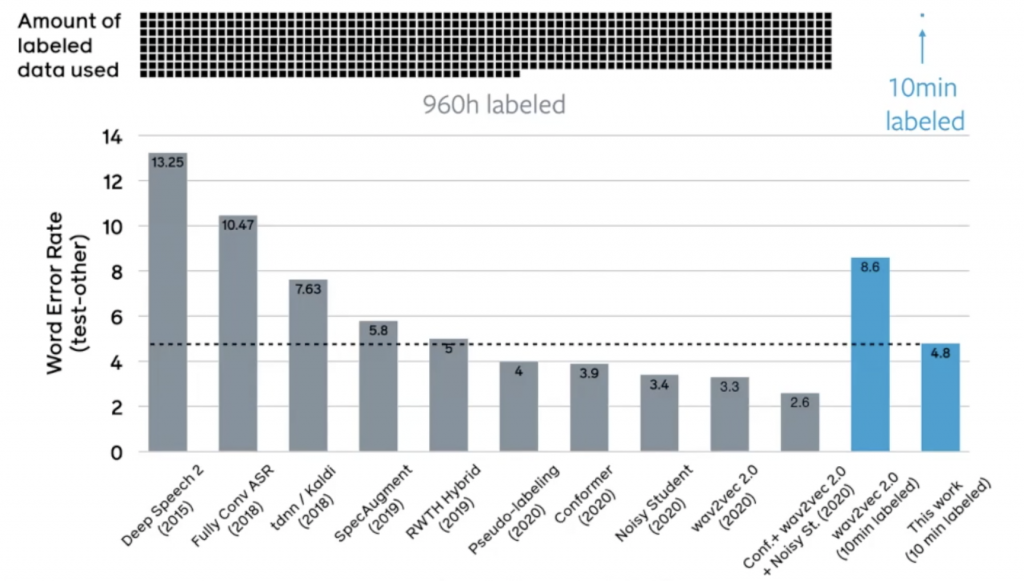
而結果上顯示,在有大量的無標籤訓練好 base model(遠大於有標籤)的前提下,可以在僅有 10 分鐘轉錄的偽標籤資料下,不管是使用 s2s 或是 finetuned model,效果可以在匹敵或是勝過 2020 年使用 960 小時有標籤資料訓練的監督式學習模型(圖五);而整體上,使用少量的標記資料進行第四步(少於 100 小時),都能夠優於 base model 表現。
在結果上來看,LINE 在語音識別上來看的確有很多值得學習之處,這種訓練架構可以很有效的減少我們對于有標籤資料的需求,但同時得依賴更大量無標籤資料訓練好的 pretrain model。在中文語音標籤數據偏少且不夠多樣的情況下,這是非常有幫助的一個訓練方式。
利用 Embedding 的方法以及 ANN 來加速並提升語音識別中的特殊名詞識別率
paper: Improving Entity Recall in Automatic Speech Recognition with Neural Embeddings by C. Li et al.
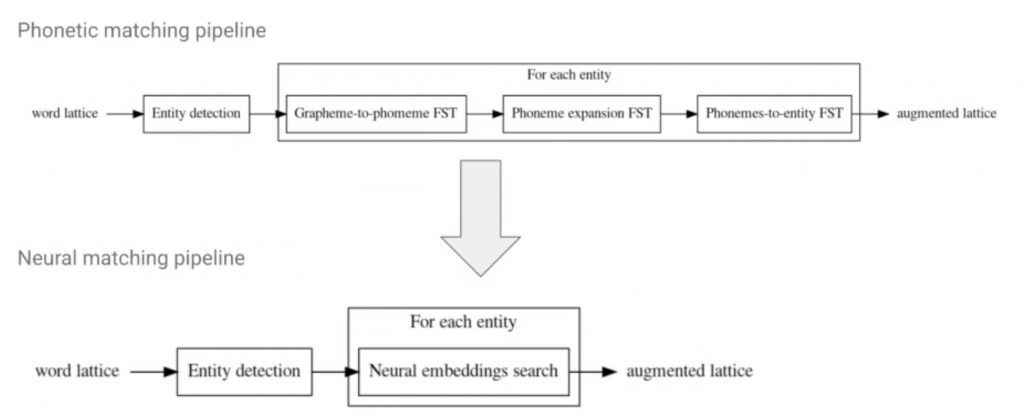
在自然語言處理的基本中,我們常常需要處理 out-of-vocabulary 的問題,意即模型沒有辦法處理他沒有看過的字詞。這個問題後續有許多方法來解決,比較簡單的方法會像是從資料端減少 oov 資料,或是增加資料粒度(從詞到字為單位等等);而在語音識別中,也會有需要將語音轉變成可識別的字句。而當句子中有特殊名詞出現時,一般的語言模型如果沒有經過處理會很難預測出當下用戶提及的特殊名詞是什麼。在過去 google 的解決方式是,會使用 entitty detection 模型,先判斷辨識語句中最有可能是特殊名詞的位置,並透過 phonetic maching finite state tranducer (FST, 有限狀態傳感器),事先將特殊領域的專有名詞每個字用編碼進去,透過計算 finite state 之間的音素與音素之間,字與字之間的最短距離來完成一個完整專有名詞的辨識。然而這是非常耗時的,同時也非常要求特殊領域的資料,以及在調整” 距離 “的公式計算上也非常不方便(像是利用 edit distance, 或是 cosine distance 得到的結果可能非常不同)。 所以在這裡 Google 提出了利用一個 embedding search 的模型來取代這段 FST 的機制(如圖六)。
所以基本上只要訓練透過一個 neural network base 的編碼器,可以將實際的 entity term (文字) encode 成詞向量,同時也去編碼這些 entity term 在發音上常被 ASR 模型辨識混淆 (錯誤) 的詞句成為詞向量,利用這一組組 training pair,使模型試著去學會這兩種詞向量應該要越相似越好。在細部訓練上,使用雙向 RNN 模型配上 236k 對詞向量組就能完成訓練。訓練完成後,可以利用 ANN 模型(例如 Google 的 ScaNN,Spotify 的 annoy), 在實際應用時快速將 ASR 辨識結果搜尋出最相似的 entity (相似定義是透過 cosine distance 決定)。在結果上,以熱門影視的 entity 來做辨識,可以有效降低 46% 的識別錯誤率,效果非常好,又能達到快速、不限制資料內容領域的條件。以 LINE 來說,我們也有使用到大量的 ANN 模型在向量快速比對上,以 entity matching 來說,我們在近期裡應用知識圖譜的專案中可以做為借鏡之處,令人期待有好的結果。
如何有效比較 self-supervised learning (SSL) 模型之間的差異
paper: similarity analysis on self-supervised speech representations by Y. Chung et al.
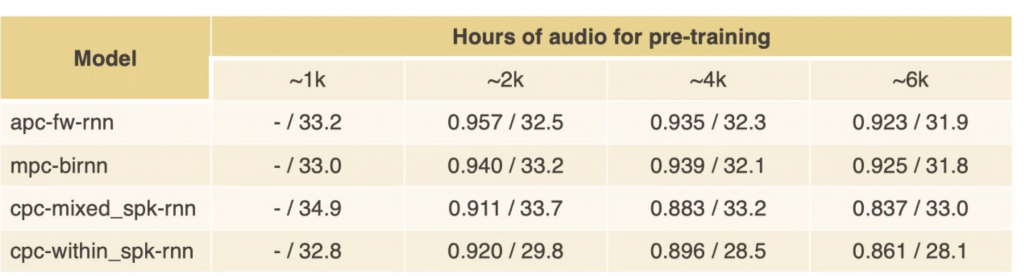
在 SSL 模型幾乎成為人人都會使用的時期,如何去比較不同模型之間的好壞可以透過各在 benchmark 上表現的好壞,或是用自己定義的 test set 來做。在語音上的 self-supervised learning 有很多,像是已知的 Autoregressive predictive coding (APC), Contrastive predictive coding (CPC), 就如同 NLP 界的 GPT 生成模型(APC 與 CPC 彼此稍有差異,各位可以想像 CPC 是多使用了負採樣訓練來避免生成結果分佈類似負樣本,但兩者仍然使用自回歸 (autoregressive) 的方式來訓練),利用無監督的自回歸的生成性訓練來完成模型對資料的理解,還有像 Masked predictive coding (MPC), 類似於 NLP 界的 BERT, 透過去預測 Masked phoneme 的方式來訓練對資料的理解。而他們之間對於不同的預訓練資料量、使用不同的 neural network 組成結構、還有不同損失函數訓練出來的結果都有差異。這篇作者用一個比較系統性的整理來讓大家更好理解這些選擇上會造成的差異。我覺得這樣的比較有助於日後對於不同自監督學習模型的各種訓練結構理解跟選擇。
在預訓練資料多寡造成的影響上,使用越長的預訓練資料訓練,很直覺的生成結果上會與預訓練模型本身相似度差異越大(如圖七)
而在不同損失函數、網路組成、甚至是單 / 雙方向性的組成比較,作者用一個相似度的熱圖做呈現(如圖八),呈現區塊上的差異性,顯示出影響模型產出本身的要素的影響程度各自不同,在這裏的影響重要度分析是呈現 損失函數 (CPC,APC,MPC)> 單雙向 (forward, backward, bi-directional)>NN 組成結構 (這裡選擇是 CNN, RNN, Transformer)。意即影響模型結果最深的其實是損失函數(如開頭提到的 APC, CPC, 還有 MPC),接著會是模型解讀資料的方向性(向前、向後、雙向),最後才是大家熟知的模型結構本身的差異(cnn, rnn transformer)
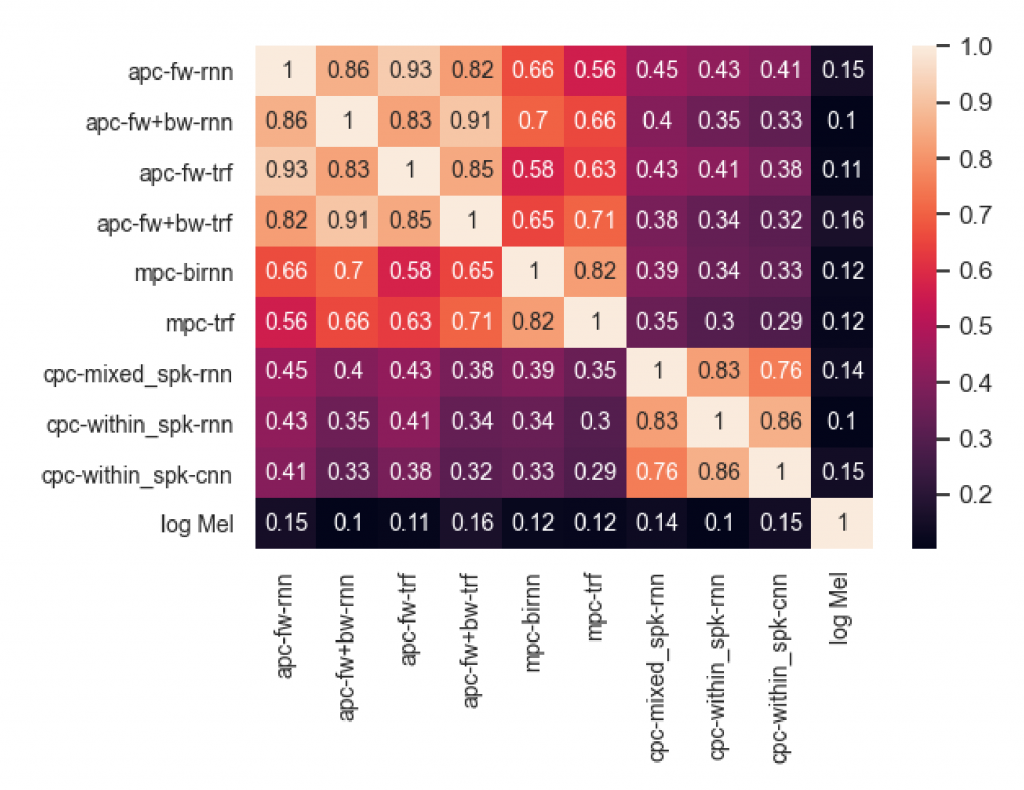
這樣的分析其實很有幫助,尤其是釐清各個不同要素之間選擇的重要性,分析做起來其實挺耗訓練資源(不同資料量、訓練組合都要訓練一次),所以有這樣的分析可以幫助我們加速在模型訓練上的效率跟應用選擇。
結語
這次的 ICASSP 其實是因為去年開放免費註冊的關係,吸引了很多非 IEEE 或是不熟悉語音領域的開發者以及學者們參加,所以今年的與會者也非常的多,很感興趣的主題也非常多。
很高興 LINE 依然能鼓勵員工在像這樣無法出國的情況下參加國際學術會議,並全額贊助我們參加 tutorial 以及註冊大會等等費用。一方面可以帶回許多值得借鏡的方法,一方面也學到更多最新的機器學習理論。
若你也是相關背景且對於 LINE 的資料工程團隊職缺很有興趣的話,歡迎投遞你的履歷一起加入 LINE 的大家庭 (請參考下面職缺連結):
希望以上的分享內容能夠讓各位讀者也能滿載而歸!感謝各位的收看。