
안녕하세요. 저는 LINE+ UIT 조직에서 프런트엔드 개발을 하고 있는 이상철입니다. 저는 UVP(Universal Video Player)라는 사내 동영상 컴포넌트 라이브러리를 모노레포 환경에서 개발하고 있는데요. 어떻게 하면 모노레포를 조금 더 잘 활용할 수 있을까 고민하던 중에 Turborepo를 만나게 되었습니다. 이번 글에서는 Turborepo가 무엇인지와 Turborepo를 적용하면서 어떤 이점이 있었는지 다뤄보려고 합니다.
글은 다음과 같은 순서로 진행하겠습니다.
Turborepo 이해하기
Turborepo를 설명하기 전에, Turborepo의 베이스인 모노레포에 대해 먼저 간단하게 말씀드리겠습니다.
모노레포란?
모노레포는 단일 리포지터리에 여러 개의 서브 프로젝트가 존재하는 방식입니다.

최초의 모놀리식 방식은 소스 코드를 모듈화하지 않고 하나의 리포지터리에 모두 넣었다고 생각하시면 됩니다. 모든 코드가 단일 버전으로 서로 직접 의존하기 때문에 코드 재사용이 용이하고 빌드 및 배포 과정도 단순하지만, 관심 분리가 어렵고 기능 추가나 삭제가 리포지터리 전체에 영향을 줄 수 있다는 단점이 있습니다. 이런 단점을 해결하고자 멀티레포 방식이 등장했습니다. 멀티 레포 방식에서는 소스 코드를 모듈화한 뒤 각 모듈에 독자적인 영역을 부여하고 버전 관리를 통해 관심을 분리해서 기능 변경이 다른 리포지터리에 직접 영향을 미치지 않도록 개선했습니다. 하지만 각 모듈이 서로 독립된 영역에 존재하기 때문에 코드 단계에서의 재사용이 어려워졌고 빌드와 배포 과정이 복잡해졌습니다.
모노레포는 이와 같은 모놀리식 리포지터리와 멀티레포의 장점을 모두 취하고자 등장했습니다. 모노레포의 장점은 아래와 같습니다.
- Visibility
- 리포지터리가 하나이기 때문에 모든 프로젝트의 코드와 자원(assets) 간의 관계와 의존성을 한눈에 확인할 수 있습니다.
- Collaboration
- 모든 커밋 히스토리가 한 리포지터리에 남기 때문에 히스토리를 추적하거나 전체 리포지터리의 개발 방향을 이해하는 게 쉬워집니다.
- 여러 곳에서 중복으로 사용하는 자산들(테스트 코드 등)을 공유하고 재사용할 수 있습니다.
- Speed
- 배포와 빌드, 테스트와 같은 작업을 병렬로 한 번에 처리할 수 있으므로 한 번의 명령으로 여러 개의 리포지터리에서 작업을 진행할 수 있습니다.
모노레포의 이점이 더 궁금하신 분들은 Why Google Stores Billions of Lines of Code in a Single Repository를 참고하시기 바랍니다.
Turborepo란?
Vercel이 인수(참고)한 Turborepo는 JavaScript와 TypeScript 코드 베이스의 모노레포를 위한 고성능 빌드 시스템입니다. Vercel과 AWS, Miro, PayPal, Discord, LINE+의 Universal Video Player 등 여러 프로젝트에서 프로덕션 단계로 사용하고 있으며(참고), 지금도 활발하게 개발이 진행되고 있습니다.

Turborepo의 주요 미션은 모노레포 환경에서 개발자가 조금 더 쉽고 빠르게 개발할 수 있도록 빌드 도구를 제공하는 것입니다. 고급 빌드 시스템을 구축하는 복잡한 과정을 Turborepo가 대신해 주기 때문에 개발자는 복잡한 설정과 스크립트에 신경 쓰는 대신 개발에 더 집중할 수 있습니다. Turborepo의 기본 원칙은 한 번 작업을 수행하며 수행한 계산은 이후 다시 수행하지 않는 것입니다. 따라서 두 번째 실행할 때는 이전에 계산한 작업은 건너뛰고 이전에 캐싱해 놓은 로그를 다시 보여줍니다.
Turborepo의 특징
Turborepo는 아래 9가지 특징을 기반으로 Turborepo를 사용해야 하는 이유를 설명합니다.

- Incremental builds
- 작업 진행을 캐싱해 이미 계산된 내용은 건너 뛰는 것을 의미합니다. 빌드는 딱 한 번만 하는 것을 목표로 합니다.

- 작업 진행을 캐싱해 이미 계산된 내용은 건너 뛰는 것을 의미합니다. 빌드는 딱 한 번만 하는 것을 목표로 합니다.
- Content-aware hasing
- 타임스탬프가 아닌 콘텐츠를 인식하는 방식으로 해싱을 지원합니다. 이를 통해 모든 파일을 다시 빌드하는 것이 아니라 변경된 파일만 빌드합니다.
- Cloud caching
- 클라우드 빌드 캐시를 팀원 및 CI/CD와 공유합니다. 이를 통해 로컬 환경을 넘어 클라우드 환경에서도 빠른 빌드를 제공합니다.
- Parallel execution
- 모든 코어를 사용하는 병렬 실행을 목표로 합니다. 지정된 태스크 단위로 의존성을 판단해 최대한 병렬적으로 작업을 진행합니다.
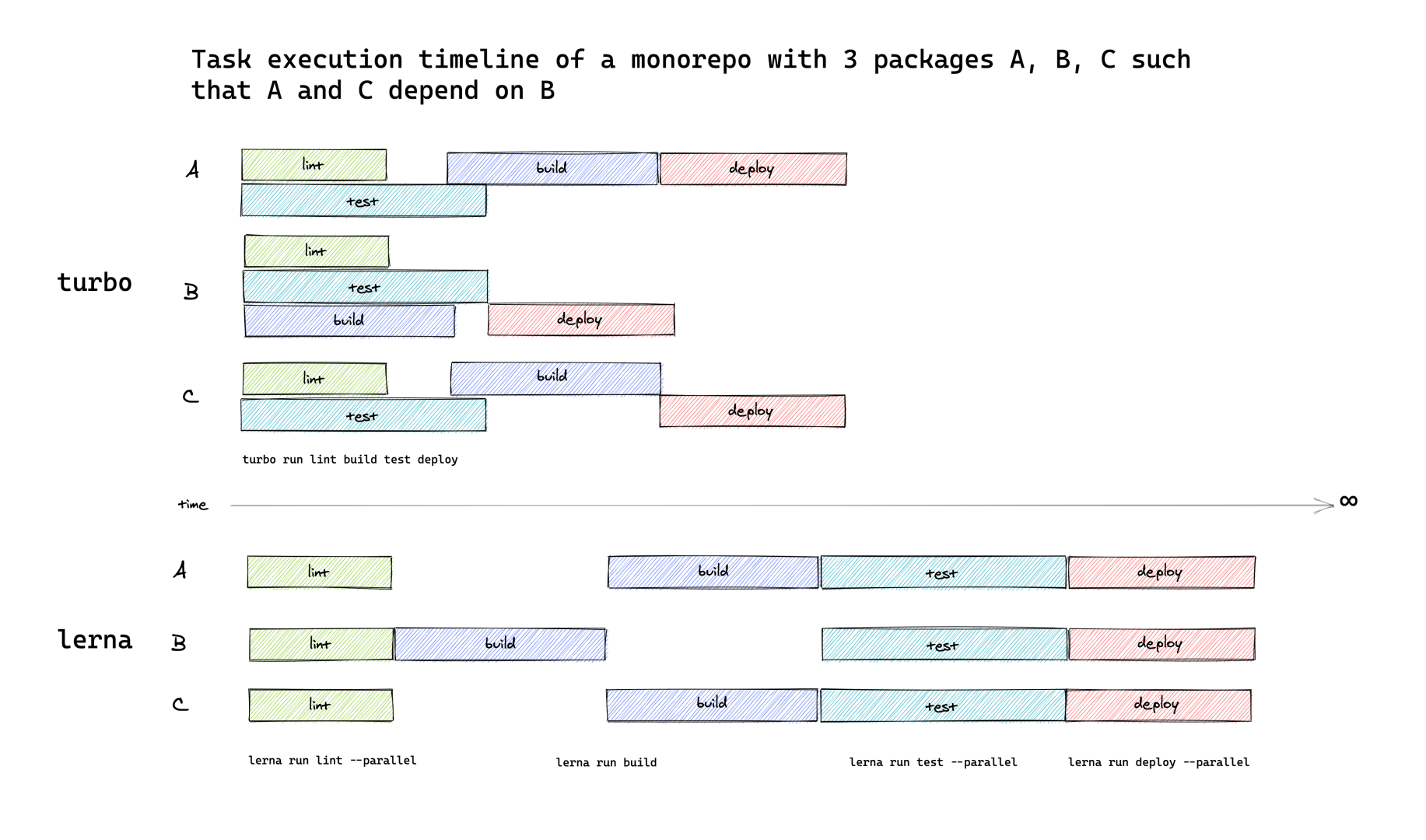
- 모든 코어를 사용하는 병렬 실행을 목표로 합니다. 지정된 태스크 단위로 의존성을 판단해 최대한 병렬적으로 작업을 진행합니다.
- Task Pipelines
- 태스크 간의 연결을 정의해서 빌드를 언제 어떻게 실행할지 판단해 최적화합니다.
- Zero Runtime Overhead
- 런타임 코드와 소스 맵을 다루지 않기 때문에 런타임 단계에서 파악하지 못한 리스크가 불거질 위험이 없습니다.
- Pruned subsets
- 빌드에 필요한 요소만으로 모노 레포의 하위 집합을 생성해 PaaS 배포 속도를 높입니다.
- JSON configuration
- 별도의 코드 작업 없이 JSON 설정으로 터보를 사용할 수 있습니다.
// turbo.json { "baseBranch": "origin/main", "pipeline": { "build": { ... } } }
- 별도의 코드 작업 없이 JSON 설정으로 터보를 사용할 수 있습니다.
- Profile in browser
- 빌드 프로필로 빌드 과정을 시각화하면 병목 지점을 쉽게 찾을 수 있습니다.

- 빌드 프로필로 빌드 과정을 시각화하면 병목 지점을 쉽게 찾을 수 있습니다.
간단한 사용법
모노레포의 루트 디렉터리에 turbo.json 파일을 생성한 후 파이프라인(pipeline)을 작성합니다. 파이프라인의 각 명령어들은 하나의 태스크 단위이며 이 단위가 '병렬 처리 및 의존성의 범위'가 됩니다.
{
"baseBranch": "origin/main",
"pipeline": {
"build": {
// ^는 커맨드 실행 전 dependencies 혹은 devDependencies의 위상 의존성을 가질 때 명시해 줍니다(https://turborepo.org/docs/glossary#topological-order).
// 의존성 빌드 명령이 실행된 후 build 커맨드가 실행됩니다.
"dependsOn": [
"^build"
],
// 기본 캐시 폴더를 지정합니다.
"outputs": [
".next/**",
"lib/**",
"storybook-static/**"
]
},
"cypress:ci": {
"dependsOn": [
// 특정 패키지를 지정하고 싶다면 '패키지명#스크립트'로 하면 됩니다.
"@linecorp/uvp#build"
]
},
// 아무런 명시가 없다면 의존성이 없다는 것을 의미하며, 이는 언제든지 실행될 수 있다는 것을 의미합니다.
// 작업이 가능할 때마다 실행합니다.
"lint": {},
"deploy": {
// 의존성을 여러 개 지정할 경우 터보가 똑똑하게 순서를 맞춰서 진행해 줍니다. 위 'Profile in browser'의 이미지를 참고해 주세요.
"dependsOn": [
"build",
"cypress:ci",
"snapshots",
"lint"
]
},
// 개발 환경과 같이 핫 로딩이 필요할 경우 캐시를 비활성화할 수 있습니다.
"dev": {
"cache": false
}
}
}JSON 파일을 생성했다면 이제 아래와 같이 Turborepo를 설치합니다.
$ yarn add turbo -DW # devDependency, install workspace root
$ turbo run build # yarn uvp build, yarn storybook build 등 의존성을 가진 모든 package 스크립트가 실행됩니다.파이프라인의 키 명령어들은 각 모노레포의 package.json 스크립트와 매핑됩니다. 만약 패키지 스크립트에 없는 명령어라면 해당 모노레포에서는 무시됩니다(예: A 패키지에는 린트(lint) 스크립트가 있지만 B 패키지에는 린트 스크립트가 없다면 A 패키지만 실행됩니다).
위와 같이 CLI로 설치해도 되고, 아래와 같이 최상위 package.json 파일에서 명령을 실행할 수도 있습니다.
"scripts": {
"build": "turbo run build",
}Real world! Turborepo 적용기
이제 UVP 프로젝트에서 어떻게 Turborepo를 적용했는지 공유해 보려고 합니다. UVP는 아래와 같은 형태의 모노레포로 구성되어 있습니다.
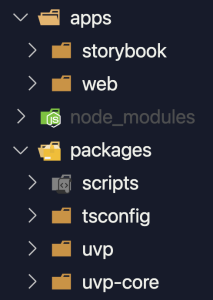
동영상의 기본적인 기능들로 구성된 uvp-core 패키지와 이 패키지를 래핑하고 있는 UI 컴포넌트인 uvp 패키지가 존재합니다. uvp 라이브러리를 사용하는 개발자를 위한 데모 웹과 스토리북은 apps 폴더 내부에 각각 패키지로 존재합니다. 모든 패키지에서 공통적으로 사용하는 스크립트(Babel, ESLint 등)와 타입스크립트 설정도 각각 패키지로 묶었습니다. 이를 통해 관리 포인트를 한곳으로 모았습니다.
Turborepo를 사용해 해결하고자 한 이슈들
스크립트 의존성 분리
Storybook 패키지를 배포하기 위해선 아래와 같이 린트와 테스트(Cypress, snapshost)를 포함해 uvp-core 및 uvp 패키지 빌드를 거쳐야 합니다.
"deploy:storybook": "yarn lint && yarn uvp-core build && yarn uvp build && yarn storybook build && yarn test && yarn storybook deploy"
이와 같은 방식은 스크립트를 작성하고 유지 보수하는 데 어려움 있습니다. 만약 사용하는 각 스크립트 내부에 또 다른 의존성이 있을 경우 복잡도가 훨씬 커집니다. 이에 Turborepo에 의존성 관리를 위임하고 Turborepo가 기본적으로 제공하는 병렬 처리를 이용해 개발 속도를 높이고자 했습니다.
반복되는 빌드 회피
배포 전 최종 테스트 과정에서 오류가 발생한다면 어떻게 될까요? 다시 lint -> build -> test 과정을 거쳐야 합니다. 이는 상당히 지루한 과정입니다. 이에 배포뿐 아니라 개발 과정에서 반복되는 빌드도 막고자 했습니다. 스토리북과 데모 웹 패키지는 모두 uvp 빌드에 의존하는데요. 만약 어느 한쪽에서 uvp를 빌드했다면 다른 쪽에서 스크립트를 다시 실행할 때 빌드되지 않기를 원했습니다. 이를 Turborepo의 캐싱 작업을 통해 막고자 했습니다.
배포 프로세스의 시각화
UVP는 라이브러리에 해당하고 이를 사용하는 사이트가 별개의 패키지로 존재하고 있습니다. 또한 향후 플러그인 형태로 uvp를 확장할 수 있도록 개발할 예정이어서 uvp를 활용한 여러 패키지가 생겨날 운명이었습니다. 이는 각 패키지의 의존성과 배포 진행 과정을 숙지하고 있어야 한다는 의미이기도 한데요. 이런 상황에서 uvp에 신규 인원이 참여하게 된다면 어떻게 될까요? 긴 배포 스크립트를 읽으며 패키지 간 의존성을 이해하기 위해 많은 노력을 기울여야 할 것입니다. 이에 Turborepo의 프로파일과 그래프 기능을 활용해 스크립트 간 의존성과 배포 과정을 시각화하고자 했습니다.
해결 과정
1. 각 package.json의 종속 분리
복잡하게 이어져있던 스크립트 의존성을 모두 분리합니다. 전처리 과정(예: lint && build && deploy)을 제거하고 순수하게 그 작업에 해당하는 스크립트로만 구성합니다. 의존성은 Turborepo에 작성합니다. 물론 자바스크립트 파일이나 스크립트 커맨드를 적절하게 사용해 의존성을 분리할 수도 있지만, Turborepo를 사용하면 복잡한 스크립트 관리를 모두 위임할 수 있습니다.
// before 예:
"scripts": {
"deploy:storybook": "yarn lint && yarn uvp-core build && yarn uvp build && yarn storybook build && yarn test && yarn storybook deploy"
}
// after 예:
"scripts": {
"deploy:storybook": "turbo run deploy --scope='storybook'"
}2. turbo.json에 각 태스크의 의존성과 설정을 작성해 파이프라인을 구성합니다.
{
"baseBranch": "origin/main",
"pipeline": {
// 스크립트와 매핑되는 태스크 이름을 작성합니다.
"build": {
// 의존성 빌드 명령이 실행된 후 build 커맨드가 실행됩니다.
"dependsOn": ["^build"],
// 기본 캐시 폴더를 지정합니다.
"outputs": [".next/**", "lib/**", "storybook-static/**"]
},
"snapshots": {
"dependsOn": ["@linecorp/uvp#build"]
},
"lint": {},
"deploy": {
// 의존성을 여러 개 지정할 경우 터보가 똑똑하게 순서를 맞춰서 진행합니다.
"dependsOn": ["build", "cypress:ci", "snapshots", "lint"]
},
"profile": {
"dependsOn": ["deploy"]
},
"dev": {
"dependsOn": ["@linecorp/uvp#build"],
"cache": false
},
"clean": {
"cache": false
}
}
}3. 최상위 package.json에서 아래와 같이 Turborepo 명령어를 적절하게 조합합니다.
// package.json
"scripts": {
"snapshot": "turbo run snapshots",
"build": "turbo run build",
// --scope는 build를 실행할 패키지 범위를 지정합니다. --no-deps와 --include-dependencies를 함께 사용하면 해당 스크립트에 필요한 의존성과 함께 실행합니다.
"build-uvp": "turbo run build --scope='@linecorp/uvp' --no-deps --include-dependencies",
// 이와 같이 run 다음에 태스크를 나열하면 각 작업의 우선순위에 따라 터보가 자동으로 정렬해 실행합니다.
"test": "turbo run build lint cypress:ci snapshots",
// --force 옵션을 넣으면 캐시된 작업을 다시 실행합니다. --profile, --graph 옵션은 아래에서 다시 다루겠습니다.
"profile": "turbo run profile --profile --force && turbo run profile --graph",
"clean": "turbo run clean && rm -rf node_modules"
}별도의 코드 작업 없이 package.json과 turbo.json를 변경하는 것만으로 Turborepo 설정을 모두 완료했습니다. 이제 스크립트 의존성은 Turborepo에서 '태스크 단위로 관리'하며 '실행 순서를 자동으로 위상 정렬'해서 '병렬 처리를 최대한 활용'해 빌드 스크립트를 실행합니다. 이 과정에서 중복되는 빌드와 스크립트 작업들은 '캐시로 처리'해 건너뜁니다.
결과
의존성 분리
특정 작업을 진행하기 위해 전처리해야 했던 과정을 Turborepo에 위임해서 package.json에 복잡하게 얽혀 있던 스크립트간 의존성을 모두 해소할 수 있었습니다.
// before
"build:storybook": "yarn lint && yarn uvp-core build && yarn uvp build && build-storybook"
// after
"build:storybook": "build-storybook"빌드 캐시
기존의 단순 모노레포 구조에서는 모든 스크립트에서 매번 처음부터 다시 빌드했기 때문에 중복되는 빌드가 많았습니다. 하지만 Turborepo를 통해 중복되는 작업을 모두 캐시로 처리하면서 작업 속도가 크게 빨라졌습니다. 6개 패키지의 13가지 태스크에 종속적인 배포 작업을 '다시' 실행했을 때, 이전 산출물이 100% 캐시로 활용되면서 7분 걸리던 작업이 0.64초 만에 완료됐습니다. 만약 특정 태스크에서 오류가 발생한다고 하더라도 해당 작업 이전까지는 캐시 처리되기 때문에 훨씬 빠르게 작업을 진행할 수 있습니다.
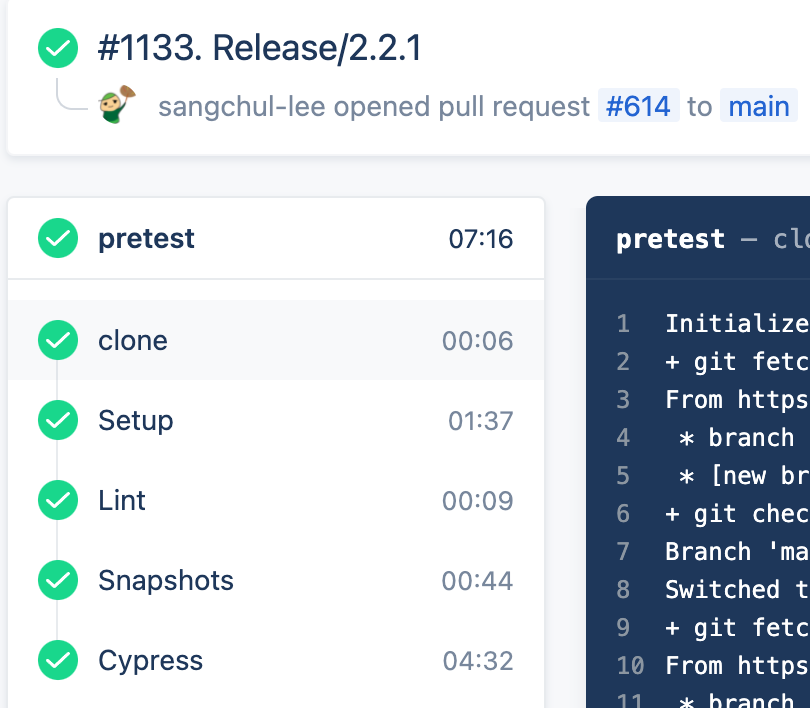

스크립트의 시각화
--graph와 --profile CLI(참고)를 이용하면 빌드 과정의 흐름과 소요 시간을 쉽게 확인할 수 있습니다.
먼저 아래와 같이 --graph 옵션으로 태스크를 실행하면 파이프라인에서 지정한 태스크의 관계를 그래프로 표현해 이미지 파일로 제공합니다.
$ turbo run TASK --graph아래는 결과 그래프에서 build 태스크 부분을 확대한 이미지입니다.
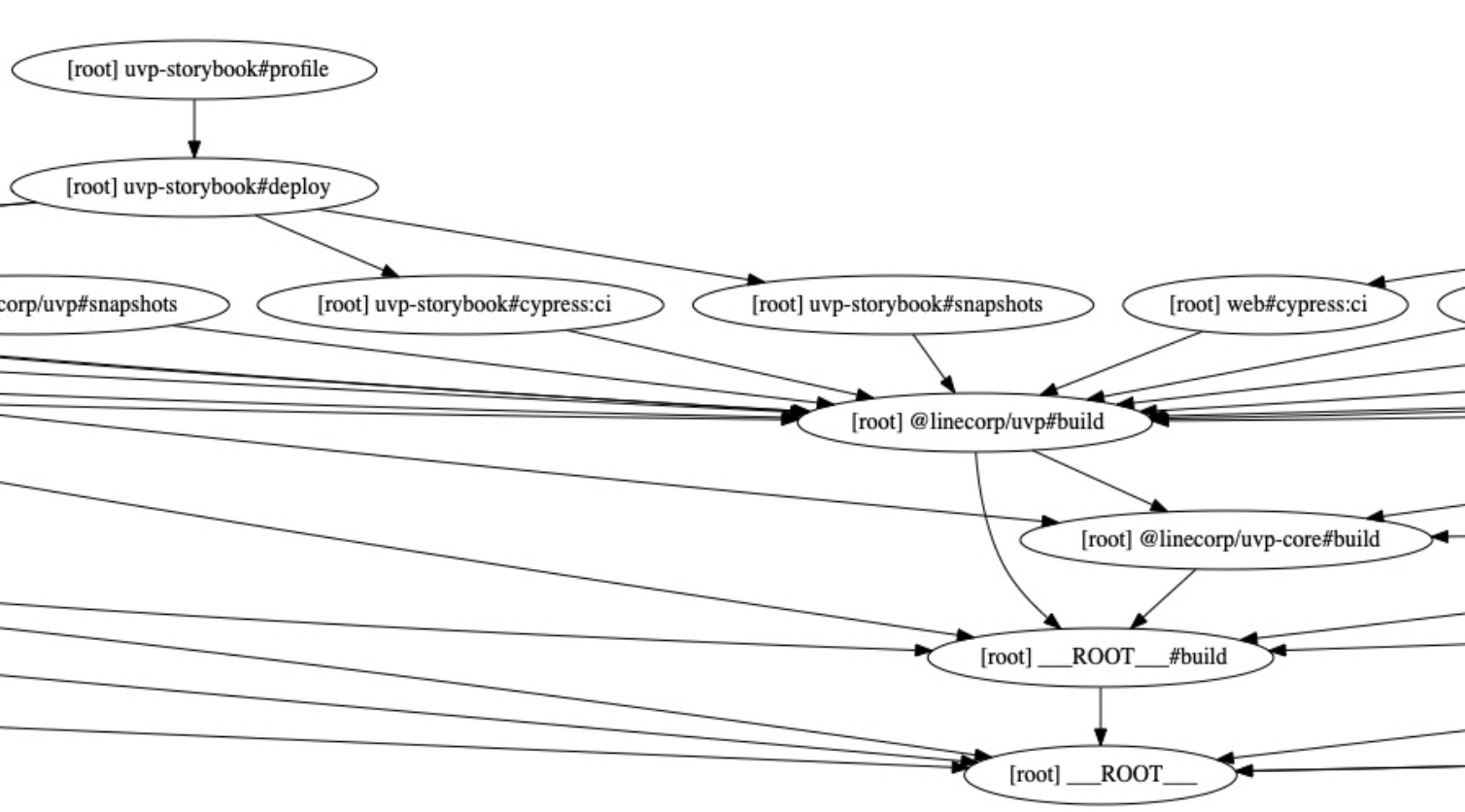
uvp는 uvp-core에 의존하고 있으며, 이후 각 패키지에서 uvp 빌드를 사용하는 것을 확인할 수 있습니다. 또한 각 패키지를 배포하는 과정에서 어떤 테스트 스크립트를 거치는지도 확인할 수 있는데요. 이를 통해 스크립트 간 순서와 실행되는 작업을 한눈에 이해할 수 있습니다. 이는 프로젝트를 이해하고 유지 보수하는 데 큰 도움이 됩니다(참고로 이 옵션을 사용하려면 graphviz를 설치해야 합니다).
다음으로 --profile 옵션을 사용하면 빌드가 어떤 식으로 진행됐고 어디가 병렬로 처리됐는지, 시간은 얼마나 걸렸는지 프로파일이 작성된 JSON 파일이 생성됩니다.
$ turbo run TASK --profile
이 파일은 Chrome 개발자 도구의 Performance 탭에서 확인할 수 있습니다. Performance 탭에서 아래 표시한 화살표 버튼을 클릭한 후 생성된 JSON 파일을 선택하면 시각화된 프로파일 정보를 확인할 수 있습니다.

아래와 같이 브라우저에서 시각화한 프로파일 정보를 살펴보면 빌드 과정을 쉽게 파악할 수 있고 태스크의 병목 지점을 빠르게 찾을 수 있습니다.

마무리
Turborepo를 도입해서 UVP 프로젝트의 빌드를 시각화하고 캐시를 적용하는 등 개발자 경험을 상당히 높일 수 있었습니다. 또한 복잡한 빌드 툴 설정과 서드파티 작업이 없다는 점도 큰 매력으로 다가왔습니다. 다만 한 가지 아쉬웠던 점은 아직 Turborepo에서 Yarn2의 PnP(Plug n Play) 기능을 지원하지 않아서 사용해 볼 수 없었다는 것인데요(참고). 현재 개발이 활발하게 진행되고 있으므로 조금 더 기다려보면 좋을 것 같습니다(참고). 이 글을 읽고 Turborepo에 관심이 생겼다면 Why TurboRepo Will Be The First Big Trend of 2022도 읽어보시는 것을 추천드리겠습니다.
제 글은 여기까지입니다. 긴 글 읽어주셔서 감사합니다. 지금 모노레포를 운영하고 있다면 Turborepo 적용을 고려해 보시는 건 어떨까요?