LINEの開発組織のそれぞれの部門やプロジェクトについて、その役割や体制、技術スタック、今後の課題やロードマップなどを具体的に紹介していく「Team & Project」シリーズ。今回は、LINEの提供するAI関連のソリューションやプロダクトに実装されている、音声認識技術の開発を担当しているチームを紹介します。
Speechチームの木田祐介、坂本渚、芦川博人に話を聞きました。

まず、自己紹介をお願いします。
木田:AIカンパニーにて音声認識技術の開発を行っているSpeechチームのマネージャーをしています。1年ほど前にエンジニアとしてSpeechチームにジョインして、今年の1月からマネージャーを務めています。
坂本:Speechチームの坂本です。3年前に入社して、現在は主にプロダクト向けの音声認識モデル(NSpeech)の開発・運用を行うチームで働いています。
芦川:Speechチームの芦川です。2年前に新卒としてLINEに入社しました。学生時代は音声言語処理・対話システムに関する研究に従事していました。現在はディープニューラルネットワークを用いたEnd-to-end音声認識システム(NEST)の技術開発をしています。
―― みなさんがLINEに入った理由を教えてください。
木田: 私はLINEが3社目なんですが、これまでずっと音声関係の研究開発に携わってきました。LINEがスマートスピーカーやLINE AiCallなど、音声認識を使ったプロダクトを次々と打ち出しているのを傍目で見ていて「すごい勢いのある会社だな」と思っていました。前職に大きな不満はなかったんですが、「今このタイミングでLINEで働くのは絶対に自分の財産になる」と思って、転職を決意しました。
坂本:LINEがスマートスピーカーを日本で最初にリリースしたのを知って、その勢いとスピード感に惹かれました。前職でも音声認識モデルの開発に携わっていたのですが、ユーザーやサービスから遠い立ち位置で働いていたため、もっと近い立ち位置で貢献したいと思ったのも理由のひとつです。
芦川:私はLINEに内定をいただいた後、内定者インターンをしていました。その期間中、LINEは各領域にすごい人がたくさんいて、エンジニアとしての自分のキャリアパスを考えた上で素晴らしい成長環境だと感じました。また、LINEは新規プロダクトにどんどん挑戦していく会社ですし、ユーザーも多いので自分が開発したプロダクトで人々の生活に良いインパクトを与えられたらいいなと思い、入社を決めました。

―― LINEで働くやりがいを教えてください。
木田: 自分の頑張りが周りに大きな影響を与えられる、エンジニアとしてとても良い環境だと思います。入社した直後、マネージャーとの「こんなもの作ったら面白いよね」という会話を受けて、芦川さんと一緒に試行錯誤しながら、2週間程度でプロトタイプシステムを開発し、部内でデモをしました。その結果、ブラッシュアップしたシステムが「LINE DEVELOPER DAY 2020」という大きなカンファレンスで紹介されたのは嬉しかったです。
また、LINEは状況の変化がとても早い会社なので、マネージャーとしてその変化にチームをどう対応させていくかを考えるのが面白いですね。大変ではあるのですが。
坂本:自分が作ったモデルがすぐにサービスに反映されて、フィードバックを得られるのはすごく面白いです。例えば、LINE AiCallというサービスに音声認識モデルを提供していますが、今まで認識出来なかった建物の名前が、モデルのアップデートによって認識出来るようになったのが、期待通りの効果でうれしかったです。LINE AiCall以外にも、音声認識のモデルが適応されているサービスはたくさんあり、やることは盛りだくさんです。またチームメンバーに音声認識のプロフェッショナルが多く、いろいろな意見をもらえるので、日々刺激をもらっています。
芦川:機械学習の研究開発では、「できなかったことをできるようにする」ところに大きなやりがいを感じます。難しい問題を解いていると、初めは全然性能が出なかったりするのですが、どうやったらよいかあれこれ考えて、上手くいった時はテンションが上がりますね。また、私たちは技術開発の過程でプロトタイプやデモをよく作ります。そういったデモを発信すると、いろんな方が見てくれてフィードバックをくれたり、議論につながったりと、自分のやることが周囲にいい影響を及ぼしていることを実感し、やりがいに繋がっています。
―― チームの構成・役割などについて教えてください。
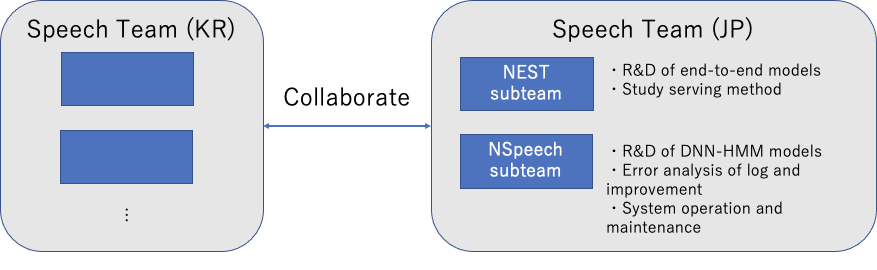
木田: コアとなる音声認識の技術は、韓国と日本と共同で開発しています。

日本側の組織であるSpeechチームは現在11名で構成されており、日本語の音声認識の開発にフォーカスしています。ふたつの音声認識エンジンの開発を行っており、担当するエンジンごとにサブチームがあります。
そのうちのひとつが、現在各プロダクトで使われている音声認識システム(NSpeech)の改善や運用を行うサブチームです。DNN-HMM (Deep Neural Network - Hidden Markov Model) と呼ばれる技術が使われているのですが、汎用的な音声認識精度の改善のほか、住所や電話番号などの「よく使われるドメイン」のラインナップを拡充させたり、モデリングやデプロイなど運用面の改善を行っています。
もう1つのサブチームでは、音声認識の分野で現在大きな注目を集めている「End-to-End音声認識」の開発(NEST)を行っています。こちらのチームは、プロダクト化に向けてモデルの学習や実装をメインで行なっていますが、技術の進化がすごく早いので、最先端の論文から筋の良さそうな技術を見つけて試すことも重要な役割です。
―― チームメンバーを紹介してください。
木田: 今いるメンバーは全員、大学や企業で、音声処理や言語処理の研究開発を経験しています。割合としては中途入社のメンバーがやや多く、年齢層は20代から40代まで幅広いです。
社外に名前の知られた人としては、この4月に入社された藤田雄介さんが代表的ですね。藤田さんはトップカンファレンスで度々論文発表されていて、先日開催された音声・音響分野で世界最大規模の国際会議であるICASSP2021でも、チュートリアル講演で登壇されました。
メンバーの所属オフィスは東京と京都に分かれていますが、現在ほとんどのメンバーが在宅で勤務しており、ロケーションが離れていることの影響を感じることはあまりありません。
対面で気軽に雑談する機会が失われているので、最近はオンラインで雑談会をやっています。登山やゴルフが好きなアウトドア派もいれば、音ゲーや麻雀が好きなインドア派もいて、メンバーのパーソナリティは様々ですね。
―― 利用技術・開発環境について教えてください。
芦川:ディープラーニングフレームワークとしては、PyTorchを用いることが多いです。
音声認識では、比較的大規模なニューラルネットワークモデルを学習することが多いのでGPUは必須ですね。NSMLという社内の機械学習用GPUクラスタや、チームで占有しているGPUサーバーを用いて学習をしています。GPUリソースに関しては割と潤沢な方だと思います。
大規模モデルの学習では、複数のGPUノードを用いた分散学習なども行っています。最近は、機械学習モデルをデプロイ・管理する上でKubernetesが相性がよかったりするので、こういった技術も積極的にとりいれています。
坂本:学習データとして利用するテキストはHDFS上で管理を行なっており、Sparkを利用してデータを処理して、学習を行なっています。また、一部のモデルはGPUを用いて学習されるものもあります。実際の運用では、ログの管理にElasticSearchを利用しています。プログラミング言語としては、PythonやC++を使ったコードが多いです。

―― 今のチーム課題と課題解決に向けた取り組みについて教えてください。
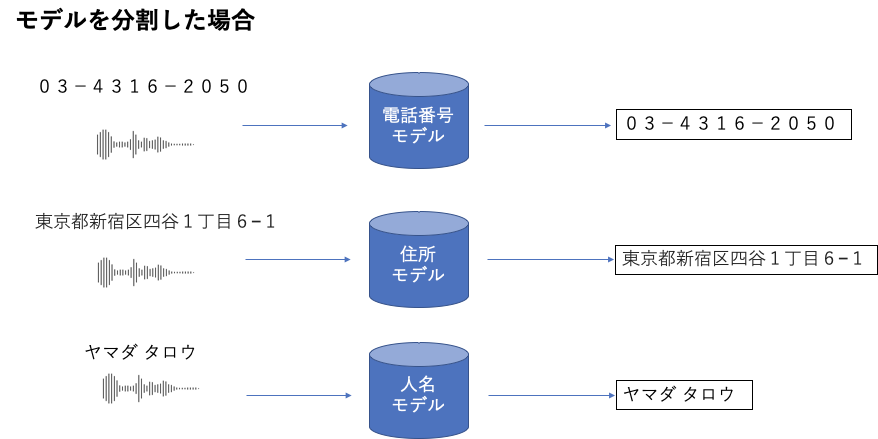
坂本:認識精度の観点で言うと、多様なドメインに対してひとつのモデルで対応するのは難しく、モデルが使えるシーンがまだまだ少ないという点です。その改善のために、使用するサービスに合わせて最適な学習データやパラメータ等を調整し、サービスに特化したモデリングを行っています。特に固有名詞に対しては、住所・人名・電話番号などそれぞれ専用モデルを用意し、そのモデリングを工夫することで改善を試みています。
運用の観点で言うと、現状はモデル開発および運用をどうしても人手でやらないといけない部分があり、サービスが増えるにつれて人手不足になっている点です。現在、人手コストを減らすためにモデル学習の自動化も計画しており、よりスピーディーかつ安全なモデリングを目指しています。
芦川:End-to-End音声認識は精度的には非常に良くなってきたのですが、実際にサービスに応用する上ではいくつかの課題が残っています。

まず、End-to-End音声認識は非常に大きなモデルを使うので、計算コストが課題となります。特に即時性が求められるアプリケーションでは重要な課題です。そのため認識精度の高さだけでなく、より小さな計算コストで動作することを考慮してモデルを開発する必要があります。
また、GPUを使った効率的なサービング方法を検討したり、CPUでも動くようにモデルサイズを小さくするなどの検討も行っています。
もう一つの課題は、カスタマイズの難しさです。
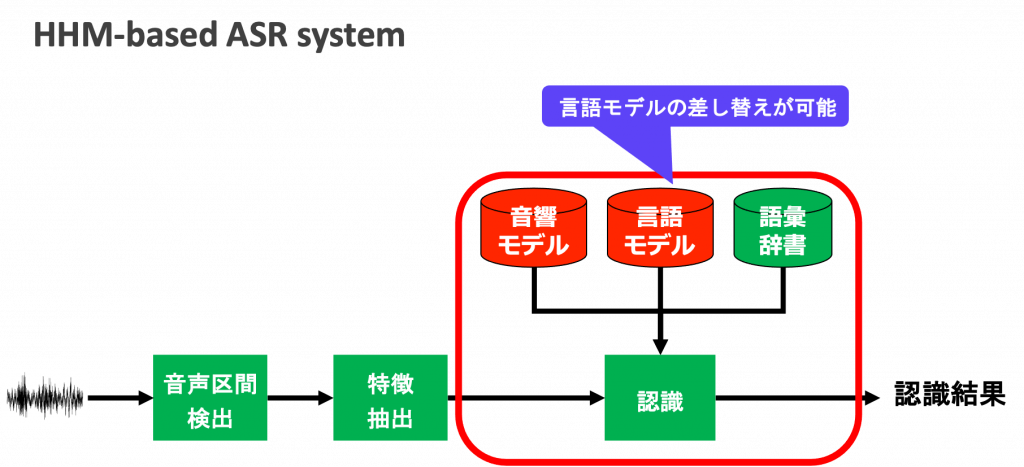
従来型(HMMベース)の音声認識では、音響モデルと言語モデルというモジュールを組み合わせて認識を行います。例えば、ある顧客の社内用語が認識できるようにカスタマイズを行う時は、言語モデルを顧客専用のものに差し替えることで対応できます。
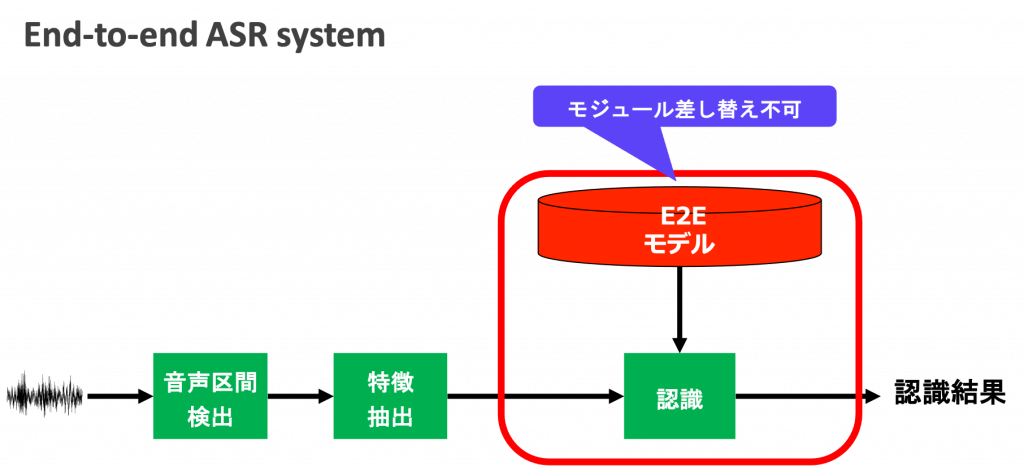
一方、End-to-End音声認識では、音響モデルと言語モデルの役割を一つのモデルで担っているため、モジュールの差し替えでカスタマイズを行うことができません。そのため、End-to-End音声認識でカスタマイズを行うために有効な方法を模索して、実装や評価を行う研究開発を行っています。
―― 今後のロードマップを教えてください。
木田: 短期的なチームのミッションは、LINE AiCallなど既存プロダクトの完成度を高めてLINEのビジネスに貢献すること、End-to-End音声認識をリリースして最新の技術をいち早く導入するサイクルを回すことです。
また我々のチームでは、プロトタイプを作ることを重視しています。尖ったプロダクトは技術の特性を一番理解しているエンジニアの知的好奇心から生まれる、という想いがあるからです。我々のプロトタイプが種となり、新しいプロダクトをどんどん創出できるようになる、そういうチーム作りを目指していきたいです。
LINEには優秀なリサーチャーもいますので、彼らとのコラボレーションもどんどん進めていきたいと考えています。
―― 最後に、Speechチームに興味を持ってくれた人にメッセージをお願いします。
芦川:音声認識のプロダクトには、難しいけど重要な課題がたくさんあります。一緒に挑戦して世の中にWOWを届けましょう!
木田: LINEの音声認識はまだまだ発展途上で、課題には事欠きません。今後も挑戦的なプロダクトをどんどん世の中に出していきたいと思っていますので、意欲ある方のエントリーをお待ちしています。
坂本:自分の作ったモデルが大きなサービスに反映されるのは、すごくやりがいがある仕事です。ぜひ一緒にプロダクトづくりをしましょう!