
Google近年來積極的整合機器學習的雲端服務平台與服務,致力於對各種角色的開發者提供不同的解決方案,並在今年舉辦Google Developers ML Summit Taipei 2019,在會議中展示新服務的同時,也透過Codelabs帶領開發者免費體驗服務的優點。LINE雖然在雲端服務這塊沒有直接使用Google的解決方案,但是公司非常鼓勵開發工程師可以多參加外部的研討會,吸取外部的經驗來充實內部的產品。
今年的活動由Google的技術傳教士上官林傑開場,介紹了Google ML的幾個亮點產品:除了TensorFlow 2.0的推出讓使用者進入deep learning的門檻降低外,對Mobile與IoT開發者來說,TensorFlow Lite可支援在手機甚至是Edge TPU上跑輕量化的TensorFlow model,也可以直接用ML Kit + Firebase快速開發app的AI功能;對前端開發者而言,用TensorFlow.js就可以輕鬆訓練模型,讓訓練過程視覺化 (例如:https://playground.TensorFlow.org)。而為了解決大部分人想要用deep learning但苦無data的痛點,使用Cloud AI就可以輕鬆連結Kaggle資料,或用Auto ML有效的利用小dataset來訓練模型。最後也可以透過Google Colab平台來體驗TPU威力。
整天的議程內容圍繞著4個重點講題:1. TensorFlow 2.0 & Cloud TPU, 2. Cloud AI & Auto ML, 3. ML Kit for Firebase, 4. Action on Google,非常充實緊湊,並在最後針對這4個項目分組進行Codelabs,參加者可以針對有興趣的項目實際操作體驗,增強學習效果。
TensorFlow 2.0 Updates
講者: 佐藤一憲 / Kaz Sato, Developer Advocate, Cloud Platform Google
TensorFlow 從誕生至今 3 年多已經成為使用率最高 deep learning framework,但由於 TensorFlow 是基於 Google 自己的需求開發而成,存在不少讓 developer 十分困擾的問題 (例如 runtime debug 不易、很多 duplicated 和 depreciated API),2.0 的釋出大幅解決上面這些問題,Google 要讓 TensorFlow 更好開發好上手。
TensorFlow 2.0 改版項目主要有下述幾項:
- 預設模式調整為 eager execution
- 清除棄用 API,減少重複,簡化 API
- 深度整合 Keras API,開發者可以根據需求選擇適合的 API
- 統一交換格式和並對齊 API 讓 TensorFlow 可以支援更多平台和語言
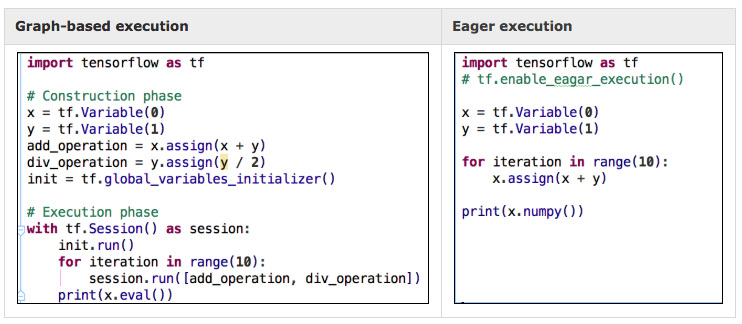
Eager execution 模式下 TensorFlow 會從原本的 declarative 切換成 imperative,使用起來更為直覺且可隨時偵錯。在 eager execution 中執行 tf.multiply(a,b) 可以直接操作並得到值,無論是用 print("y:{}", y) 或是使用 Python IDE debug model 進行調適都相當方便 (附加說明: tf.* function 不需要像以前一樣需要透過session.run())。如果開發者想要讓部分 code block 切換成 graph-based execution,也是做得到的,只需要在 def function name 上面加上 @tf.function 就會切換成graph-based execution 模式,這個 code block 一樣可以擁有 graph model 的所有優勢 - performance 最佳化、遠端執行、序列化與部署容易。
用過 TensorFlow 的開發者肯定對 tf.contrib 模組不陌生,下面放了非常豐富的子模組,功能十分強大,但存在許多 unstable 和 experimental codes。目前 tf.contrib 規模太龐大,已經超過正常一個 repository 可以維護的範圍,而且模組中又常出現其他模組相似功能,在 TensorFlow 2.0 中決定除了部分有維護價值的模組會移到其他地方,其餘的都全部刪除 (包含 high-level APIs 例如 tf.contrib.slim 和 tf.contrib.learn)
有鑒於 TensorFlow 開發者經驗水平不同,keras 提供 sequential, functional, subclass API 以滿足大部分需求。但如果如果這些 API 都不是很合適時也可以自行建構,例如把 tf.keras.layers 和其他 Keras 模型分開使用,自己做 gradient 和 training 實作或者是單純使用 TensorFlow + Python + AutoGraph 來實現。
TensorFlow 另一個強大之處為支援各類常見裝置,使用 SavedModel 將資料序列化後可部署到 TensorFlow Serving、TensorFlow Lite 以及 TensorFlow.js 等項目。
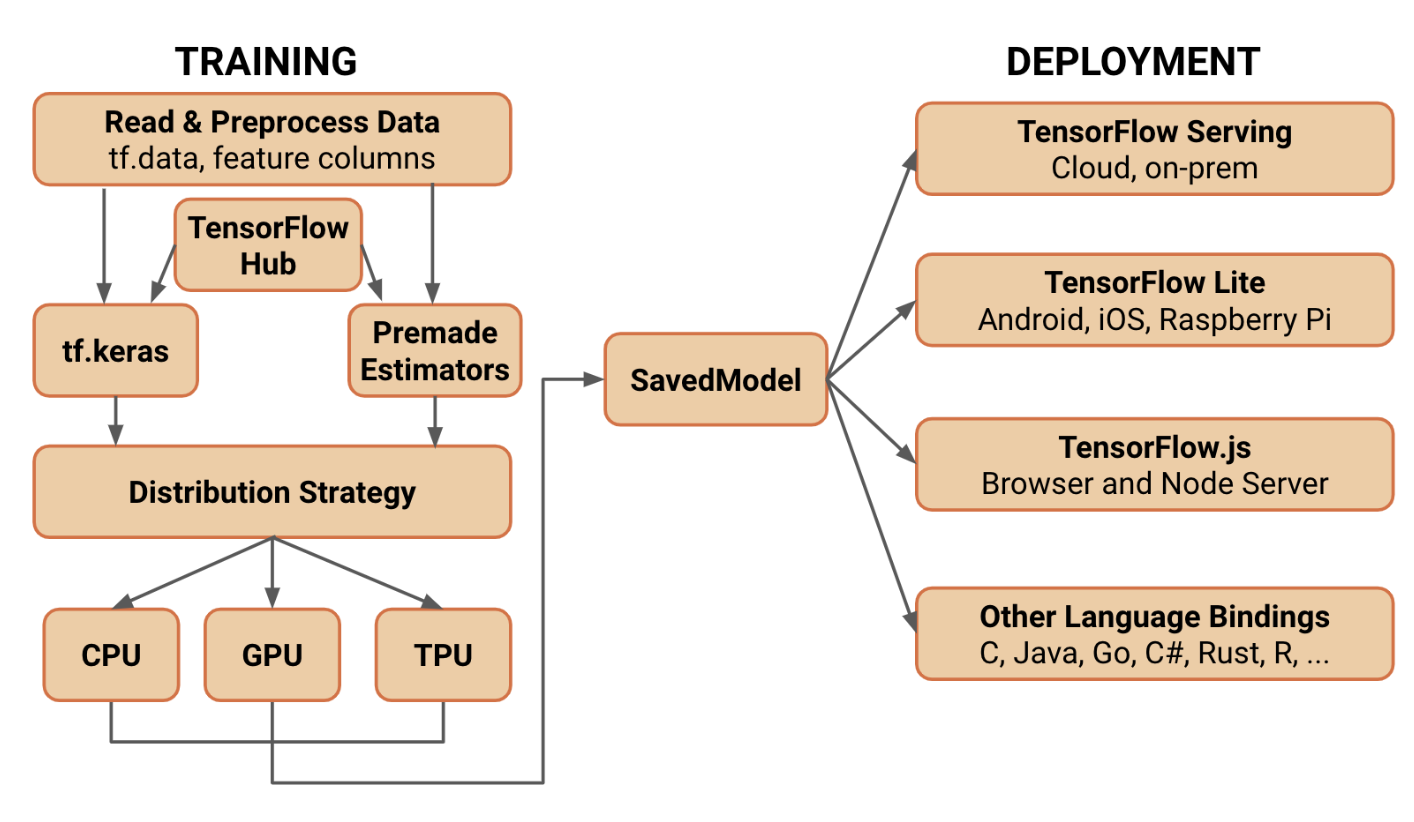
出處:What's coming in TensorFlow 2.0
TensorFlow and Cloud TPU
講者: 魏澤人 / Tzer-jen Wei, Google Developers Experts (Machine Learning)
Google在2016年五月推出專為機器學習(Machine Learning)相關服務設計的晶片 – TPU(見圖一)。TPU(Tensor Processing Unit)全名為張量處理器,是為了Google開源的機器學習庫TensorFlow所量身訂作的晶片,用來加速在Google Cloud Platform上的AI服務,如Google翻譯、Google助理。這也是2017年AlphaGo只用一台擁有TPU的電腦就擊敗了當時世界第一棋士柯潔的秘密武器之一。

圖1 Tensor Processing Unit 第一版[1]
但TPU解決機器學習的什麼問題?精確地說,TPU解決:
- TensorFlow上處理複雜張量 (高維度向量)運算的冗長計算時間:受惠於TPU僅處理類神經網路(neural networks)相關的預測工作,優化常出現在類神經網路中的矩陣運算結構;
- 改良運算過程中硬體的體積及功耗的問題:選擇以整數運算為主體(第一代運用了8-bit integer),進而讓晶片設計極小化。
我們可以進一步從硬體架構來了解TPU。從圖二的TPU硬體架構圖上的許多命名方式,可以看出TPU特別針對類神經網路中的每塊重要計算過程在個別區塊處理,如activation或是Pool。在架構上,TPU配置協同處理器(coprocessor)在PCIe I/O Bus上縮短存取時間。另外,TPU擁有大量到on-chip DRAM可以同時將存取類神經網路中隱藏層的權重以及將權重載入激活函數(activation)。值得一提的是最主要的核心:Matrix Multiply Unit(MXU)。MXU包含了256×256256×256運算單元(ALU) ,可在每個時脈週期(clock cycle)產生256元素的矩陣乘積中的部分和(partial sums)。
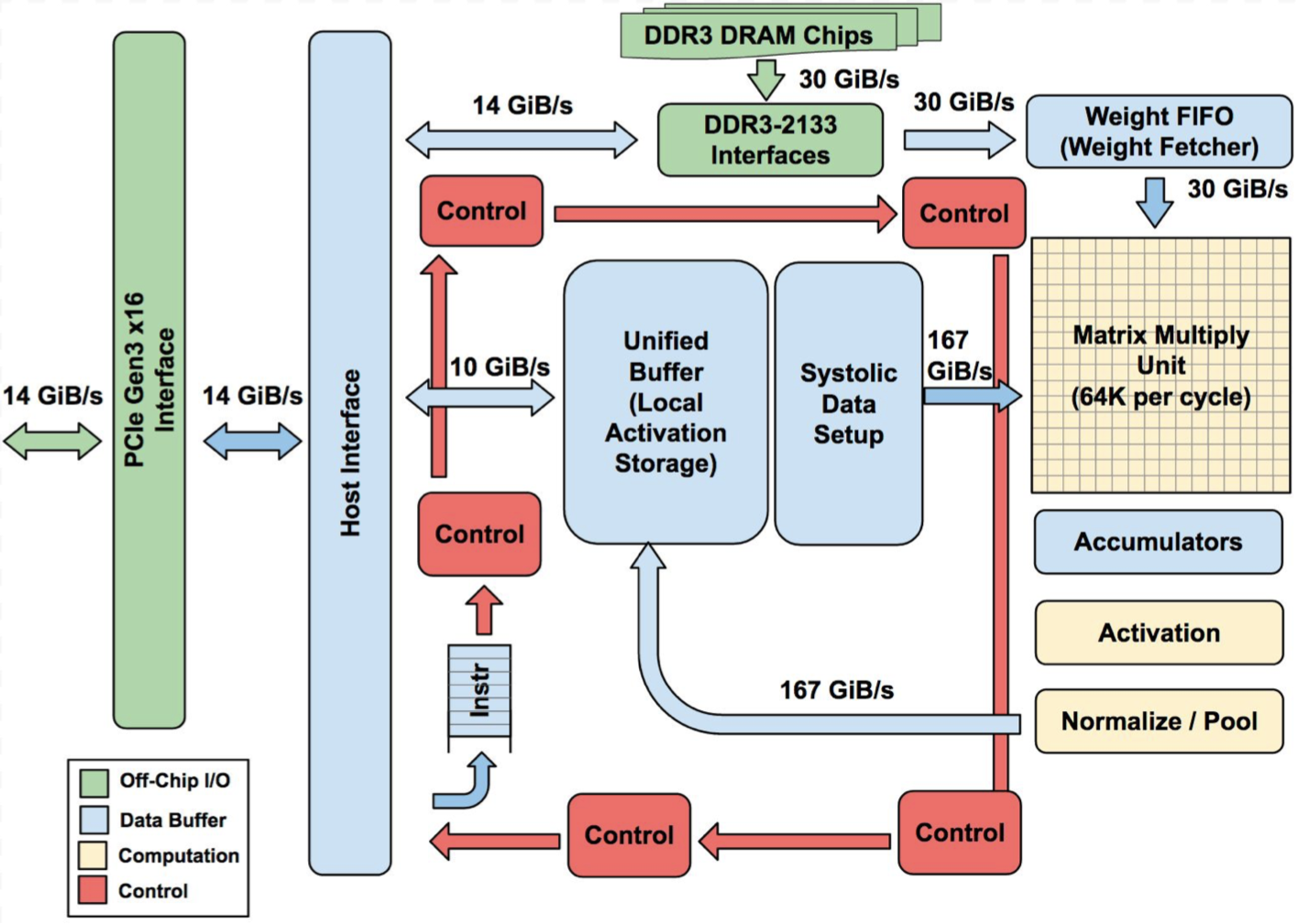
圖2 TPU架構圖 [1]
在此與GPU不同的地方為,TPU計算矩陣乘法並非如GPU一般:一次只能做一個向量運算,而是透過脈動陣列(systolic array)方式一次將矩陣相乘結果產出(見圖三)。脈動陣列也是TPU在處理類神經網路會比NVIDIA Tesla K80 GPU和Intel Haswell CPU快上至少15到30倍速度的原因之一[2]。更多TPU、GPU的比較請見: https://iq.opengenus.org/cpu-vs-gpu-vs-tpu/。雖然TPU擁有運算速度上的優勢,但因啟動TPU速度很慢,使用者盡量不要在Google Cloud Platform上用TPU處理運算複雜度過低的工作,否則荷包會損失過多卻沒得到該有的價值。
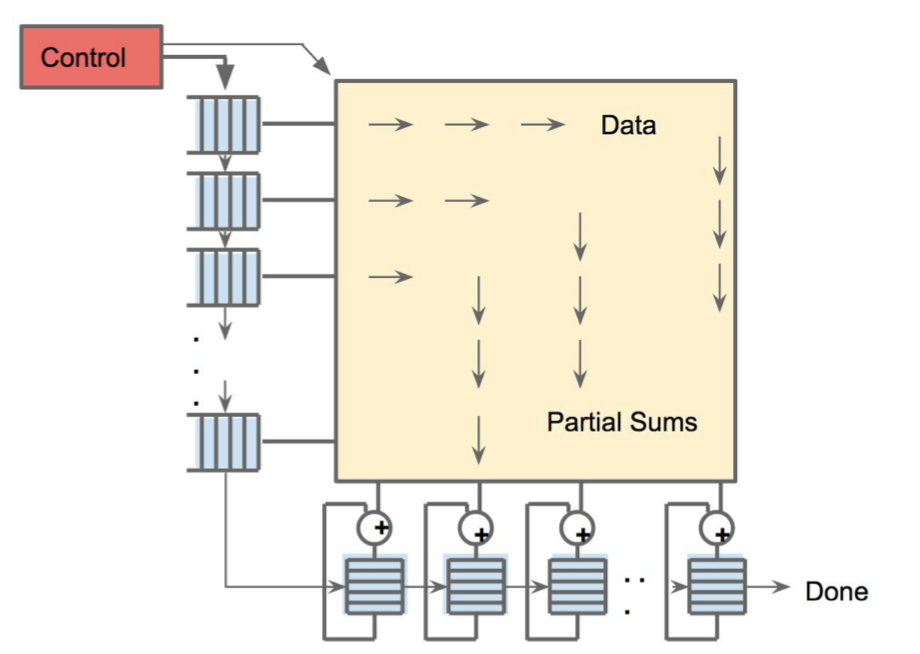
圖3 脈動陣列運算方式 [1]
目前Google Cloud上的TPU為第二版(見圖4-1),第二版的TPU除了大幅度改良TensorFlow所需的訓練時間,也容許與TPU其他硬體兼容運行,如NVIDA GPU。更重要的是開放讓使用者構建機器學習的超級電腦,亦稱為TPU Pods(見圖4-2)。TPU Pods為2D環面網狀網路架構,而且每個TPU都有高速網路。對TPU第二版有興趣的讀者可以詳閱文獻[2](註:第一作者為Google傳奇人物Jeff Dean,參與過MapReduce、TensorFlow等開發)。另外,Google Cloud Platform上在2018年的五月開始提供第三代TPU,速度更是以每秒 420 萬億次浮點運算[3]。


圖4 TPU第二代硬體 [2]
目前TPU僅支援特定的類神經網路模型(請見: https://github.com/TensorFlow/tpu/tree/master/models/official),若想用TensorFlow執行大型的深度學習(Deep Learning)應用,可以透過Google Cloud上提供的Quick Start範例來更深入了。
Reference:
[1] Norman P. Jouppi, et al. (2017). In-Datacenter Performance Analysis of a Tensor Processing Unit, ISCA.
[2] Jeff Dean and Urs Hölzle. (2017). Build and train machine learning models on our new Google Cloud TPUs, Google Cloud.
[3] Paul Teich (2018). Tearing Apart Google's TPU 3.0 AI Coprocessor, The Next Platform.
Cloud AI: A New Wave for Developing Machine Learning Applications & Could AutoML codelab
講者: 林書平 / Harry Lin, Customer Engineer, Google Cloud
講者一開始提到在Google Cloud Platform (GCP)上做機器學習開發有三種方法:第一種,你有自己的資料,並且用這些資料開發自己的模型。那你底層可以用Cloud TPUs,平台可以用Kubeflow建構,上層可以用Cloud ML Engine管理與BigQuery分析;第二種,你有一小部分自己的資料,但沒有資源開發自己的模型,那麼,你適合用AutoML來建立模型;第三種,你沒有資料,也沒有資源開發模型,那你可以呼叫已經包好的APIs例如Cloud Vision API,Cloud Nutural Language API,Dialogflow等。
其中AutoML是透過Google Brain在2017年發表的NAS (Neural Architecture Search)算法產生出來的,這個方法可以用機器學習來產生類神經網路的結構,簡單來說,就是自動產生機器學習的模型。NAS算法是用RNN作為控制器,挑選排列出某個end-to-end的架構,並不斷計算梯度更新控制器讓他收斂 (如下圖)。實際上透過Google Cloud AI去使用AutoML的話,你只需要有一份小的訓練資料集,AutoML會自動幫你算出一個雖然小但效能還不錯的模型。用這個方法的確解決了建模工程師的困擾,省去了要花時間一一排列組合找出最好模型架構的麻煩,但也相對需要龐大的運算資源。
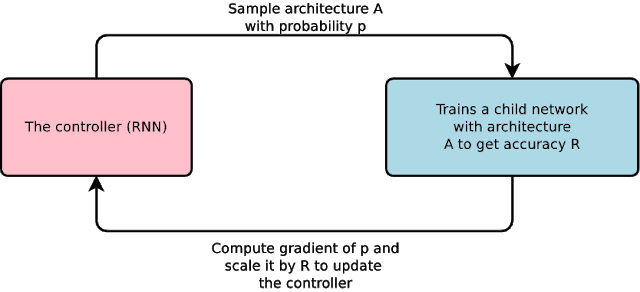
出處: Neural Architecture Search with Reinforcement Learning
這個方法原理雖然聽起來很複雜,但透過主辦單位安排的Cloud AutoML codelab體驗,會發現實際在平台上調用用起來非常簡單。由於AutoML 目的是自動調參數不斷訓練模型直到某個最佳化的結果,省去建模工程師大量調參數與試誤的時間。在codelab session裏,讓大家體驗從一些(數十張)雲朵的圖片,透過google提供的服務加上AutoML來訓練出能夠自動判斷雲朵圖片類型(如:卷積雲)的classifier。AutoML將之定義為"AutoML Vision"子服務。
做lab過程,可看到AutoML介面分幾個步驟如圖所示
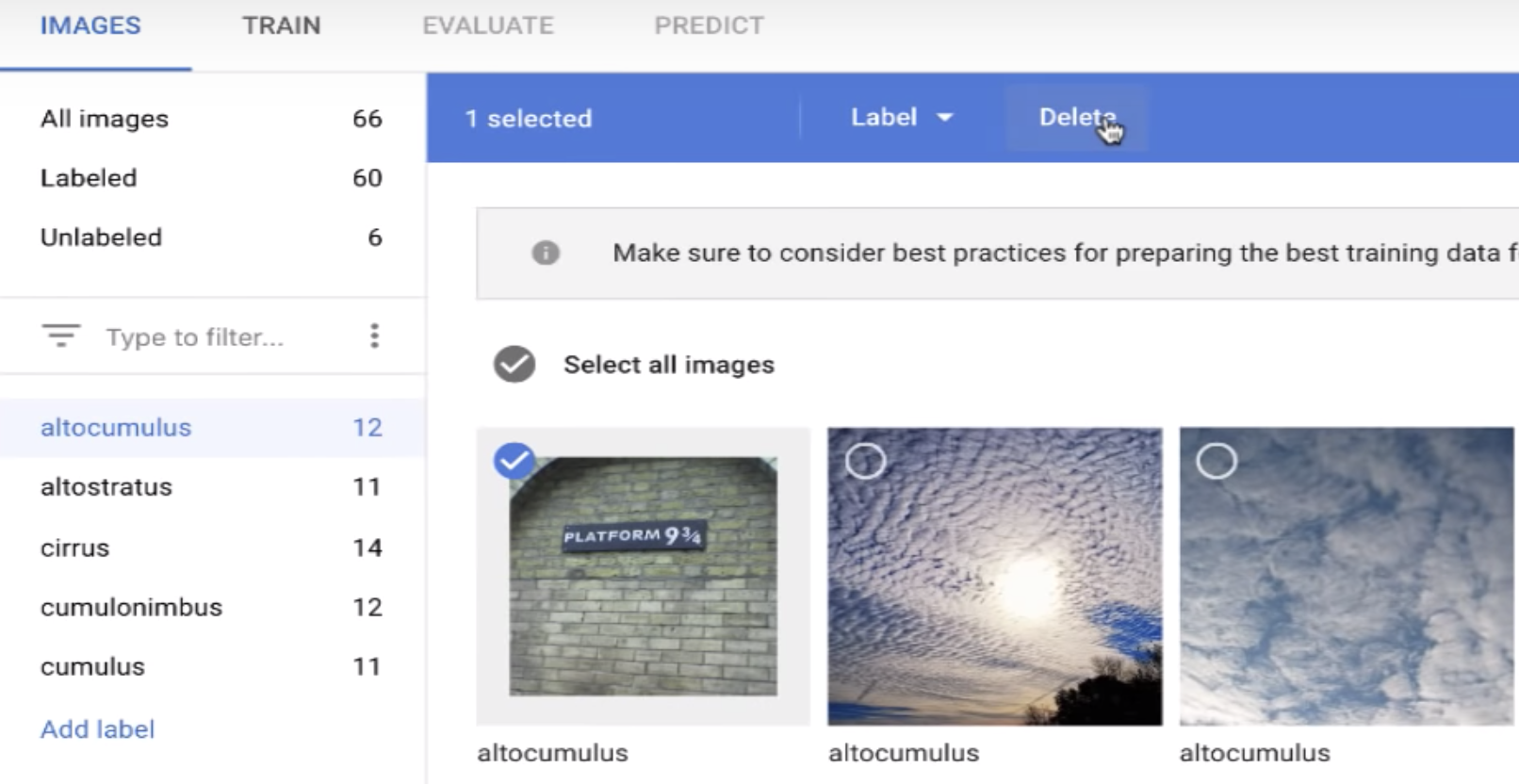
source: https://cloud.google.com/vision/automl/docs/
1. Images
管理training data,可上傳標記好的圖片集,也可以上傳未標記的圖片集,然後再線上手動標記。上傳圖片都是透過google storage相關服務存放,讓user不用考慮到size太大與HA的問題。並且可作基本label變更與data新增刪除的功能。
2. Train
這步驟user不需要介入複雜繁瑣的hyper-parameter tuning過程,只需要有些耐心等待training的結果。根據說明,training會使用google cloud的基礎建設與GPU/TPU,以發揮很高的效率。
3. Evaluate
當Training完成後,Evaluation階段會看到如以下畫面,包含主要classification的metrics讓user評估model的performance。
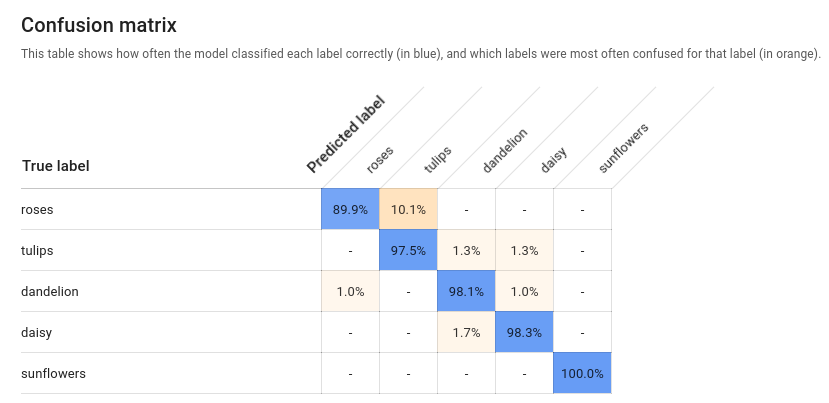
source: https://cloud.google.com/vision/automl/docs/evaluate
4. Predict
可實際測試training data以外的圖片看model predict的結果,如圖
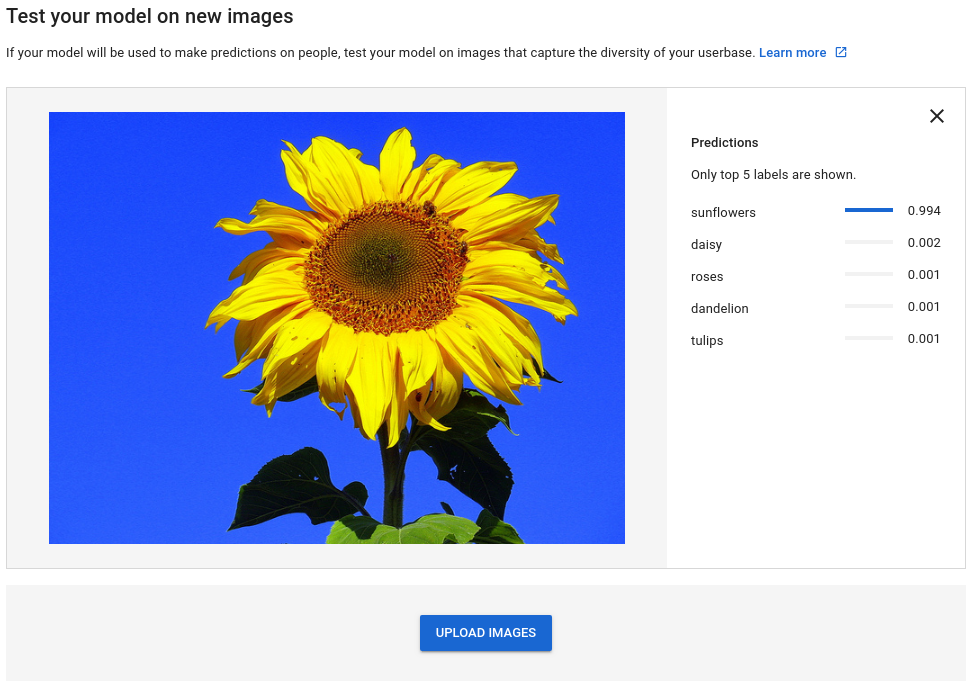
source: https://cloud.google.com/vision/automl/docs/predict
也可用API介面來做prediction
目前得到的訊息是透過AutoML training出的model目前只能deploy到google cloud並以API形式提供prediction,並無法搬移到其他地方做更近一步的應用。且Cloud API的SLA目前只有default一種,無法按user需求調整(如:1秒達到多少rps, response time多少以內等)。
所以目前看起來AutoML對training在人力資源上會有極大節省,甚至在某些情況效果會比人工調教的好,但相對能客製化的空間較小,且deploy model的選擇有限,實際評估時需要考慮合用的情境。
Bringing modern AI to your apps with ML Kit for Firebase
講者: 李致緯 / Richard Lee, CTO / Co-founder Polydice
Google 旗下的 Firebase 對於 App 開發提供了豐富的資源,這一場演講分享了使用 ML Kit 的經驗。近幾年來,機器學習的普及帶起了一輪服務體驗的改善與升級,然而機器學習系統流程的建立,是一個非常龐大的工程,從搜集資料,整理資料,標記資料,選擇模型,訓練模型,調整參數,然後反覆整個流程以優化準確度與效能。這是一個非常複雜與困難的工程,沒有足夠資源的團隊要從無到有打造一個,成本非常巨大。講師在演講中提供了他的心得,對於新創團隊,更重要的是把力氣花在特定領域的問題上,而非重複這個過程。
而 Firebase ML Kit 就是一個可以應用在 app 內,提供機器學習功能的實作,包含了 pre-built 的模型。ML Kit 提供了幾種常用的機器學習功能,例如:Image labeling, Text recognition (OCR), Face detection, Barcode scanning, Landmark detection, Smart reply (coming soon)。站在巨人的肩膀上可以很快的把機器學習的能力導入到產品中,提升產品的使用體驗。
Actions on Google Overview & Actions on Google codelab
講者: 林建宏 / Wolke Lin / Google Developers Expert (Assistant)
Google Assistant是Google開發的虛擬數位個人助理,使用者能夠透過對話方式與系統互動表達意圖,進而滿足像是打電話、查詢當地天氣、播放音樂、記錄購物清單以及設定提醒等等各種不同的日常需求。
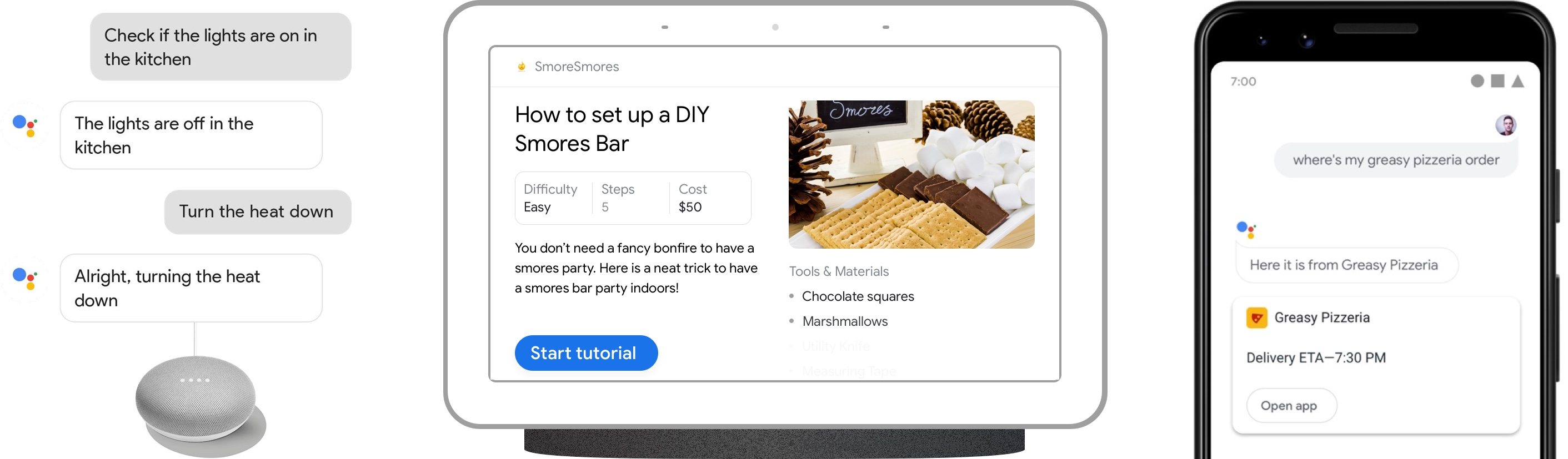
source: https://developers.google.com/actions/overview
但是對於一些特殊領域的需求,則必須要透過開發Actions on Google應用來擴充Google Assistant的功能。但對於開發這種類型的互動方式,最重要的一環是必須要能了解夠使用者透過自然對話(NLU, Natural Language Understanding)所表達的意圖,這對於一般不具備自然語言處理(NLP, Natural Language Processing)能力的軟體開發者來說是一個非常高的門檻。為了讓開發者能夠專注於應用本身,Google提供Dialogflow作為自然語言處理的解決方案,幫助開發者打造更好更精準的服務體驗。
接下來將會透過流程圖說明Dialogflow處理使用者需求的步驟以及使用Dialogflow所需具備的基本知識:

source: https://Dialogflow.com/docs/intro/fulfillment
- 使用者透過語音對話或者是文字表達他的需求。
- Diaglogflow將使用者輸入的句子對應到開發者所定義的意圖(Intent)。
- Diaglogflow解析使用者的輸入,萃取出語句中的主體(Entity)以及參數(Parameter),對於較為複雜的需求,會需要將抽出來的主體以及參數透過Api丟到外部的服務端來處理,這個開發出來用於滿足使用者意圖的邏輯就叫做Fulfillment。
- 最後一步就是將Fulfillment回傳的結果透過Dialogflow包裝後回傳給使用者,可以是語音回覆或者是影像圖片等等類型。
了解以上的概念之後,就可以開始著手打造自己的Actions on Google應用囉。接著將會利用「水果姐接」這個提供水果產地以及價格查詢的應用來詳細說明如何訓練Diaglogflow辨別意圖以及抽出主體和參數。
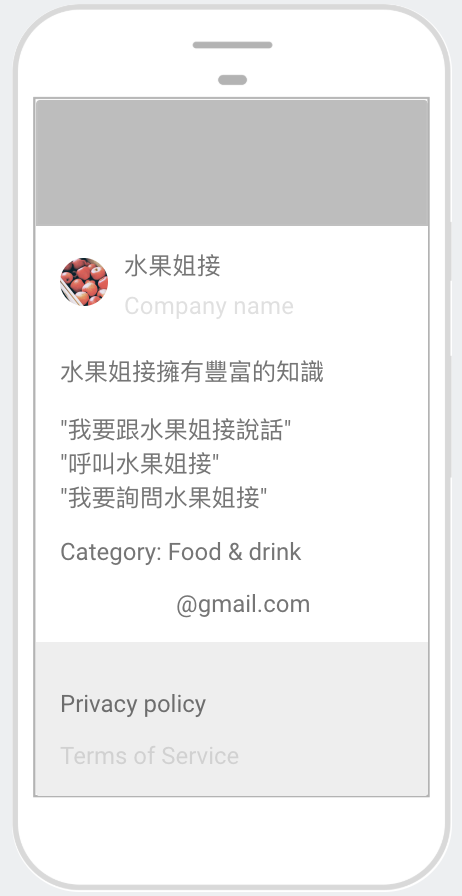
這個應用包含了四種意圖:
- Default Fallback Intent: 提供基本回覆讓使用者了解所描述的需求超出應用範圍。
- Default Welcome Intent: 提供基本的的問候對答功能。
- fruitOrigin: 查詢水果產地。
- fruitPrice: 查詢水果價格。
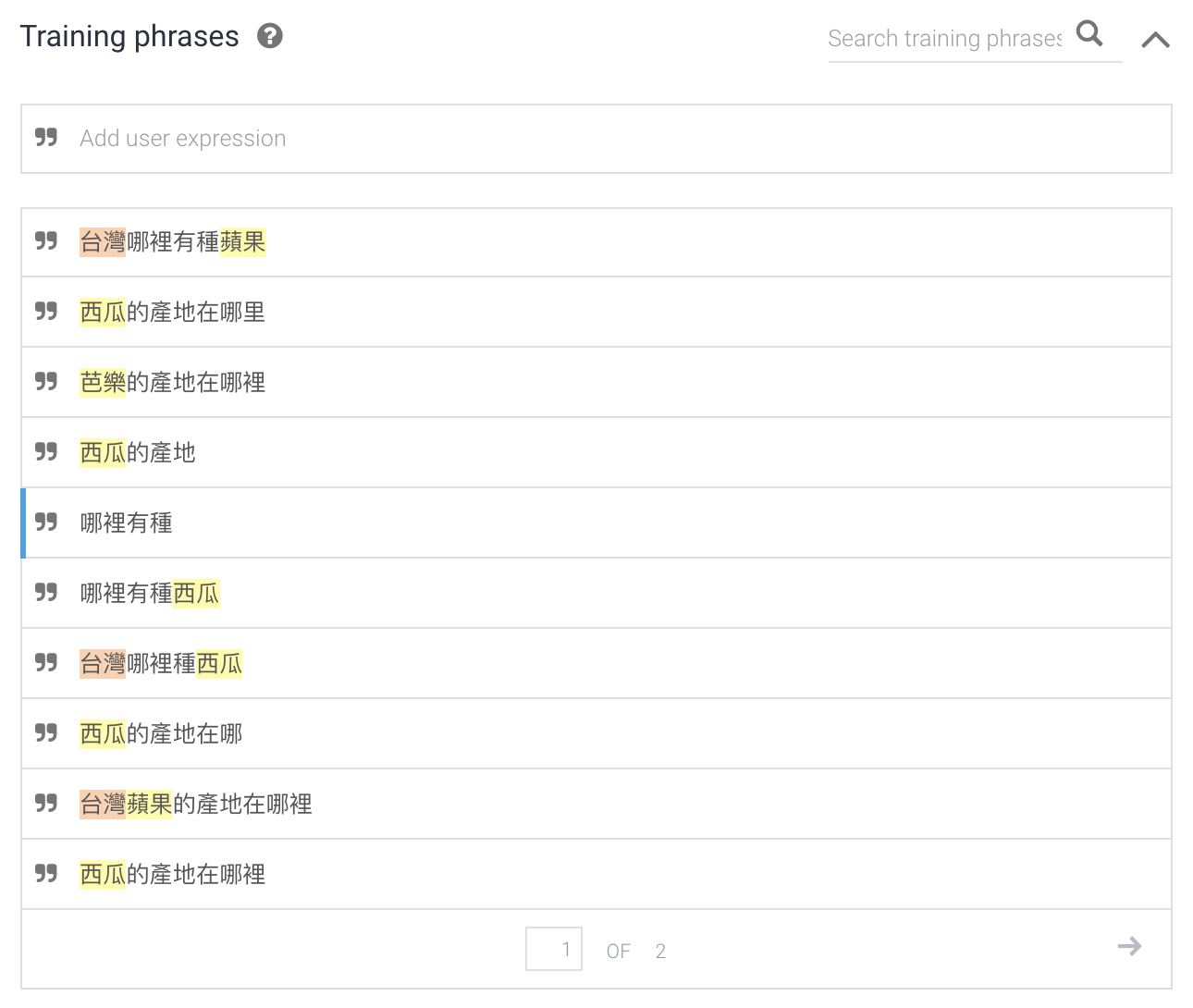
以查詢水果產地為例,每個使用者習慣的描述方式不盡相同,Dialogflow讓開發者可以自行定義多個句型範例作為機器學習的訓練資料(training phrasese),來提升辨別意圖的正確率,並且能夠抽取出語句中主體及參數。下圖左是各種針對水果產地的問句,藉由標註出句子中主體的位置,就能夠訓練Dialogflow理解如何抓出關鍵詞。此外,針對使用者輸入缺乏關鍵主體的狀況(例:哪裡有種),加入提示句(例:你想要問的是什麼水果呢?)讓使用者能夠立即補充對應的主體。
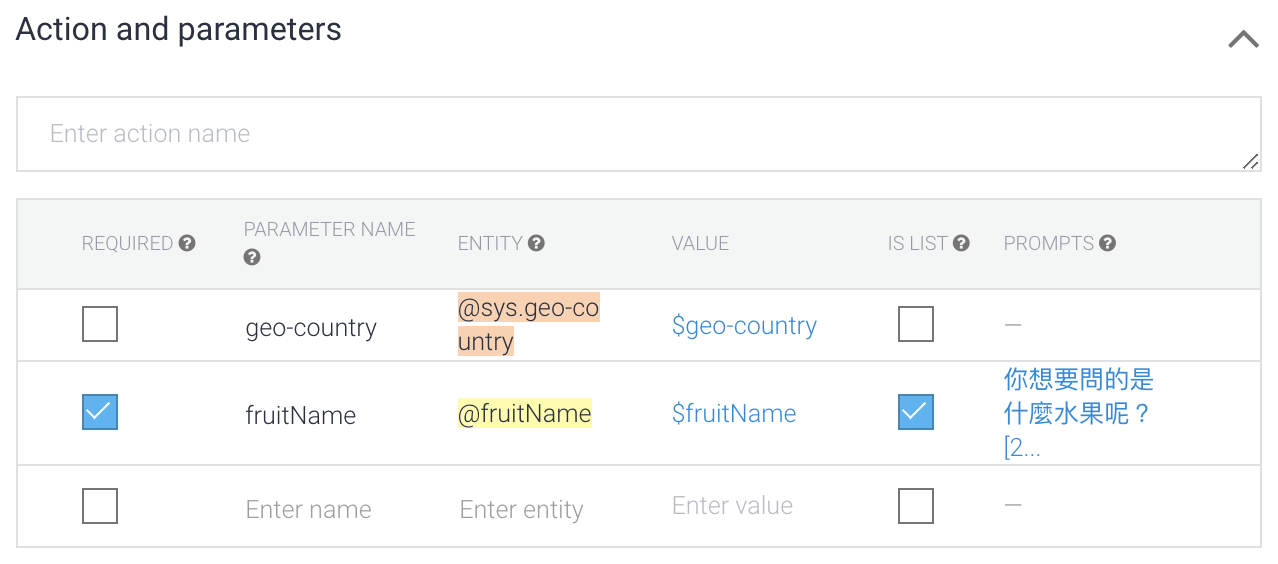
接著,可以簡單地透過制式的範本將$fruitName置換為問句中的主體水果名稱產生回應。若邏輯較為複雜,答案必須要動態查詢之後才能組織成句子作為回應,則可以開啟Fulfillment的webhook設定將主體及參數透過傳遞到外部系統進階處理。
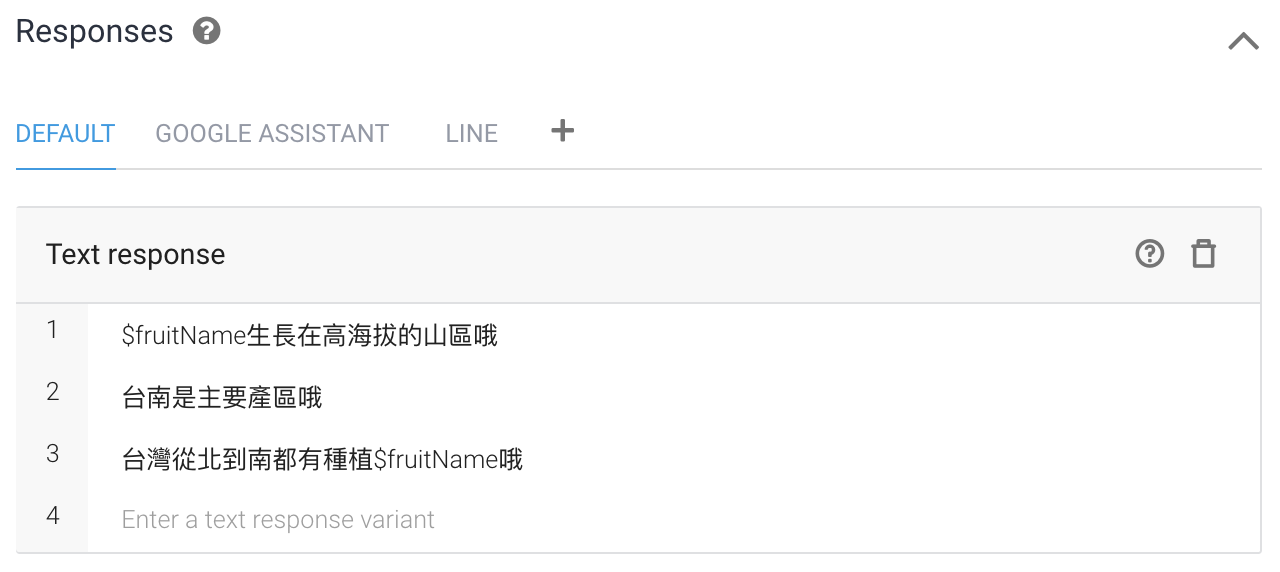
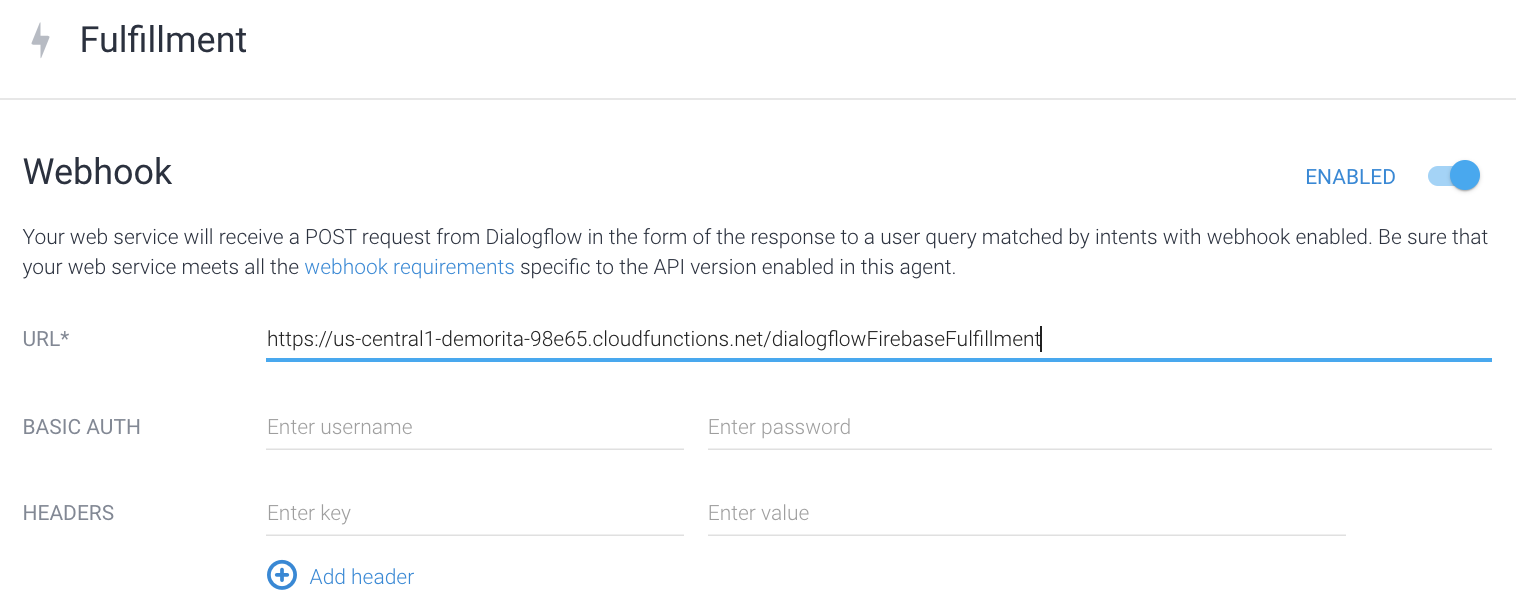
以上就是建構Actions on Google應用的基本方式。另外值得一提的是訓練好的Dialogflow專案除了跟Google Assistant整合外,也能跟其他各種對話機器人平台介接。以LINE官方帳號為例,只需要在Dialogflow開啟LINE bot整合填寫認證資訊,再把目標官方帳號的Messaging API webhook設定為Dialogflow,就可以把整套功能完整移植到LINE的平台。可以參考以下說明文件。
- 如何申請LINE官方帳號:https://www.linebiz.com/tw/service/line-account-connect/
- 如何整合Dialogflow和LINE官方帳號:https://cloud.google.com/dialogflow-enterprise/docs/integrations/line
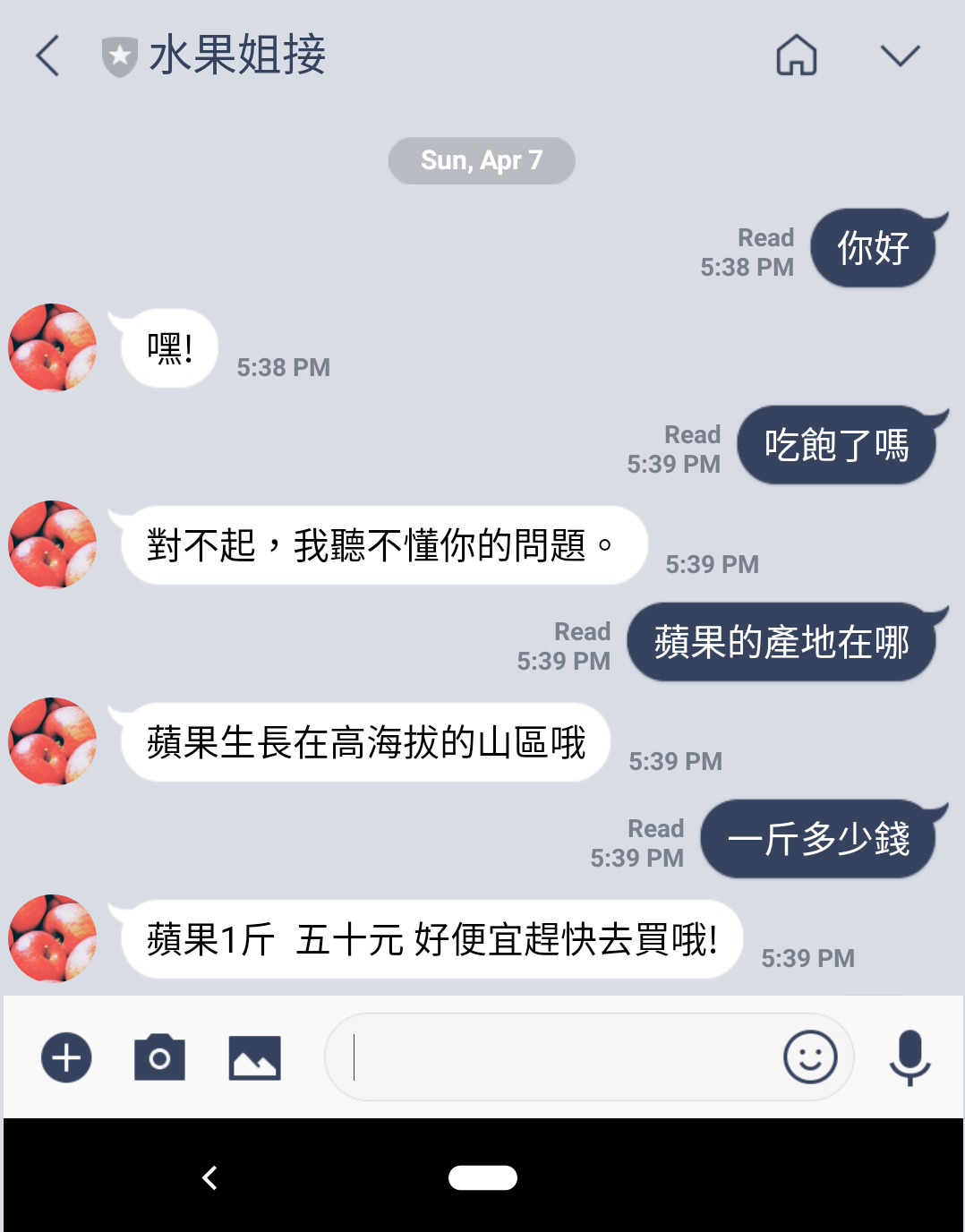
整天的議程涵蓋的內容相當廣泛,經由Google技術專家們的介紹,讓我們對於Google在機器學習領域提供的各種平台上的進展有了更深的認識。活動內容也包含了動手練習的 Codelab 時間,在講師的帶領下,透過實際的操作能更快熟悉這些的技術。很感謝公司鼓勵大家參加外部的訓練課程,相信今後對於要將機器學習應用在產品面會很有幫助。